 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewShotTextGCN: K-hop neighborhood regularization for few-shot learning on graphs
Jan 25, 2023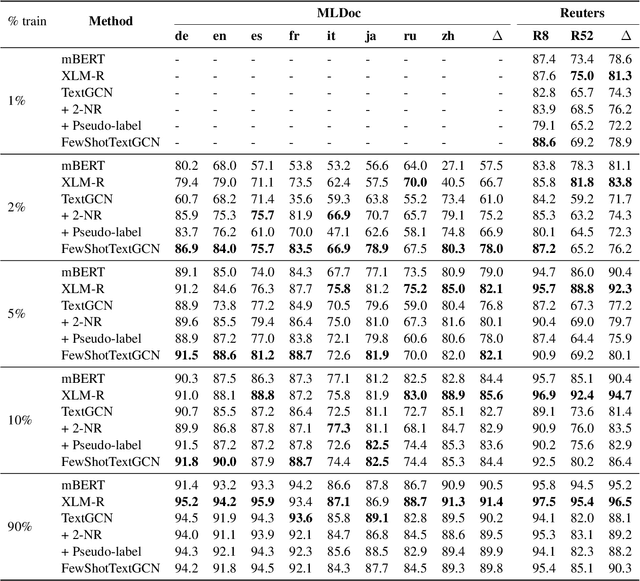
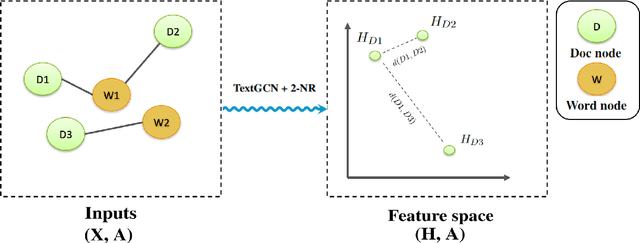
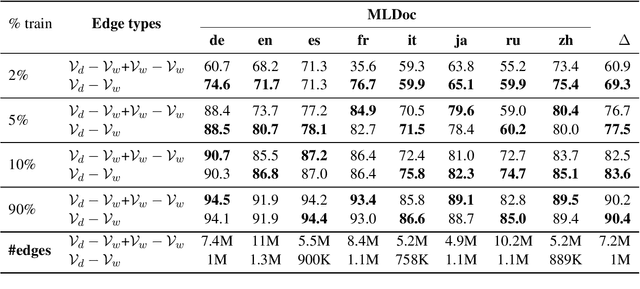
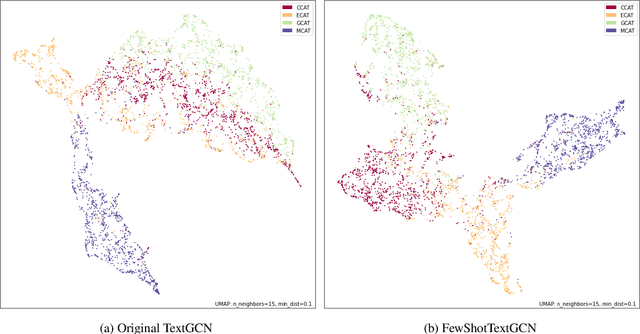
We present FewShotTextGCN, a novel method designed to effectively utilize the properties of word-document graphs for improved learning in low-resource settings. We introduce K-hop Neighbourhood Regularization, a regularizer for heterogeneous graphs, and show that it stabilizes and improves learning when only a few training samples are available. We furthermore propose a simplification in the graph-construction method, which results in a graph that is $\sim$7 times less dense and yields better performance in little-resource settings while performing on par with the state of the art in high-resource settings. Finally, we introduce a new variant of Adaptive Pseudo-Labeling tailored for word-document graphs. When using as little as 20 samples for training, we outperform a strong TextGCN baseline with 17% in absolute accuracy on average over eight languages. We demonstrate that our method can be applied to document classification without any language model pretraining on a wide range of typologically diverse languages while performing on par with large pretrained language models.
