 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpComm: A Reinforcement Learning Framework for Adaptive Buffer Control in Warehouse Volume Forecasting
Dec 17, 2025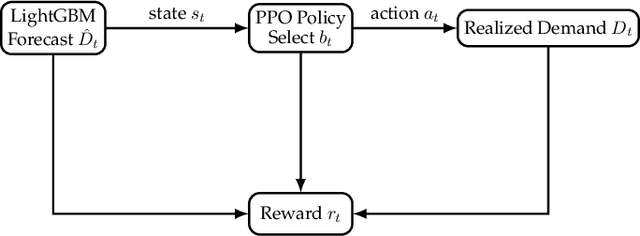
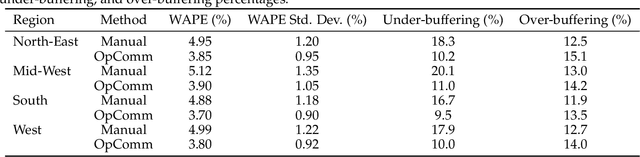
Accurate forecasting of package volumes at delivery stations is critical for last-mile logistics, where errors lead to inefficient resource allocation, higher costs, and delivery delays. We propose OpComm, a forecasting and decision-support framework that combines supervised learning with reinforcement learning-based buffer control and a generative AI-driven communication module. A LightGBM regression model generates station-level demand forecasts, which serve as context for a Proximal Policy Optimization (PPO) agent that selects buffer levels from a discrete action set. The reward function penalizes under-buffering more heavily than over-buffering, reflecting real-world trade-offs between unmet demand risks and resource inefficiency. Station outcomes are fed back through a Monte Carlo update mechanism, enabling continual policy adaptation. To enhance interpretability, a generative AI layer produces executive-level summaries and scenario analyses grounded in SHAP-based feature attributions. Across 400+ stations, OpComm reduced Weighted Absolute Percentage Error (WAPE) by 21.65% compared to manual forecasts, while lowering under-buffering incidents and improving transparency for decision-makers. This work shows how contextual reinforcement learning, coupled with predictive modeling, can address operational forecasting challenges and bridge statistical rigor with practical decision-making in high-stakes logistics environments.
Beyond QA Pairs: Assessing Parameter-Efficient Fine-Tuning for Fact Embedding in LLMs
Mar 03, 2025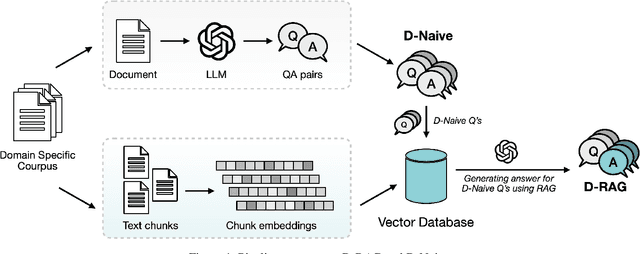
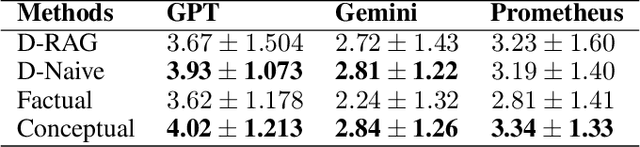
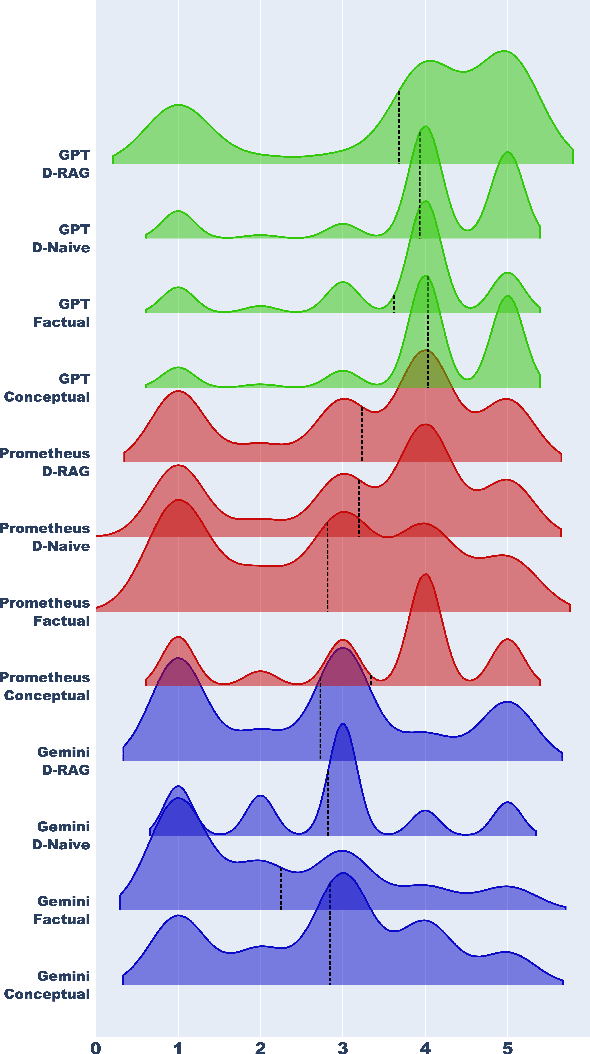
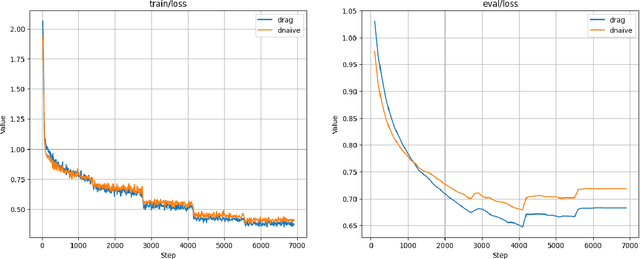
This paper presents an extensive examination of Parameter-Efficient Fine-Tuning (PEFT) for embedding domain specific facts into Large Language Models (LLMs), focusing on improving the fine-tuning process by categorizing question-answer (QA) pairs into Factual and Conceptual classes using a BERT-based classifier. Two distinct Llama-2 models are fine-tuned based on these classifications and evaluated using larger models like GPT-3.5 Turbo and Gemini. Our results indicate that models trained on conceptual datasets outperform those