 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Language Modeling via Posterior Sampling
Jun 02, 2026Large Language Models remain plagued by hallucinations. Recent work has sought to tame their prevalence using statistical techniques based on conformal prediction, with both theoretical and empirical success. However, these methods operate in a post-hoc fashion, treating the sampling procedure itself as atomic and then surgically altering samples to remove hallucinated claims. This disconnect between filtering and generation can result in samples that are incoherent, inconsistent, or simply unlikely under the model itself. Moreover, post-hoc surgery is unable to shift probability mass towards more useful and helpful responses. To address these issues, we propose to instead sample from approximations to an LLM posterior, where the conditioning event corresponds to a calibrated, high-scoring region. We develop a calibration procedure tailored to the setting of conditional sequential generation that effectively identifies this region and achieves target risk control. Empirically, we apply our method to case studies focused on open-ended biography generation and mathematical problem solving; compared to prior work, we obtain the same statistical guarantees, with higher downstream utility.
Prediction-Powered Inference Across Many Tasks for AI Evaluation & Social Science Research
May 28, 2026Many applications require statistically valid inference across many related tasks, while using only a handful of high-quality labels per hypothesis. In AI evaluation, these tasks may correspond to model behaviors across prompts, subgroups, or hypotheses; in social science surveys, they may correspond to related questions, populations, or measurement conditions. Prediction-powered inference (PPI) uses abundant but inexpensive proxy measurements to improve inference from limited, ground-truth labels, but commonly used methods treat tasks independently and therefore fail to exploit shared structure across related tasks. This limitation is especially important in settings where only a small number of labels are available per task. To address this issue, we introduce a multi-task prediction-powered inference framework that uses labeled data from related tasks to improve power while preserving task-specific inference. Our methods exploit the shared structure in the proxy-ground-truth relationship through cross-task recalibration, while retaining within-task rectification and power tuning to construct accurate point estimates and confidence intervals. We prove that efficiency gains beyond power-tuned PPI are only possible when the proxy-ground-truth relationship contains nonlinear structure; affine cross-task recalibrations are asymptotically equivalent to using the original proxy. We complement our theoretical findings with experiments on synthetic and semi-synthetic datasets, as well as a case study auditing language models on election-related information during the 2024 U.S. presidential election. Using a large human-annotation study, we show that cross-task recalibration can substantially reduce confidence interval widths when labels are scarce.
Likelihood Ratio Confidence Sets for Sequential Decision Making
Nov 08, 2023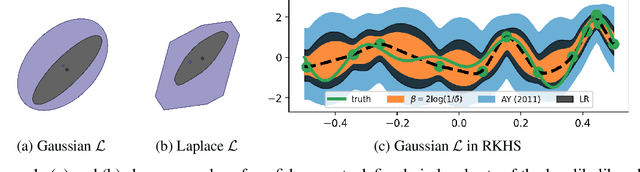



Certifiable, adaptive uncertainty estimates for unknown quantities are an essential ingredient of sequential decision-making algorithms. Standard approaches rely on problem-dependent concentration results and are limited to a specific combination of parameterization, noise family, and estimator. In this paper, we revisit the likelihood-based inference principle and propose to use likelihood ratios to construct any-time valid confidence sequences without requiring specialized treatment in each application scenario. Our method is especially suitable for problems with well-specified likelihoods, and the resulting sets always maintain the prescribed coverage in a model-agnostic manner. The size of the sets depends on a choice of estimator sequence in the likelihood ratio. We discuss how to provably choose the best sequence of estimators and shed light on connections to online convex optimization with algorithms such as Follow-the-Regularized-Leader. To counteract the initially large bias of the estimators, we propose a reweighting scheme that also opens up deployment in non-parametric settings such as RKHS function classes. We provide a non-asymptotic analysis of the likelihood ratio confidence sets size for generalized linear models, using insights from convex duality and online learning. We showcase the practical strength of our method on generalized linear bandit problems, survival analysis, and bandits with various additive noise distributions.
Anytime Model Selection in Linear Bandits
Jul 24, 2023Model selection in the context of bandit optimization is a challenging problem, as it requires balancing exploration and exploitation not only for action selection, but also for model selection. One natural approach is to rely on online learning algorithms that treat different models as experts. Existing methods, however, scale poorly ($\text{poly}M$) with the number of models $M$ in terms of their regret. Our key insight is that, for model selection in linear bandits, we can emulate full-information feedback to the online learner with a favorable bias-variance trade-off. This allows us to develop ALEXP, which has an exponentially improved ($\log M$) dependence on $M$ for its regret. ALEXP has anytime guarantees on its regret, and neither requires knowledge of the horizon $n$, nor relies on an initial purely exploratory stage. Our approach utilizes a novel time-uniform analysis of the Lasso, establishing a new connection between online learning and high-dimensional statistics.
On the Oracle Complexity of Higher-Order Smooth Non-Convex Finite-Sum Optimization
Mar 08, 2021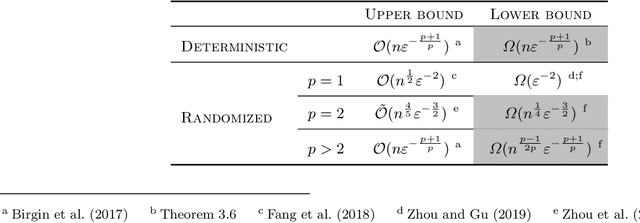

We prove lower bounds for higher-order methods in smooth non-convex finite-sum optimization. Our contribution is threefold: We first show that a deterministic algorithm cannot profit from the finite-sum structure of the objective, and that simulating a pth-order regularized method on the whole function by constructing exact gradient information is optimal up to constant factors. We further show lower bounds for randomized algorithms and compare them with the best known upper bounds. To address some gaps between the bounds, we propose a new second-order smoothness assumption that can be seen as an analogue of the first-order mean-squared smoothness assumption. We prove that it is sufficient to ensure state-of-the-art convergence guarantees, while allowing for a sharper lower bound.