 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Embeddings with Sparse Autoencoders: A Data Analysis Toolkit
Dec 10, 2025Analyzing large-scale text corpora is a core challenge in machine learning, crucial for tasks like identifying undesirable model behaviors or biases in training data. Current methods often rely on costly LLM-based techniques (e.g. annotating dataset differences) or dense embedding models (e.g. for clustering), which lack control over the properties of interest. We propose using sparse autoencoders (SAEs) to create SAE embeddings: representations whose dimensions map to interpretable concepts. Through four data analysis tasks, we show that SAE embeddings are more cost-effective and reliable than LLMs and more controllable than dense embeddings. Using the large hypothesis space of SAEs, we can uncover insights such as (1) semantic differences between datasets and (2) unexpected concept correlations in documents. For instance, by comparing model responses, we find that Grok-4 clarifies ambiguities more often than nine other frontier models. Relative to LLMs, SAE embeddings uncover bigger differences at 2-8x lower cost and identify biases more reliably. Additionally, SAE embeddings are controllable: by filtering concepts, we can (3) cluster documents along axes of interest and (4) outperform dense embeddings on property-based retrieval. Using SAE embeddings, we study model behavior with two case studies: investigating how OpenAI model behavior has changed over time and finding "trigger" phrases learned by Tulu-3 (Lambert et al., 2024) from its training data. These results position SAEs as a versatile tool for unstructured data analysis and highlight the neglected importance of interpreting models through their data.
Vision Transformers Don't Need Trained Registers
Jun 09, 2025



We investigate the mechanism underlying a previously identified phenomenon in Vision Transformers -- the emergence of high-norm tokens that lead to noisy attention maps. We observe that in multiple models (e.g., CLIP, DINOv2), a sparse set of neurons is responsible for concentrating high-norm activations on outlier tokens, leading to irregular attention patterns and degrading downstream visual processing. While the existing solution for removing these outliers involves retraining models from scratch with additional learned register tokens, we use our findings to create a training-free approach to mitigate these artifacts. By shifting the high-norm activations from our discovered register neurons into an additional untrained token, we can mimic the effect of register tokens on a model already trained without registers. We demonstrate that our method produces cleaner attention and feature maps, enhances performance over base models across multiple downstream visual tasks, and achieves results comparable to models explicitly trained with register tokens. We then extend test-time registers to off-the-shelf vision-language models to improve their interpretability. Our results suggest that test-time registers effectively take on the role of register tokens at test-time, offering a training-free solution for any pre-trained model released without them.
Interpreting and Editing Vision-Language Representations to Mitigate Hallucinations
Oct 03, 2024
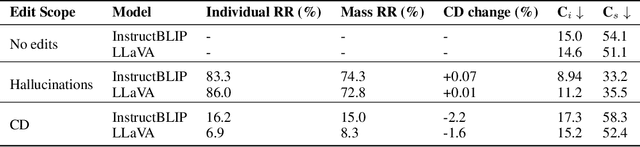
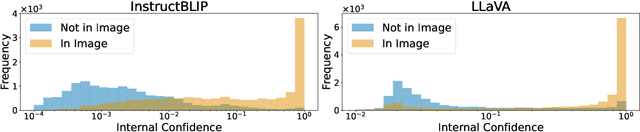

We investigate the internal representations of vision-language models (VLMs) to address hallucinations, a persistent challenge despite advances in model size and training. We project VLMs' internal image representations to their language vocabulary and observe more confident output probabilities on real objects than hallucinated objects. We additionally use these output probabilities to spatially localize real objects. Building on this approach, we introduce a knowledge erasure algorithm that removes hallucinations by linearly orthogonalizing image features with respect to hallucinated object features. We show that targeted edits to a model's latent representations can reduce hallucinations by up to 25.7% on the COCO2014 dataset while preserving performance. Our findings demonstrate how a deeper understanding of VLMs' latent representations can enhance reliability and enable novel capabilities, such as zero-shot segmentation.