 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyborg Insect Factory: Automatic Assembly System to Build up Insect-computer Hybrid Robot Based on Vision-guided Robotic Arm Manipulation of Custom Bipolar Electrodes
Nov 20, 2024The advancement of insect-computer hybrid robots holds significant promise for navigating complex terrains and enhancing robotics applications. This study introduced an automatic assembly method for insect-computer hybrid robots, which was accomplished by mounting backpack with precise implantation of custom-designed bipolar electrodes. We developed a stimulation protocol for the intersegmental membrane between pronotum and mesothorax of the Madagascar hissing cockroach, allowing for bipolar electrodes' automatic implantation using a robotic arm. The assembly process was integrated with a deep learning-based vision system to accurately identify the implantation site, and a dedicated structure to fix the insect (68 s for the whole assembly process). The automatically assembled hybrid robots demonstrated steering control (over 70 degrees for 0.4 s stimulation) and deceleration control (68.2% speed reduction for 0.4 s stimulation), matching the performance of manually assembled systems. Furthermore, a multi-agent system consisting of 4 hybrid robots successfully covered obstructed outdoor terrain (80.25% for 10 minutes 31 seconds), highlighting the feasibility of mass-producing these systems for practical applications. The proposed automatic assembly strategy reduced preparation time for the insect-computer hybrid robots while maintaining their precise control, laying a foundation for scalable production and deployment in real-world applications.
Dynamic Manipulation of a Deformable Linear Object: Simulation and Learning
Oct 02, 2023



We show that it is possible to learn an open-loop policy in simulation for the dynamic manipulation of a deformable linear object (DLO) -- e.g., a rope, wire, or cable -- that can be executed by a real robot without additional training. Our method is enabled by integrating an existing state-of-the-art DLO model (Discrete Elastic Rods) with MuJoCo, a robot simulator. We describe how this integration was done, check that validation results produced in simulation match what we expect from analysis of the physics, and apply policy optimization to train an open-loop policy from data collected only in simulation that uses a robot arm to fling a wire precisely between two obstacles. This policy achieves a success rate of 76.7% when executed by a real robot in hardware experiments without additional training on the real task.
Contact Reduction with Bounded Stiffness for Robust Sim-to-Real Transfer of Robot Assembly
Jun 11, 2023In sim-to-real Reinforcement Learning (RL), a policy is trained in a simulated environment and then deployed on the physical system. The main challenge of sim-to-real RL is to overcome the reality gap - the discrepancies between the real world and its simulated counterpart. Using general geometric representations, such as convex decomposition, triangular mesh, signed distance field can improve simulation fidelity, and thus potentially narrow the reality gap. Common to these approaches is that many contact points are generated for geometrically-complex objects, which slows down simulation and may cause numerical instability. Contact reduction methods address these issues by limiting the number of contact points, but the validity of these methods for sim-to-real RL has not been confirmed. In this paper, we present a contact reduction method with bounded stiffness to improve the simulation accuracy. Our experiments show that the proposed method critically enables training RL policy for a tight-clearance double pin insertion task and successfully deploying the policy on a rigid, position-controlled physical robot.
Reinforcement Learning with Parameterized Manipulation Primitives for Robotic Assembly
Jun 11, 2023



A common theme in robot assembly is the adoption of Manipulation Primitives as the atomic motion to compose assembly strategy, typically in the form of a state machine or a graph. While this approach has shown great performance and robustness in increasingly complex assembly tasks, the state machine has to be engineered manually in most cases. Such hard-coded strategies will fail to handle unexpected situations that are not considered in the design. To address this issue, we propose to find dynamics sequence of manipulation primitives through Reinforcement Learning. Leveraging parameterized manipulation primitives, the proposed method greatly improves both assembly performance and sample efficiency of Reinforcement Learning compared to a previous work using non-parameterized manipulation primitives. In practice, our method achieves good zero-shot sim-to-real performance on high-precision peg insertion tasks with different geometry, clearance, and material.
