 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning to Address Data Shift in Time Series Classification
Jan 13, 2026Across engineering and scientific domains, traditional deep learning (TDL) models perform well when training and test data share the same distribution. However, the dynamic nature of real-world data, broadly termed \textit{data shift}, renders TDL models prone to rapid performance degradation, requiring costly relabeling and inefficient retraining. Meta-learning, which enables models to adapt quickly to new data with few examples, offers a promising alternative for mitigating these challenges. Here, we systematically compare TDL with fine-tuning and optimization-based meta-learning algorithms to assess their ability to address data shift in time-series classification. We introduce a controlled, task-oriented seismic benchmark (SeisTask) and show that meta-learning typically achieves faster and more stable adaptation with reduced overfitting in data-scarce regimes and smaller model architectures. As data availability and model capacity increase, its advantages diminish, with TDL with fine-tuning performing comparably. Finally, we examine how task diversity influences meta-learning and find that alignment between training and test distributions, rather than diversity alone, drives performance gains. Overall, this work provides a systematic evaluation of when and why meta-learning outperforms TDL under data shift and contributes SeisTask as a benchmark for advancing adaptive learning research in time-series domains.
"Thought I'd Share First": An Analysis of COVID-19 Conspiracy Theories and Misinformation Spread on Twitter
Dec 14, 2020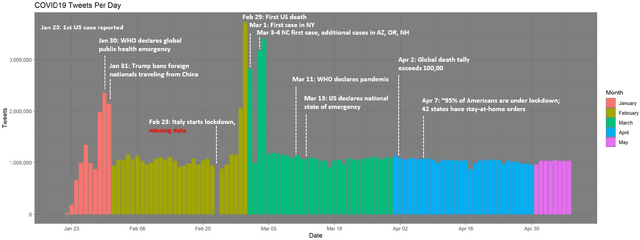
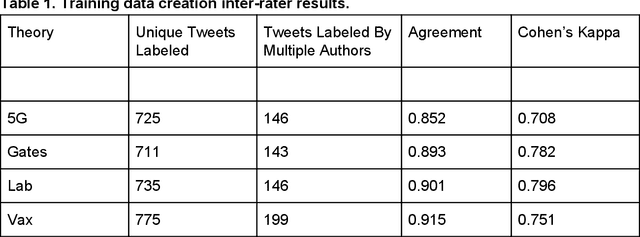
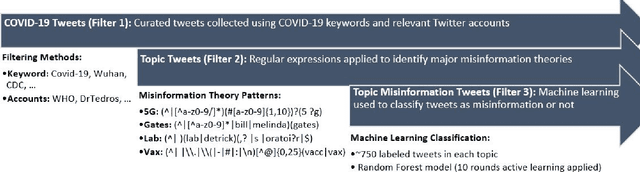
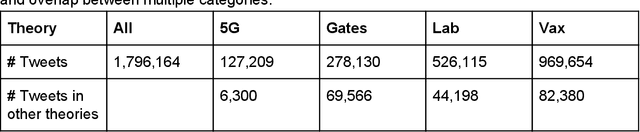
Background: Misinformation spread through social media is a growing problem, and the emergence of COVID-19 has caused an explosion in new activity and renewed focus on the resulting threat to public health. Given this increased visibility, in-depth analysis of COVID-19 misinformation spread is critical to understanding the evolution of ideas with potential negative public health impact. Methods: Using a curated data set of COVID-19 tweets (N ~120 million tweets) spanning late January to early May 2020, we applied methods including regular expression filtering, supervised machine learning, sentiment analysis, geospatial analysis, and dynamic topic modeling to trace the spread of misinformation and to characterize novel features of COVID-19 conspiracy theories. Results: Random forest models for four major misinformation topics provided mixed results, with narrowly-defined conspiracy theories achieving F1 scores of 0.804 and 0.857, while more broad theories performed measurably worse, with scores of 0.654 and 0.347. Despite this, analysis using model-labeled data was beneficial for increasing the proportion of data matching misinformation indicators. We were able to identify distinct increases in negative sentiment, theory-specific trends in geospatial spread, and the evolution of conspiracy theory topics and subtopics over time. Conclusions: COVID-19 related conspiracy theories show that history frequently repeats itself, with the same conspiracy theories being recycled for new situations. We use a combination of supervised learning, unsupervised learning, and natural language processing techniques to look at the evolution of theories over the first four months of the COVID-19 outbreak, how these theories intertwine, and to hypothesize on more effective public health messaging to combat misinformation in online spaces.
The ISTI Rapid Response on Exploring Cloud Computing 2018
Jan 04, 2019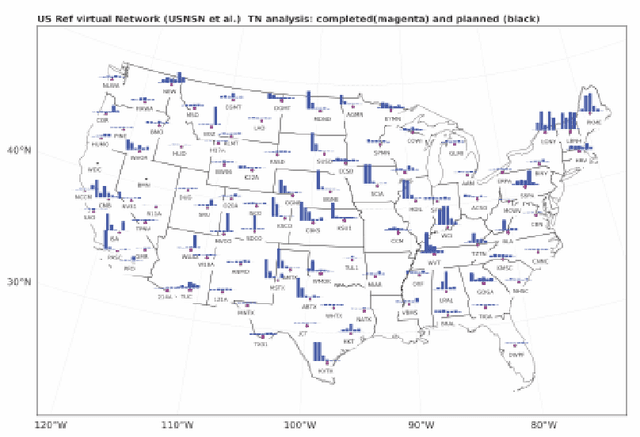
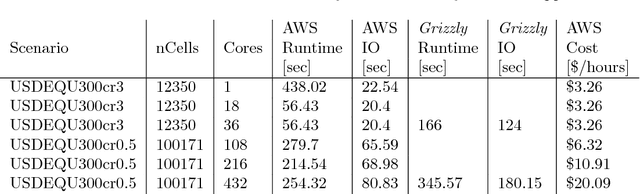
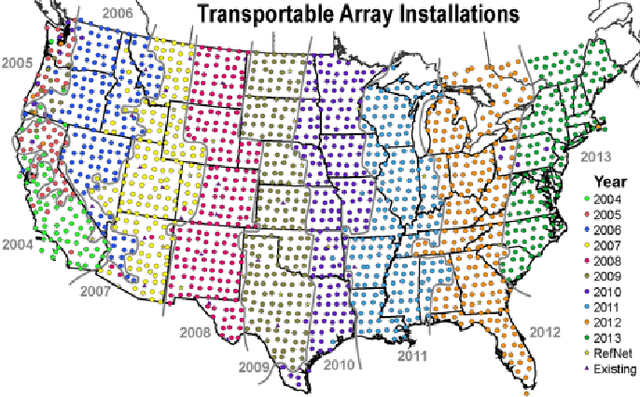

This report describes eighteen projects that explored how commercial cloud computing services can be utilized for scientific computation at national laboratories. These demonstrations ranged from deploying proprietary software in a cloud environment to leveraging established cloud-based analytics workflows for processing scientific datasets. By and large, the projects were successful and collectively they suggest that cloud computing can be a valuable computational resource for scientific computation at national laboratories.