Multilingual and cross-lingual document classification: A meta-learning approach
Jan 27, 2021
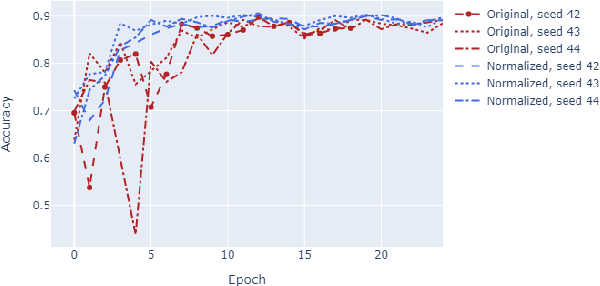
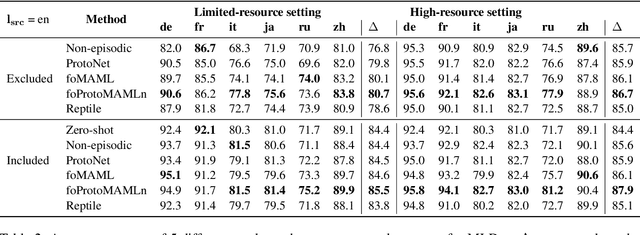
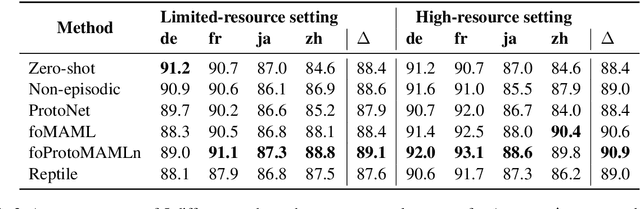
The great majority of languages in the world are considered under-resourced for the successful application of deep learning methods. In this work, we propose a meta-learning approach to document classification in limited-resource setting and demonstrate its effectiveness in two different settings: few-shot, cross-lingual adaptation to previously unseen languages; and multilingual joint training when limited target-language data is available during training. We conduct a systematic comparison of several meta-learning methods, investigate multiple settings in terms of data availability and show that meta-learning thrives in settings with a heterogeneous task distribution. We propose a simple, yet effective adjustment to existing meta-learning methods which allows for better and more stable learning, and set a new state of the art on several languages while performing on-par on others, using only a small amount of labeled data.
A Comparison of Architectures and Pretraining Methods for Contextualized Multilingual Word Embeddings
Dec 15, 2019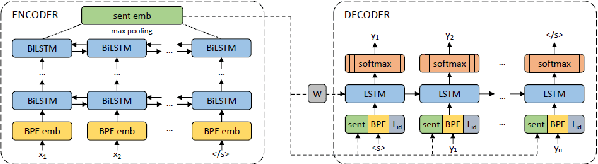

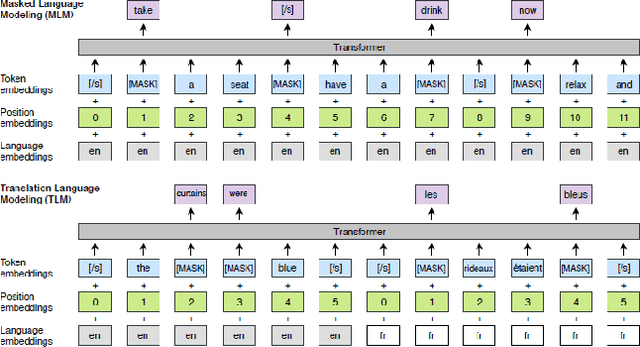
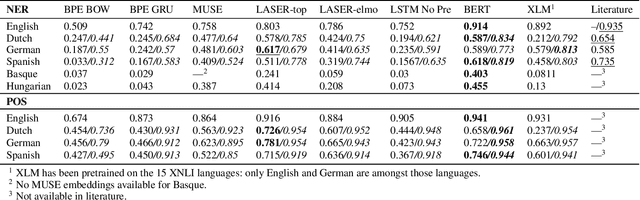
The lack of annotated data in many languages is a well-known challenge within the field of multilingual natural language processing (NLP). Therefore, many recent studies focus on zero-shot transfer learning and joint training across languages to overcome data scarcity for low-resource languages. In this work we (i) perform a comprehensive comparison of state-ofthe-art multilingual word and sentence encoders on the tasks of named entity recognition (NER) and part of speech (POS) tagging; and (ii) propose a new method for creating multilingual contextualized word embeddings, compare it to multiple baselines and show that it performs at or above state-of-theart level in zero-shot transfer settings. Finally, we show that our method allows for better knowledge sharing across languages in a joint training setting.