 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital me ontology and ethics
Dec 22, 2020This paper addresses ontology and ethics of an AI agent called digital me. We define digital me as autonomous, decision-making, and learning agent, representing an individual and having practically immortal own life. It is assumed that digital me is equipped with the big-five personality model, ensuring that it provides a model of some aspects of a strong AI: consciousness, free will, and intentionality. As computer-based personality judgments are more accurate than those made by humans, digital me can judge the personality of the individual represented by the digital me, other individuals' personalities, and other digital me-s. We describe seven ontological qualities of digital me: a) double-layer status of Digital Being versus digital me, b) digital me versus real me, c) mind-digital me and body-digital me, d) digital me versus doppelganger (shadow digital me), e) non-human time concept, f) social quality, g) practical immortality. We argue that with the advancement of AI's sciences and technologies, there exist two digital me thresholds. The first threshold defines digital me having some (rudimentarily) form of consciousness, free will, and intentionality. The second threshold assumes that digital me is equipped with moral learning capabilities, implying that, in principle, digital me could develop their own ethics which significantly differs from human's understanding of ethics. Finally we discuss the implications of digital me metaethics, normative and applied ethics, the implementation of the Golden Rule in digital me-s, and we suggest two sets of normative principles for digital me: consequentialist and duty based digital me principles.
Graphlets in Multiplex Networks
Nov 17, 2019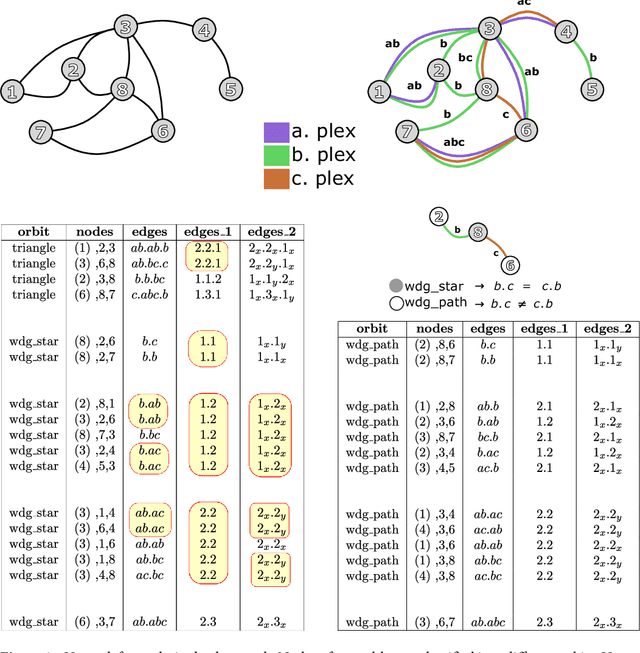
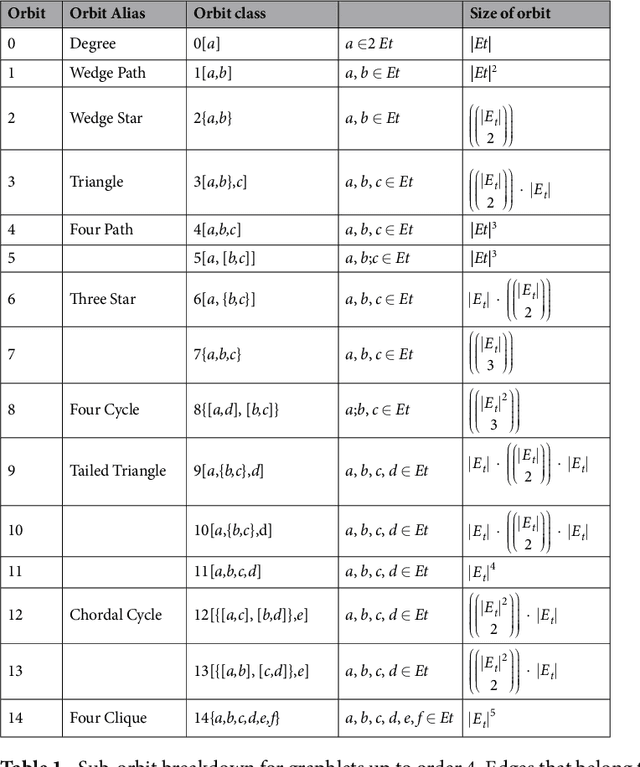

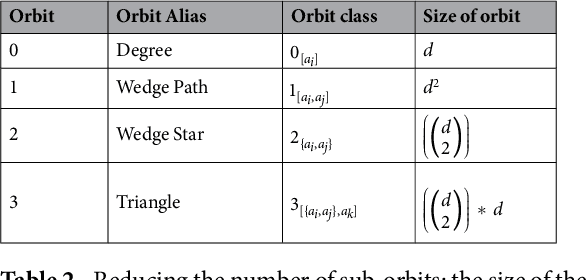
We develop graphlet analysis for multiplex networks and discuss how this analysis can be extended to multilayer and multilevel networks as well as to graphs with node and/or link categorical attributes. The analysis has been adapted for two typical examples of multiplexes: economic trade data represented as a 957-plex network and 75 social networks each represented as a 12-plex network. We show that wedges (open triads) occur more often in economic trade networks than in social networks, indicating the tendency of a country to produce/trade of a product in local structure of triads which are not closed. Moreover, our analysis provides evidence that the countries with small diversity tend to form correlated triangles. Wedges also appear in the social networks, however the dominant graphlets in social networks are triangles (closed triads). If a multiplex structure indicates a strong tie, the graphlet analysis provides another evidence for the concepts of strong/weak ties and structural holes. In contrast to Granovetter's seminal work on the strength of weak ties, in which it has been documented that the wedges with only strong ties are absent, here we show that for the analyzed 75 social networks, the wedges with only strong ties are not only present but also significantly correlated.
