 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaypeople's Attitudes Towards Fair, Affirmative, and Discriminatory Decision-Making Algorithms
May 12, 2025Affirmative algorithms have emerged as a potential answer to algorithmic discrimination, seeking to redress past harms and rectify the source of historical injustices. We present the results of two experiments ($N$$=$$1193$) capturing laypeople's perceptions of affirmative algorithms -- those which explicitly prioritize the historically marginalized -- in hiring and criminal justice. We contrast these opinions about affirmative algorithms with folk attitudes towards algorithms that prioritize the privileged (i.e., discriminatory) and systems that make decisions independently of demographic groups (i.e., fair). We find that people -- regardless of their political leaning and identity -- view fair algorithms favorably and denounce discriminatory systems. In contrast, we identify disagreements concerning affirmative algorithms: liberals and racial minorities rate affirmative systems as positively as their fair counterparts, whereas conservatives and those from the dominant racial group evaluate affirmative algorithms as negatively as discriminatory systems. We identify a source of these divisions: people have varying beliefs about who (if anyone) is marginalized, shaping their views of affirmative algorithms. We discuss the possibility of bridging these disagreements to bring people together towards affirmative algorithms.
Blaming Humans and Machines: What Shapes People's Reactions to Algorithmic Harm
Apr 05, 2023
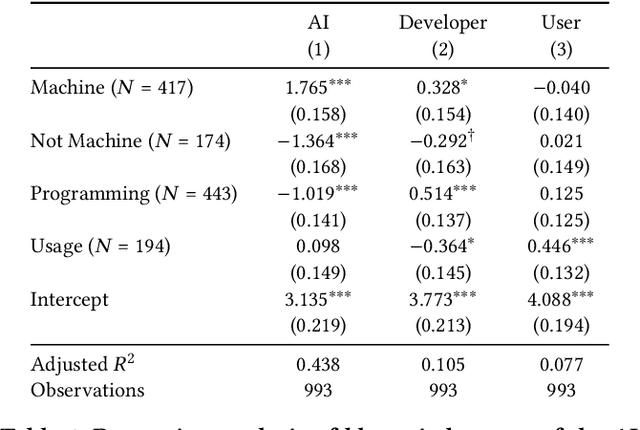
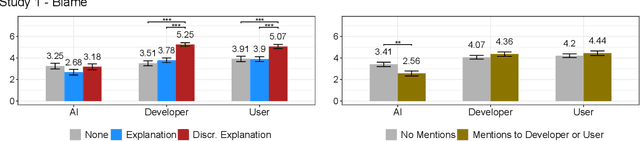
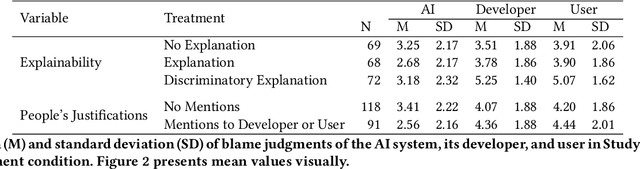
Artificial intelligence (AI) systems can cause harm to people. This research examines how individuals react to such harm through the lens of blame. Building upon research suggesting that people blame AI systems, we investigated how several factors influence people's reactive attitudes towards machines, designers, and users. The results of three studies (N = 1,153) indicate differences in how blame is attributed to these actors. Whether AI systems were explainable did not impact blame directed at them, their developers, and their users. Considerations about fairness and harmfulness increased blame towards designers and users but had little to no effect on judgments of AI systems. Instead, what determined people's reactive attitudes towards machines was whether people thought blaming them would be a suitable response to algorithmic harm. We discuss implications, such as how future decisions about including AI systems in the social and moral spheres will shape laypeople's reactions to AI-caused harm.
