 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Modality-Agnostic Pre-Training of Swin Transformers
May 21, 2024Unsupervised pre-training has emerged as a transformative paradigm, displaying remarkable advancements in various domains. However, the susceptibility to domain shift, where pre-training data distribution differs from fine-tuning, poses a significant obstacle. To address this, we augment the Swin Transformer to learn from different medical imaging modalities, enhancing downstream performance. Our model, dubbed SwinFUSE (Swin Multi-Modal Fusion for UnSupervised Enhancement), offers three key advantages: (i) it learns from both Computed Tomography (CT) and Magnetic Resonance Images (MRI) during pre-training, resulting in complementary feature representations; (ii) a domain-invariance module (DIM) that effectively highlights salient input regions, enhancing adaptability; (iii) exhibits remarkable generalizability, surpassing the confines of tasks it was initially pre-trained on. Our experiments on two publicly available 3D segmentation datasets show a modest 1-2% performance trade-off compared to single-modality models, yet significant out-performance of up to 27% on out-of-distribution modality. This substantial improvement underscores our proposed approach's practical relevance and real-world applicability. Code is available at: https://github.com/devalab/SwinFUSE
IMLE-Net: An Interpretable Multi-level Multi-channel Model for ECG Classification
Apr 06, 2022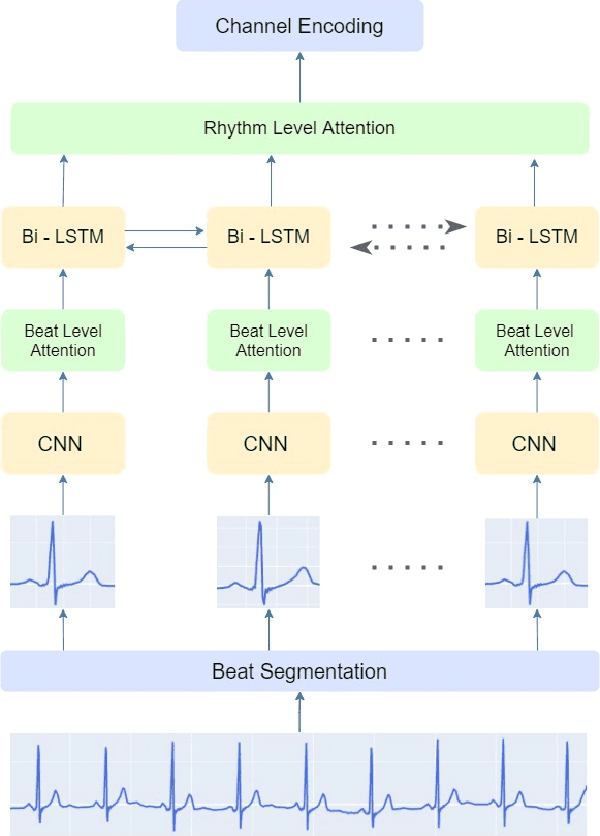
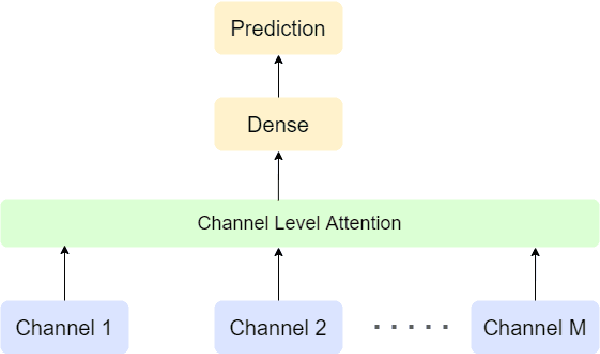
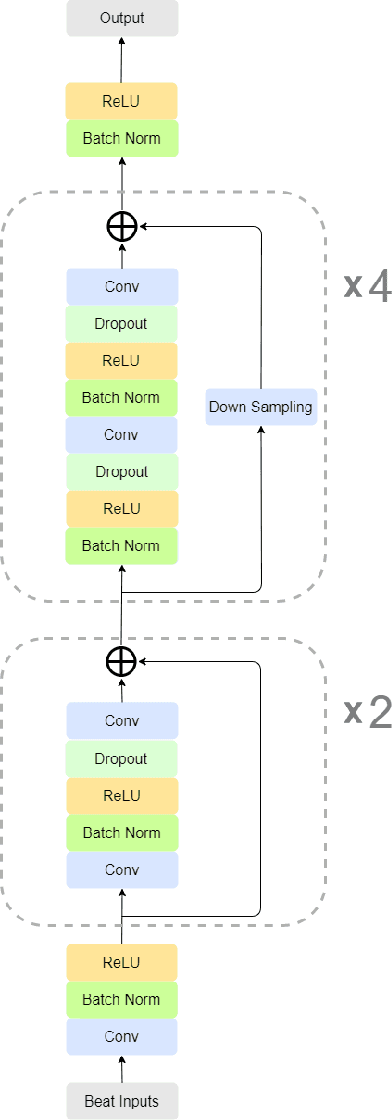

Early detection of cardiovascular diseases is crucial for effective treatment and an electrocardiogram (ECG) is pivotal for diagnosis. The accuracy of Deep Learning based methods for ECG signal classification has progressed in recent years to reach cardiologist-level performance. In clinical settings, a cardiologist makes a diagnosis based on the standard 12-channel ECG recording. Automatic analysis of ECG recordings from a multiple-channel perspective has not been