Stability of decision trees and logistic regression
Mar 03, 2019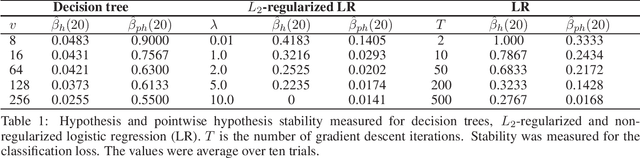
Decision trees and logistic regression are one of the most popular and well-known machine learning algorithms, frequently used to solve a variety of real-world problems. Stability of learning algorithms is a powerful tool to analyze their performance and sensitivity and subsequently allow researchers to draw reliable conclusions. The stability of these two algorithms has remained obscure. To that end, in this paper, we derive two stability notions for decision trees and logistic regression: hypothesis and pointwise hypothesis stability. Additionally, we derive these notions for L2-regularized logistic regression and confirm existing findings that it is uniformly stable. We show that the stability of decision trees depends on the number of leaves in the tree, i.e., its depth, while for logistic regression, it depends on the smallest eigenvalue of the Hessian matrix of the cross-entropy loss. We show that logistic regression is not a stable learning algorithm. We construct the upper bounds on the generalization error of all three algorithms. Moreover, we present a novel stability measuring framework that allows one to measure the aforementioned notions of stability. The measures are equivalent to estimates of expected loss differences at an input example and then leverage bootstrap sampling to yield statistically reliable estimates. Finally, we apply this framework to the three algorithms analyzed in this paper to confirm our theoretical findings and, in addition, we discuss the possibilities of developing new training techniques to optimize the stability of logistic regression, and hence decrease its generalization error.
Stacking and stability
Jan 26, 2019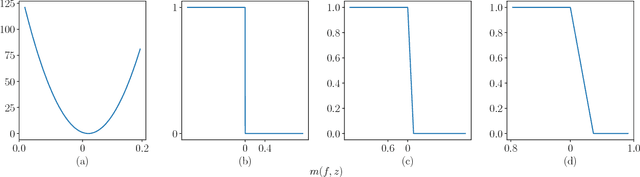
Stacking is a general approach for combining multiple models toward greater predictive accuracy. It has found various application across different domains, ensuing from its meta-learning nature. Our understanding, nevertheless, on how and why stacking works remains intuitive and lacking in theoretical insight. In this paper, we use the stability of learning algorithms as an elemental analysis framework suitable for addressing the issue. To this end, we analyze the hypothesis stability of stacking, bag-stacking, and dag-stacking and establish a connection between bag-stacking and weighted bagging. We show that the hypothesis stability of stacking is a product of the hypothesis stability of each of the base models and the combiner. Moreover, in bag-stacking and dag-stacking, the hypothesis stability depends on the sampling strategy used to generate the training set replicates. Our findings suggest that 1) subsampling and bootstrap sampling improve the stability of stacking, and 2) stacking improves the stability of both subbagging and bagging.