The Conflict Between Explainable and Accountable Decision-Making Algorithms
May 11, 2022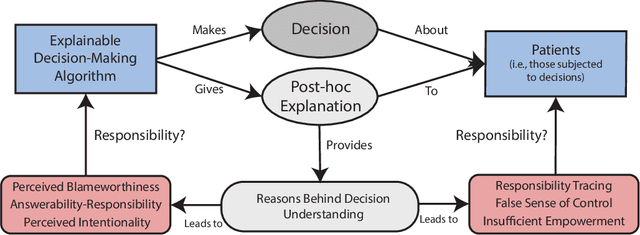
Decision-making algorithms are being used in important decisions, such as who should be enrolled in health care programs and be hired. Even though these systems are currently deployed in high-stakes scenarios, many of them cannot explain their decisions. This limitation has prompted the Explainable Artificial Intelligence (XAI) initiative, which aims to make algorithms explainable to comply with legal requirements, promote trust, and maintain accountability. This paper questions whether and to what extent explainability can help solve the responsibility issues posed by autonomous AI systems. We suggest that XAI systems that provide post-hoc explanations could be seen as blameworthy agents, obscuring the responsibility of developers in the decision-making process. Furthermore, we argue that XAI could result in incorrect attributions of responsibility to vulnerable stakeholders, such as those who are subjected to algorithmic decisions (i.e., patients), due to a misguided perception that they have control over explainable algorithms. This conflict between explainability and accountability can be exacerbated if designers choose to use algorithms and patients as moral and legal scapegoats. We conclude with a set of recommendations for how to approach this tension in the socio-technical process of algorithmic decision-making and a defense of hard regulation to prevent designers from escaping responsibility.
Human Perceptions on Moral Responsibility of AI: A Case Study in AI-Assisted Bail Decision-Making
Feb 01, 2021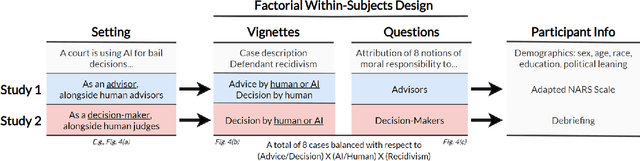
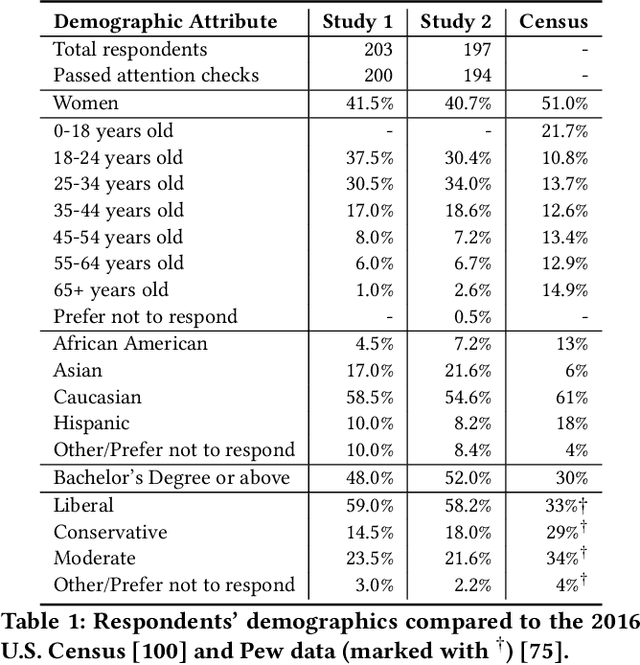
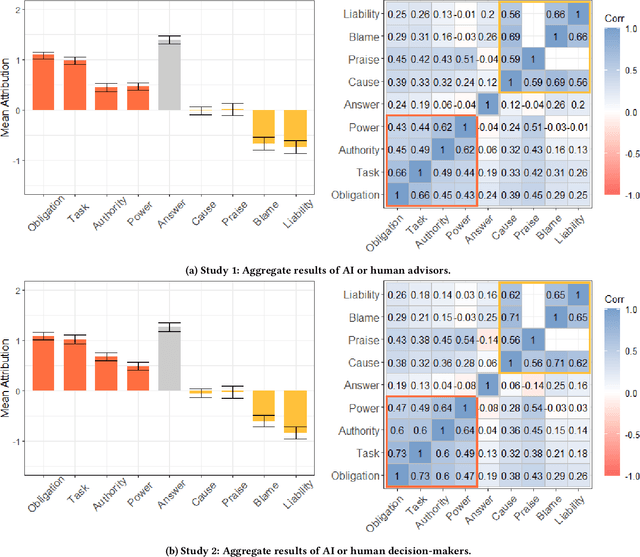
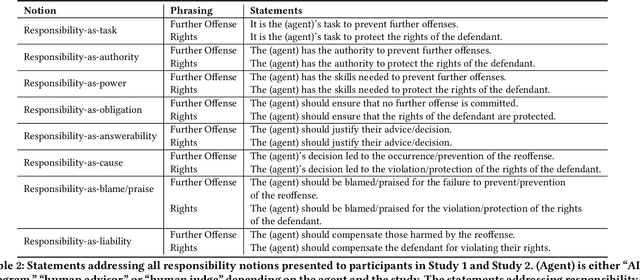
How to attribute responsibility for autonomous artificial intelligence (AI) systems' actions has been widely debated across the humanities and social science disciplines. This work presents two experiments ($N$=200 each) that measure people's perceptions of eight different notions of moral responsibility concerning AI and human agents in the context of bail decision-making. Using real-life adapted vignettes, our experiments show that AI agents are held causally responsible and blamed similarly to human agents for an identical task. However, there was a meaningful difference in how people perceived these agents' moral responsibility; human agents were ascribed to a higher degree of present-looking and forward-looking notions of responsibility than AI agents. We also found that people expect both AI and human decision-makers and advisors to justify their decisions regardless of their nature. We discuss policy and HCI implications of these findings, such as the need for explainable AI in high-stakes scenarios.
