 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning based Retinal OCT Segmentation
Jan 29, 2018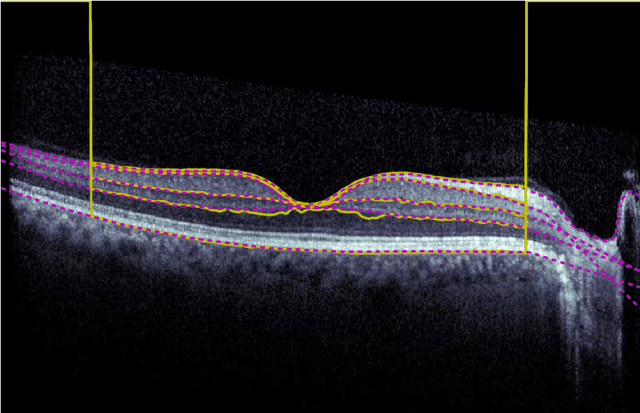
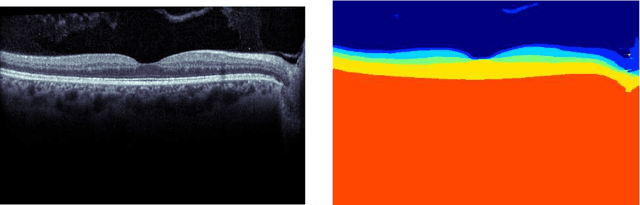
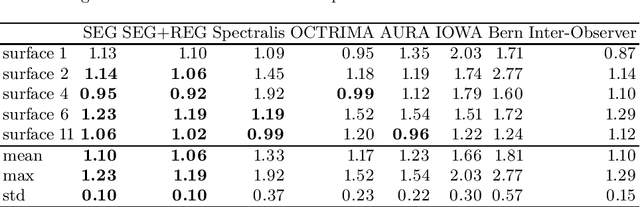
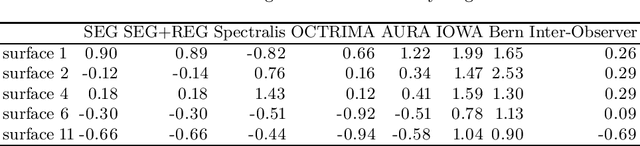
Our objective is to evaluate the efficacy of methods that use deep learning (DL) for the automatic fine-grained segmentation of optical coherence tomography (OCT) images of the retina. OCT images from 10 patients with mild non-proliferative diabetic retinopathy were used from a public (U. of Miami) dataset. For each patient, five images were available: one image of the fovea center, two images of the perifovea, and two images of the parafovea. For each image, two expert graders each manually annotated five retinal surfaces (i.e. boundaries between pairs of retinal layers). The first grader's annotations were used as ground truth and the second grader's annotations to compute inter-operator agreement. The proposed automated approach segments images using fully convolutional networks (FCNs) together with Gaussian process (GP)-based regression as a post-processing step to improve the quality of the estimates. Using 10-fold cross validation, the performance of the algorithms is determined by computing the per-pixel unsigned error (distance) between the automated estimates and the ground truth annotations generated by the first manual grader. We compare the proposed method against five state of the art automatic segmentation techniques. The results show that the proposed methods compare favorably with state of the art techniques, resulting in the smallest mean unsigned error values and associated standard deviations, and performance is comparable with human annotation of retinal layers from OCT when there is only mild retinopathy. The results suggest that semantic segmentation using FCNs, coupled with regression-based post-processing, can effectively solve the OCT segmentation problem on par with human capabilities with mild retinopathy.