Sparse Three-parameter Restricted Indian Buffet Process for Understanding International Trade
Jun 29, 2018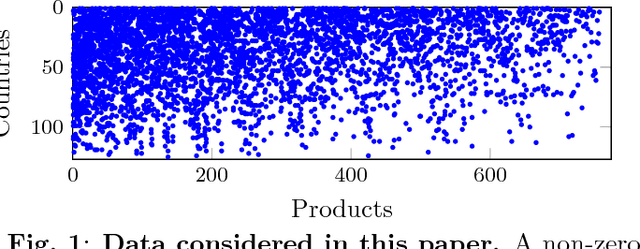
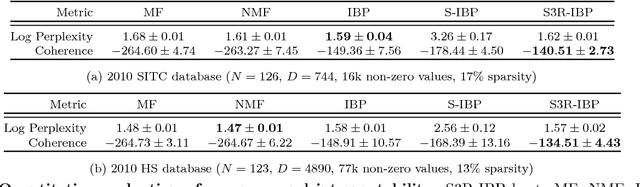
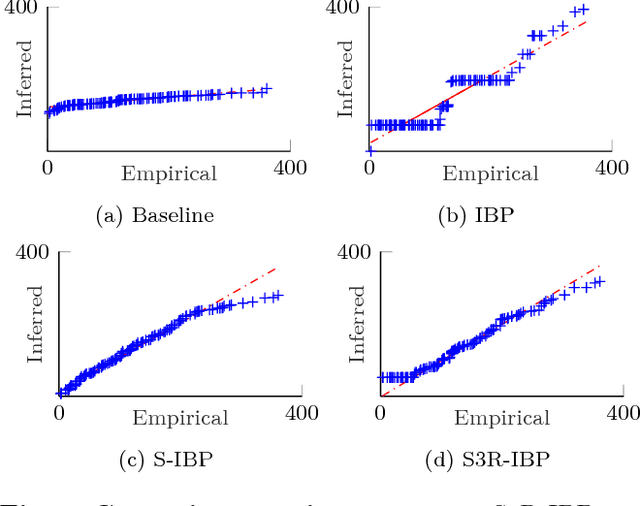

This paper presents a Bayesian nonparametric latent feature model specially suitable for exploratory analysis of high-dimensional count data. We perform a non-negative doubly sparse matrix factorization that has two main advantages: not only we are able to better approximate the row input distributions, but the inferred topics are also easier to interpret. By combining the three-parameter and restricted Indian buffet processes into a single prior, we increase the model flexibility, allowing for a full spectrum of sparse solutions in the latent space. We demonstrate the usefulness of our approach in the analysis of countries' economic structure. Compared to other approaches, empirical results show our model's ability to give easy-to-interpret information and better capture the underlying sparsity structure of data.
Opinion mining of text documents written in Macedonian language
Nov 17, 2014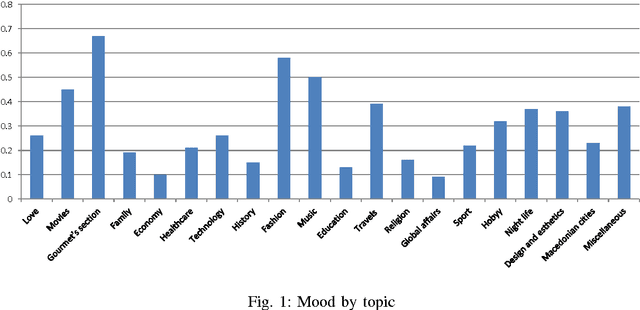
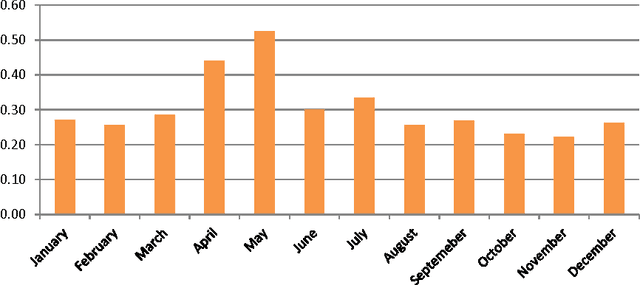


The ability to extract public opinion from web portals such as review sites, social networks and blogs will enable companies and individuals to form a view, an attitude and make decisions without having to do lengthy and costly researches and surveys. In this paper machine learning techniques are used for determining the polarity of forum posts on kajgana which are written in Macedonian language. The posts are classified as being positive, negative or neutral. We test different feature metrics and classifiers and provide detailed evaluation of their participation in improving the overall performance on a manually generated dataset. By achieving 92% accuracy, we show that the performance of systems for automated opinion mining is comparable to a human evaluator, thus making it a viable option for text data analysis. Finally, we present a few statistics derived from the forum posts using the developed system.