 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewShotTextGCN: K-hop neighborhood regularization for few-shot learning on graphs
Paper and Code
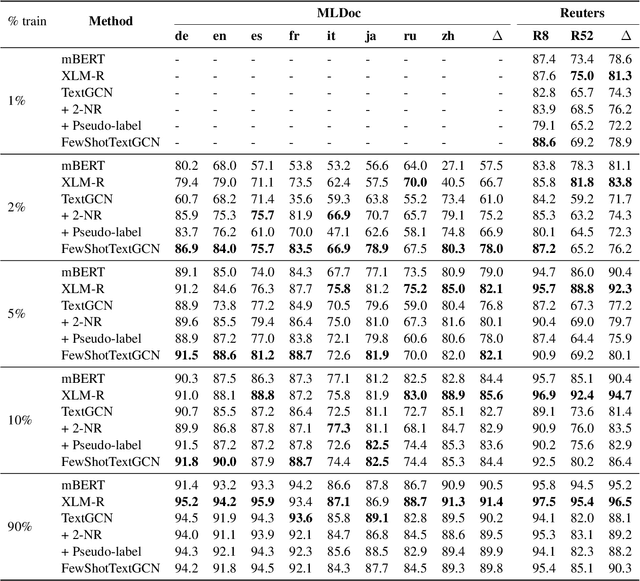
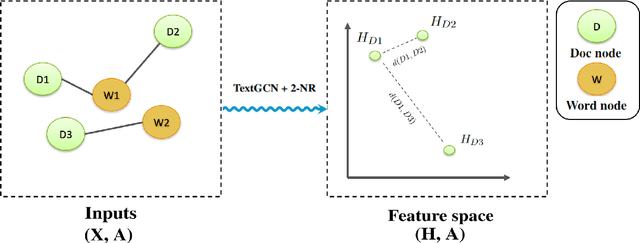
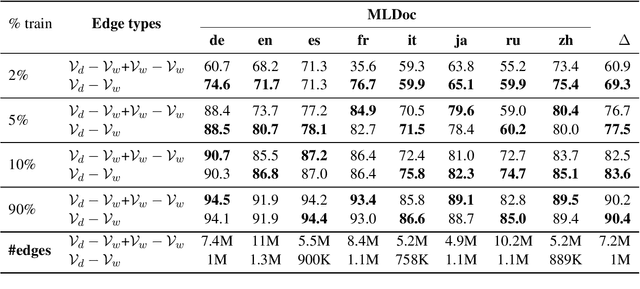
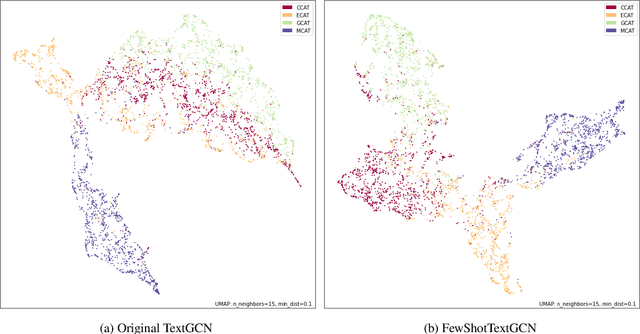
We present FewShotTextGCN, a novel method designed to effectively utilize the properties of word-document graphs for improved learning in low-resource settings. We introduce K-hop Neighbourhood Regularization, a regularizer for heterogeneous graphs, and show that it stabilizes and improves learning when only a few training samples are available. We furthermore propose a simplification in the graph-construction method, which results in a graph that is $\sim$7 times less dense and yields better performance in little-resource settings while performing on par with the state of the art in high-resource settings. Finally, we introduce a new variant of Adaptive Pseudo-Labeling tailored for word-document graphs. When using as little as 20 samples for training, we outperform a strong TextGCN baseline with 17% in absolute accuracy on average over eight languages. We demonstrate that our method can be applied to document classification without any language model pretraining on a wide range of typologically diverse languages while performing on par with large pretrained language models.