trained on factual datasets. Additionally, we compare the efficiency of two synthetic fine-tuning dataset generation techniques, D-RAG and D-Naive, with D-Naive demonstrating superior performance. Although PEFT has shown effectiveness, our research indicates that it may not be the most optimal method for embedding facts into LLMs. However, it has demonstrated exceptional performance in instruction-based tasks. Our findings are reinforced by a 1000-sample dataset in the data center domain, where the fine-tuned Llama-2 7B model significantly outperforms the baseline model in generating product recommendations. Our study highlights the importance of QA pair categorization and synthetic dataset generation techniques in enhancing the performance of LLMs in specific domains.
* Presented at the Workshop on Preparing Good Data for Generative AI: Challenges and Approaches (Good-Data) in conjunction with AAAI 2025. The authors retain the copyright
To Copy, or not to Copy; That is a Critical Issue of the Output Softmax Layer in Neural Sequential Recommenders
Oct 21, 2023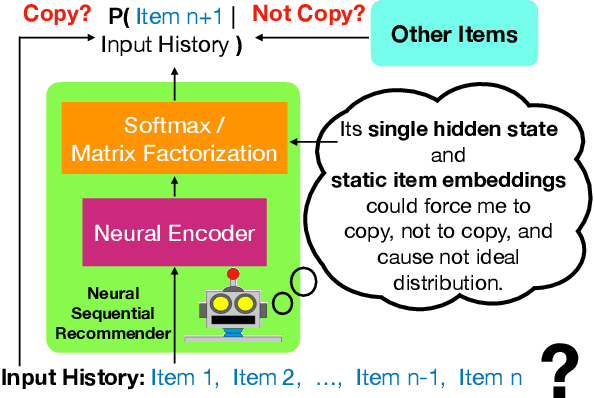



Recent studies suggest that the existing neural models have difficulty handling repeated items in sequential recommendation tasks. However, our understanding of this difficulty is still limited. In this study, we substantially advance this field by identifying a major source of the problem: the single hidden state embedding and static item embeddings in the output softmax layer. Specifically, the similarity structure of the global item embeddings in the softmax layer sometimes forces the single hidden state embedding to be close to new items when copying is a better choice, while sometimes forcing the hidden state to be close to the items from the input inappropriately. To alleviate the problem, we adapt the recently-proposed softmax alternatives such as softmax-CPR to sequential recommendation tasks and demonstrate that the new softmax architectures unleash the capability of the neural encoder on learning when to copy and when to exclude the items from the input sequence. By only making some simple modifications on the output softmax layer for SASRec and GRU4Rec, softmax-CPR achieves consistent improvement in 12 datasets. With almost the same model size, our best method not only improves the average NDCG@10 of GRU4Rec in 5 datasets with duplicated items by 10% (4%-17% individually) but also improves 7 datasets without duplicated items by 24% (8%-39%)!
