 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Artificial Intelligence Bias in Retinal Disease Diagnostics
May 08, 2020
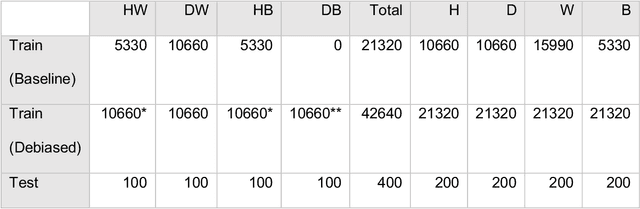
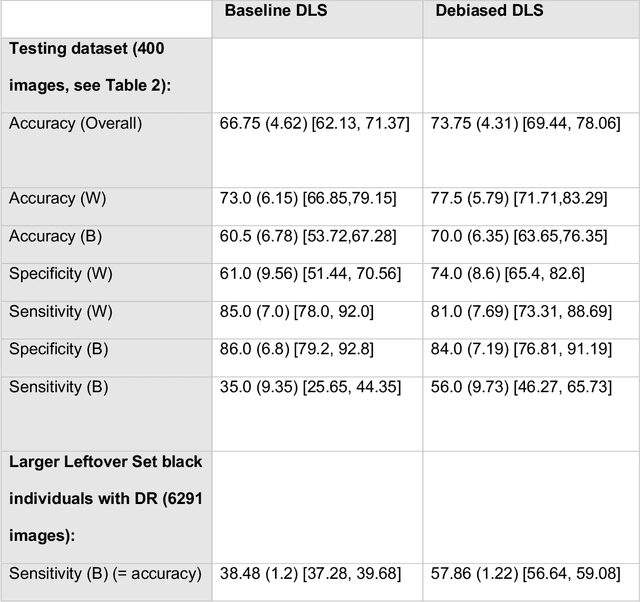

This study evaluated novel AI and deep learning generative methods to address AI bias for retinal diagnostic applications when specifically applied to diabetic retinopathy (DR). Bias often results from data imbalance. We specifically considered here a strong form of data imbalance corresponding to domain shift, where AI classifiers are faced at inference time with data and concepts they were not trained on initially (here the concept of diseased black individuals). A baseline DR diagnostics DLS designed to solve a two-class problem of referable vs not referable DR was used. We modified the public domain Kaggle-EyePACS dataset (88,692 fundi and 44,346 individuals), which was originally designed to be diverse with regard to ethnicity, as follows: 1) we expanded it to include clinician-annotated labels for race since those were not publicly available; 2) we excluded training exemplars for diseased black individuals in training, but not testing, to construct a new scenario of data imbalance with domain shift. For this domain shifted scenario, the accuracy (95% confidence intervals [CI]) of the baseline DR diagnostics DLS for whites was 73.0% (66.9%,79.2%) vs. blacks of 60.5% (53.5%,67.3%], demonstrating disparity of AI performance as measured by accuracy across races. By contrast, an AI approach leveraging generative models was used to train a new diagnostic DLS with additional synthetically generated data for the missing subpopulation (diseased blacks), which achieved accuracy for whites of 77.5% (71.7%,83.3%) and for blacks of 70.0% (63.7%,76.4%), demonstrating closer parity in accuracy across races. The new debiased DLS also showed improvement in sensitivity of over 21% for blacks, with the same level of specificity, when compared with the baseline DLS. These findings demonstrate the potential benefits of using novel generative methods for debiasing AI.
Deep Learning based Retinal OCT Segmentation
Jan 29, 2018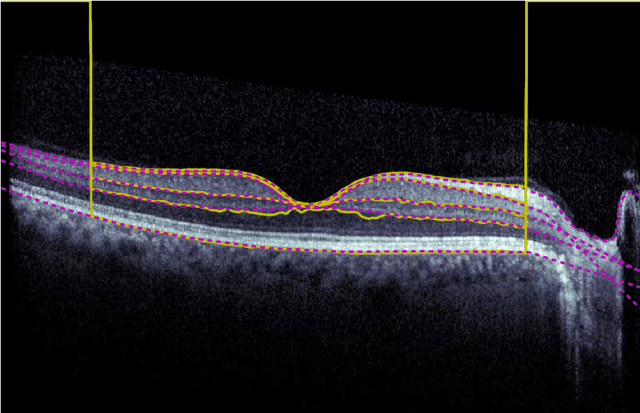
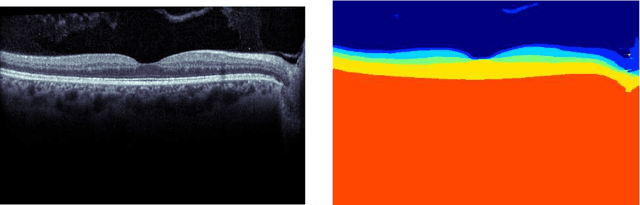
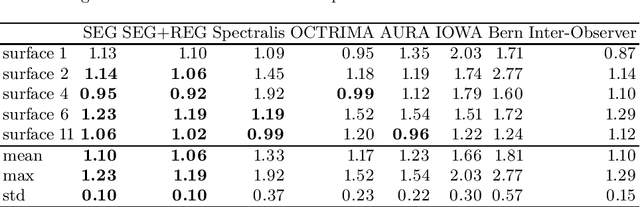
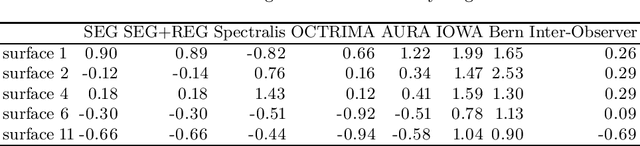
Our objective is to evaluate the efficacy of methods that use deep learning (DL) for the automatic fine-grained segmentation of optical coherence tomography (OCT) images of the retina. OCT images from 10 patients with mild non-proliferative diabetic retinopathy were used from a public (U. of Miami) dataset. For each patient, five images were available: one image of the fovea center, two images of the perifovea, and two images of the parafovea. For each image, two expert graders each manually annotated five retinal surfaces (i.e. boundaries between pairs of retinal layers). The first grader's annotations were used as ground truth and the second grader's annotations to compute inter-operator agreement. The proposed automated approach segments images using fully convolutional networks (FCNs) together with Gaussian process (GP)-based regression as a post-processing step to improve the quality of the estimates. Using 10-fold cross validation, the performance of the algorithms is determined by computing the per-pixel unsigned error (distance) between the automated estimates and the ground truth annotations generated by the first manual grader. We compare the proposed method against five state of the art automatic segmentation techniques. The results show that the proposed methods compare favorably with state of the art techniques, resulting in the smallest mean unsigned error values and associated standard deviations, and performance is comparable with human annotation of retinal layers from OCT when there is only mild retinopathy. The results suggest that semantic segmentation using FCNs, coupled with regression-based post-processing, can effectively solve the OCT segmentation problem on par with human capabilities with mild retinopathy.