 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Cartoons to Life: Towards Improved Cartoon Face Detection and Recognition Systems
Jul 06, 2018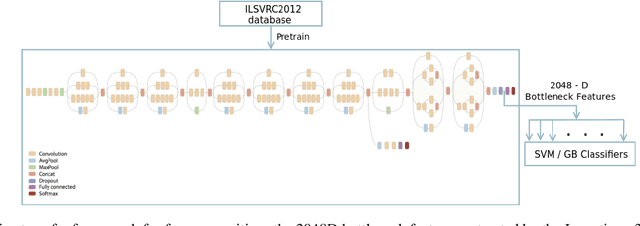

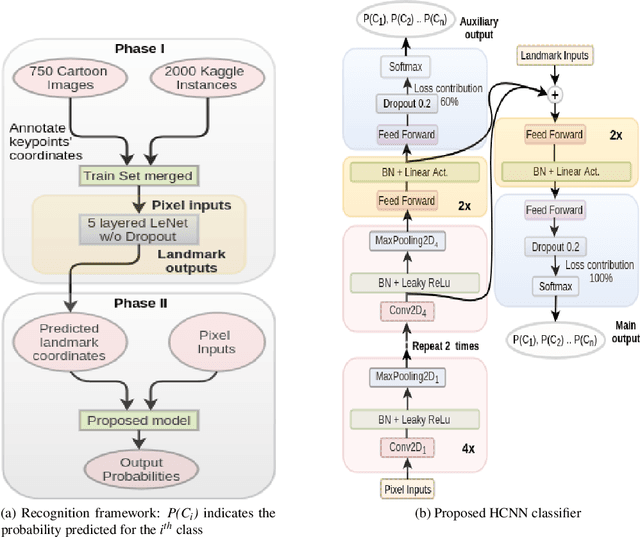
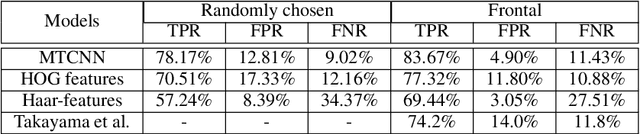
Given the recent deep learning advancements in face detection and recognition techniques for human faces, this paper answers the question "how well would they work for cartoons'?" - a domain that remains largely unexplored until recently, mainly due to the unavailability of large scale datasets and the failure of traditional methods on these. Our work studies and extends multiple frameworks for the aforementioned tasks. For face detection, we incorporate the Multi-task Cascaded Convolutional Network (MTCNN) architecture and contrast it with conventional methods. For face recognition, our two-fold contributions include: (i) an inductive transfer learning approach combining the feature learning capability of the Inception v3 network and the feature recognizing capability of Support Vector Machines (SVMs), (ii) a proposed Hybrid Convolutional Neural Network (HCNN) framework trained over a fusion of pixel values and 15 manually located facial keypoints. All the methods are evaluated on the Cartoon Faces in the Wild (IIIT-CFW) database. We demonstrate that the HCNN model offers stability superior to that of Inception+SVM over larger input variations, and explore the plausible architectural principles. We show that the Inception+SVM model establishes a state-of-the-art F1 score on the task of gender recognition of cartoon faces. Further, we introduce a small database hosting location coordinates of 15 points on the cartoon faces belonging to 50 public figures of the IIIT-CFW database.