Dimensions of Diversity in Human Perceptions of Algorithmic Fairness
May 02, 2020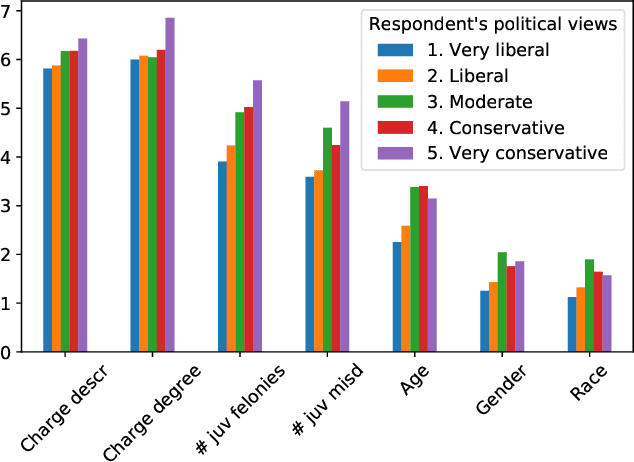
Algorithms are increasingly involved in making decisions that affect human lives. Prior work has explored how people believe algorithmic decisions should be made, but there is little understanding of which individual factors relate to variance in these beliefs across people. As an increasing emphasis is put on oversight boards and regulatory bodies, it is important to understand the biases that may affect human judgements about the fairness of algorithms. Building on factors found in moral foundations theory and egocentric fairness literature, we explore how people's perceptions of fairness relate to their (i) demographics (age, race, gender, political view), and (ii) personal experiences with the algorithmic task being evaluated. Specifically, we study human beliefs about the fairness of using different features in an algorithm designed to assist judges in making decisions about granting bail. Our analysis suggests that political views and certain demographic factors, such as age and gender, exhibit a significant relation to people's beliefs about fairness. Additionally, we find that people beliefs about the fairness of using demographic features such as age, gender and race, for making bail decisions about others, vary egocentrically: that is they vary depending on their own age, gender and race respectively.