Bringing Cartoons to Life: Towards Improved Cartoon Face Detection and Recognition Systems
Jul 06, 2018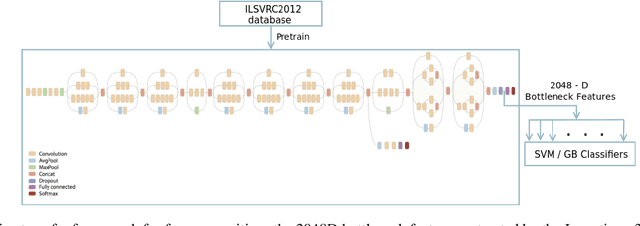

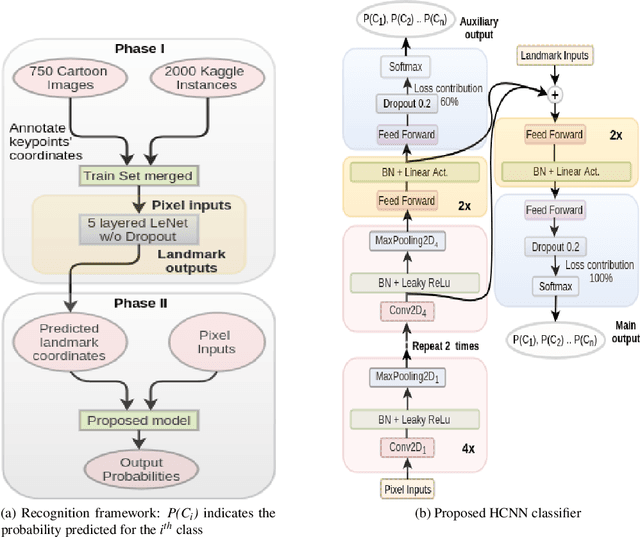
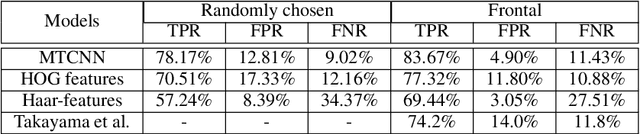
Given the recent deep learning advancements in face detection and recognition techniques for human faces, this paper answers the question "how well would they work for cartoons'?" - a domain that remains largely unexplored until recently, mainly due to the unavailability of large scale datasets and the failure of traditional methods on these. Our work studies and extends multiple frameworks for the aforementioned tasks. For face detection, we incorporate the Multi-task Cascaded Convolutional Network (MTCNN) architecture and contrast it with conventional methods. For face recognition, our two-fold contributions include: (i) an inductive transfer learning approach combining the feature learning capability of the Inception v3 network and the feature recognizing capability of Support Vector Machines (SVMs), (ii) a proposed Hybrid Convolutional Neural Network (HCNN) framework trained over a fusion of pixel values and 15 manually located facial keypoints. All the methods are evaluated on the Cartoon Faces in the Wild (IIIT-CFW) database. We demonstrate that the HCNN model offers stability superior to that of Inception+SVM over larger input variations, and explore the plausible architectural principles. We show that the Inception+SVM model establishes a state-of-the-art F1 score on the task of gender recognition of cartoon faces. Further, we introduce a small database hosting location coordinates of 15 points on the cartoon faces belonging to 50 public figures of the IIIT-CFW database.