given enough attention, so it is essential to analyze an ECG recording from a multiple-channel perspective. We propose a model that leverages the multiple-channel information available in the standard 12-channel ECG recordings and learns patterns at the beat, rhythm, and channel level. The experimental results show that our model achieved a macro-averaged ROC-AUC score of 0.9216, mean accuracy of 88.85\%, and a maximum F1 score of 0.8057 on the PTB-XL dataset. The attention visualization results from the interpretable model are compared against the cardiologist's guidelines to validate the correctness and usability.
Linear Prediction Residual for Efficient Diagnosis of Parkinson's Disease from Gait
Jul 09, 2021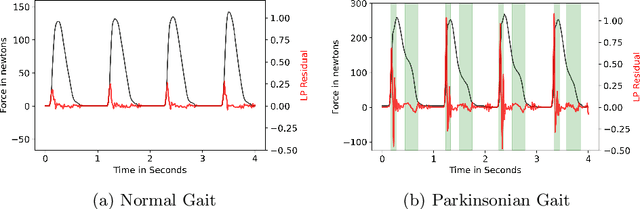
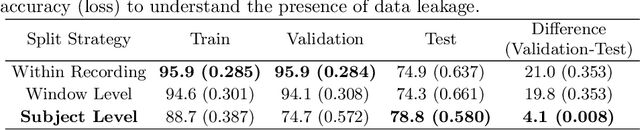
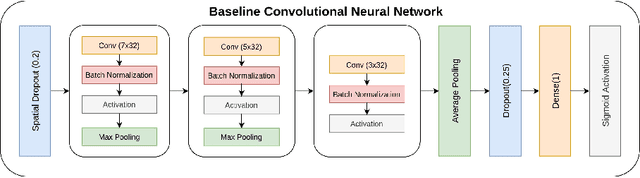
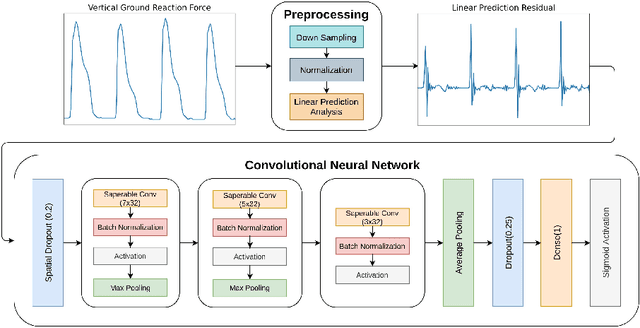
Parkinson's Disease (PD) is a chronic and progressive neurological disorder that results in rigidity, tremors and postural instability. There is no definite medical test to diagnose PD and diagnosis is mostly a clinical exercise. Although guidelines exist, about 10-30% of the patients are wrongly diagnosed with PD. Hence, there is a need for an accurate, unbiased and fast method for diagnosis. In this study, we propose LPGNet, a fast and accurate method to diagnose PD from gait. LPGNet uses Linear Prediction Residuals (LPR) to extract discriminating patterns from gait recordings and then uses a 1D convolution neural network with depth-wise separable convolutions to perform diagnosis. LPGNet achieves an AUC of 0.91 with a 21 times speedup and about 99% lesser parameters in the model compared to the state of the art. We also undertake an analysis of various cross-validation strategies used in literature in PD diagnosis from gait and find that most methods are affected by some form of data leakage between various folds which leads to unnecessarily large models and inflated performance due to overfitting. The analysis clears the path for future works in correctly evaluating their methods.