 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond QA Pairs: Assessing Parameter-Efficient Fine-Tuning for Fact Embedding in LLMs
Mar 03, 2025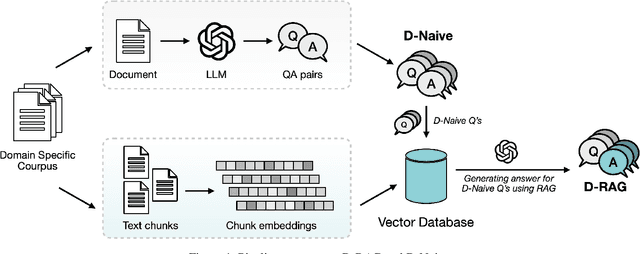
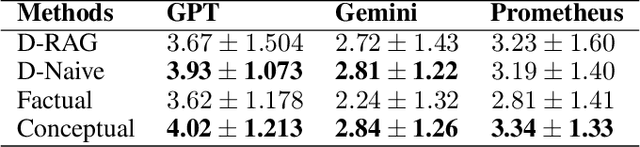
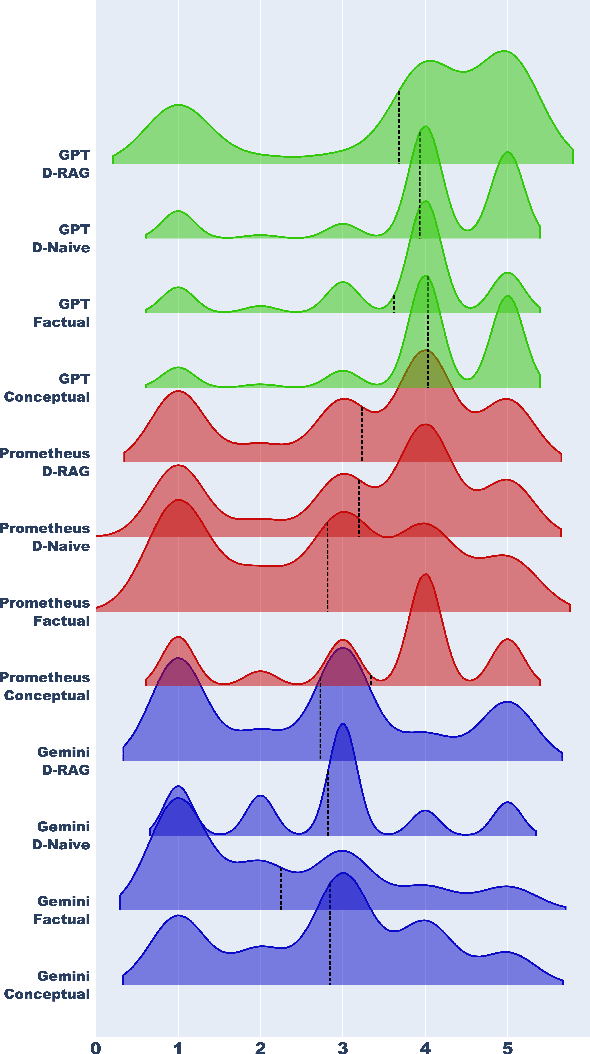
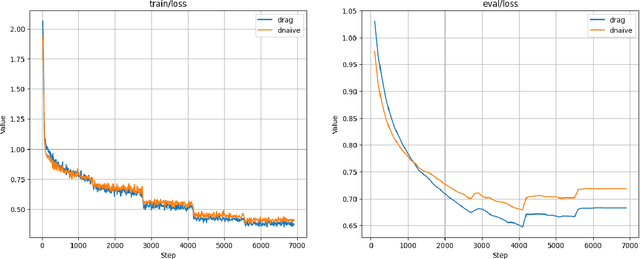
This paper presents an extensive examination of Parameter-Efficient Fine-Tuning (PEFT) for embedding domain specific facts into Large Language Models (LLMs), focusing on improving the fine-tuning process by categorizing question-answer (QA) pairs into Factual and Conceptual classes using a BERT-based classifier. Two distinct Llama-2 models are fine-tuned based on these classifications and evaluated using larger models like GPT-3.5 Turbo and Gemini. Our results indicate that models trained on conceptual datasets outperform those trained on factual datasets. Additionally, we compare the efficiency of two synthetic fine-tuning dataset generation techniques, D-RAG and D-Naive, with D-Naive demonstrating superior performance. Although PEFT has shown effectiveness, our research indicates that it may not be the most optimal method for embedding facts into LLMs. However, it has demonstrated exceptional performance in instruction-based tasks. Our findings are reinforced by a 1000-sample dataset in the data center domain, where the fine-tuned Llama-2 7B model significantly outperforms the baseline model in generating product recommendations. Our study highlights the importance of QA pair categorization and synthetic dataset generation techniques in enhancing the performance of LLMs in specific domains.
* Presented at the Workshop on Preparing Good Data for Generative AI: Challenges and Approaches (Good-Data) in conjunction with AAAI 2025. The authors retain the copyright
Self-Supervised Modality-Agnostic Pre-Training of Swin Transformers
May 21, 2024Unsupervised pre-training has emerged as a transformative paradigm, displaying remarkable advancements in various domains. However, the susceptibility to domain shift, where pre-training data distribution differs from fine-tuning, poses a significant obstacle. To address this, we augment the Swin Transformer to learn from different medical imaging modalities, enhancing downstream performance. Our model, dubbed SwinFUSE (Swin Multi-Modal Fusion for UnSupervised Enhancement), offers three key advantages: (i) it learns from both Computed Tomography (CT) and Magnetic Resonance Images (MRI) during pre-training, resulting in complementary feature representations; (ii) a domain-invariance module (DIM) that effectively highlights salient input regions, enhancing adaptability; (iii) exhibits remarkable generalizability, surpassing the confines of tasks it was initially pre-trained on. Our experiments on two publicly available 3D segmentation datasets show a modest 1-2% performance trade-off compared to single-modality models, yet significant out-performance of up to 27% on out-of-distribution modality. This substantial improvement underscores our proposed approach's practical relevance and real-world applicability. Code is available at: https://github.com/devalab/SwinFUSE