Human Perceptions of Fairness in Algorithmic Decision Making: A Case Study of Criminal Risk Prediction
Feb 26, 2018
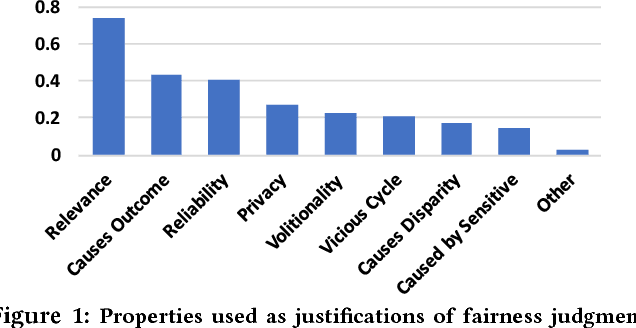
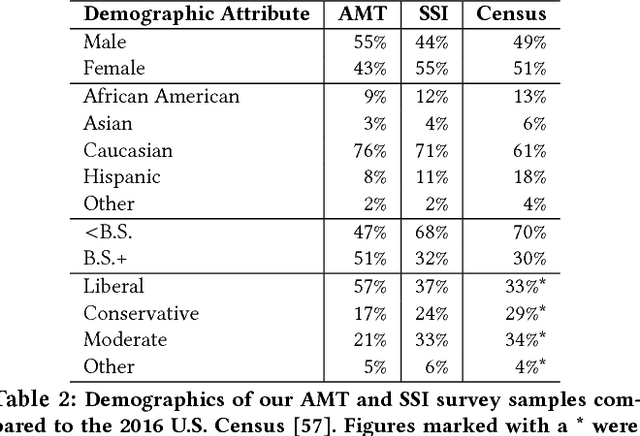
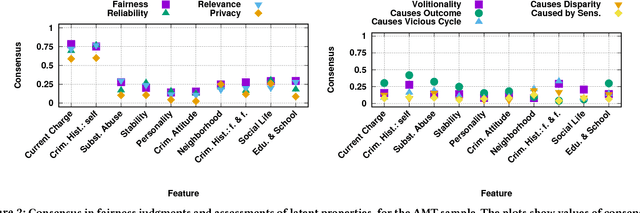
As algorithms are increasingly used to make important decisions that affect human lives, ranging from social benefit assignment to predicting risk of criminal recidivism, concerns have been raised about the fairness of algorithmic decision making. Most prior works on algorithmic fairness normatively prescribe how fair decisions ought to be made. In contrast, here, we descriptively survey users for how they perceive and reason about fairness in algorithmic decision making. A key contribution of this work is the framework we propose to understand why people perceive certain features as fair or unfair to be used in algorithms. Our framework identifies eight properties of features, such as relevance, volitionality and reliability, as latent considerations that inform people's moral judgments about the fairness of feature use in decision-making algorithms. We validate our framework through a series of scenario-based surveys with 576 people. We find that, based on a person's assessment of the eight latent properties of a feature in our exemplar scenario, we can accurately (> 85%) predict if the person will judge the use of the feature as fair. Our findings have important implications. At a high-level, we show that people's unfairness concerns are multi-dimensional and argue that future studies need to address unfairness concerns beyond discrimination. At a low-level, we find considerable disagreements in people's fairness judgments. We identify root causes of the disagreements, and note possible pathways to resolve them.
On Fairness, Diversity and Randomness in Algorithmic Decision Making
Jun 30, 2017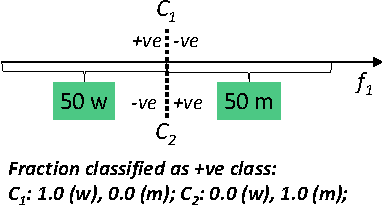
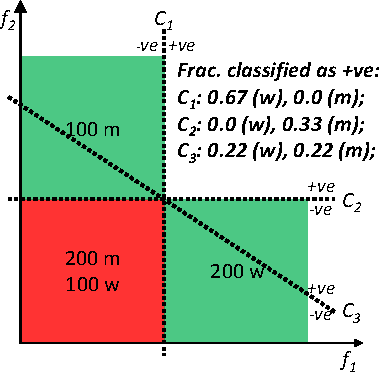
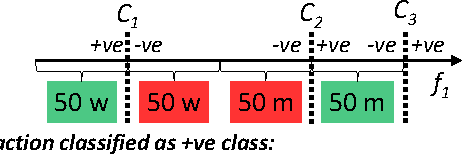
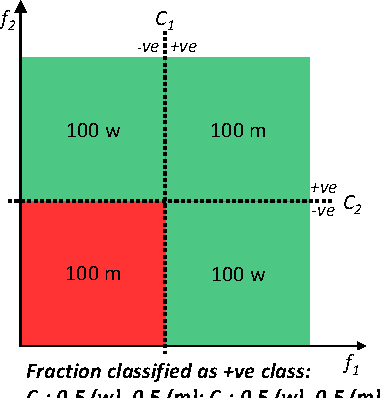
Consider a binary decision making process where a single machine learning classifier replaces a multitude of humans. We raise questions about the resulting loss of diversity in the decision making process. We study the potential benefits of using random classifier ensembles instead of a single classifier in the context of fairness-aware learning and demonstrate various attractive properties: (i) an ensemble of fair classifiers is guaranteed to be fair, for several different measures of fairness, (ii) an ensemble of unfair classifiers can still achieve fair outcomes, and (iii) an ensemble of classifiers can achieve better accuracy-fairness trade-offs than a single classifier. Finally, we introduce notions of distributional fairness to characterize further potential benefits of random classifier ensembles.