Learning Sequences of Manipulation Primitives for Robotic Assembly
Nov 02, 2020
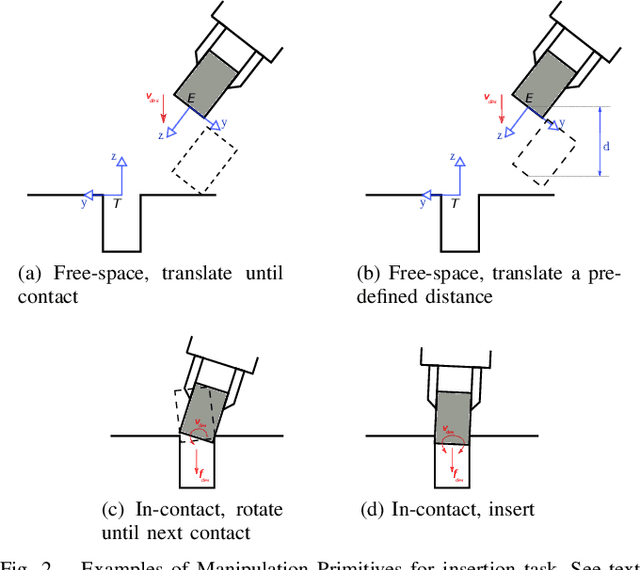
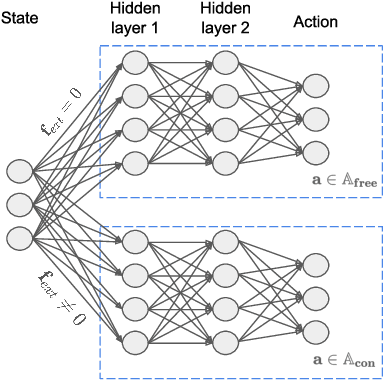
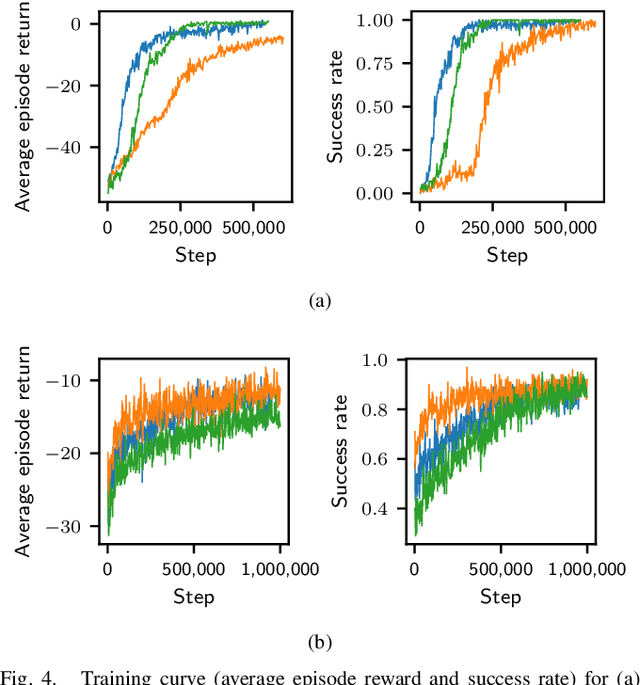
This paper explores the idea that skillful assembly is best represented as dynamic sequences of Manipulation Primitives, and that such sequences can be automatically discovered by Reinforcement Learning. Manipulation Primitives, such as ``Move down until contact'', ``Slide along x while maintaining contact with the surface'', have enough complexity to keep the search tree shallow, yet are generic enough to generalize across a wide range of assembly tasks. Policies are learned in simulation, and then transferred onto the physical platform. Direct sim2real transfer (without retraining in real) achieves excellent success rates on challenging assembly tasks, such as round peg insertion with 100 micron clearance or square peg insertion with large hole position/orientation estimation errors.