 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRephraseTTS: Dynamic Length Text based Speech Insertion with Speaker Style Transfer
Aug 23, 2025



We propose a method for the task of text-conditioned speech insertion, i.e. inserting a speech sample in an input speech sample, conditioned on the corresponding complete text transcript. An example use case of the task would be to update the speech audio when corrections are done on the corresponding text transcript. The proposed method follows a transformer-based non-autoregressive approach that allows speech insertions of variable lengths, which are dynamically determined during inference, based on the text transcript and tempo of the available partial input. It is capable of maintaining the speaker's voice characteristics, prosody and other spectral properties of the available speech input. Results from our experiments and user study on LibriTTS show that our method outperforms baselines based on an existing adaptive text to speech method. We also provide numerous qualitative results to appreciate the quality of the output from the proposed method.
Styleclone: Face Stylization with Diffusion Based Data Augmentation
Aug 23, 2025We present StyleClone, a method for training image-to-image translation networks to stylize faces in a specific style, even with limited style images. Our approach leverages textual inversion and diffusion-based guided image generation to augment small style datasets. By systematically generating diverse style samples guided by both the original style images and real face images, we significantly enhance the diversity of the style dataset. Using this augmented dataset, we train fast image-to-image translation networks that outperform diffusion-based methods in speed and quality. Experiments on multiple styles demonstrate that our method improves stylization quality, better preserves source image content, and significantly accelerates inference. Additionally, we provide a systematic evaluation of the augmentation techniques and their impact on stylization performance.
Depth Infused Binaural Audio Generation using Hierarchical Cross-Modal Attention
Aug 10, 2021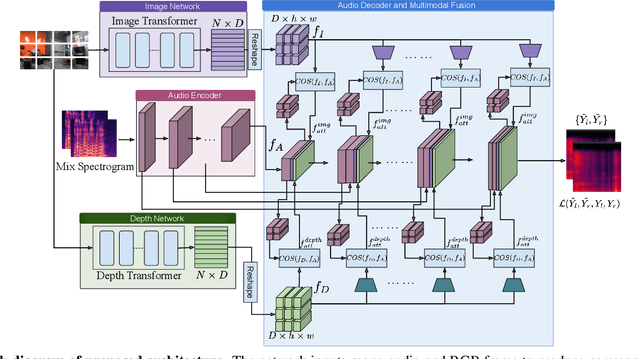

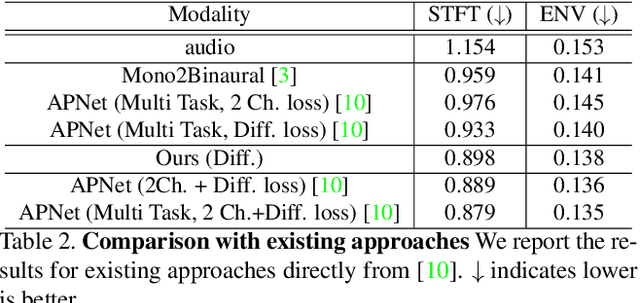

Binaural audio gives the listener the feeling of being in the recording place and enhances the immersive experience if coupled with AR/VR. But the problem with binaural audio recording is that it requires a specialized setup which is not possible to fabricate within handheld devices as compared to traditional mono audio that can be recorded with a single microphone. In order to overcome this drawback, prior works have tried to uplift the mono recorded audio to binaural audio as a post processing step conditioning on the visual input. But all the prior approaches missed other most important information required for the task, i.e. distance of different sound producing objects from the recording setup. In this work, we argue that the depth map of the scene can act as a proxy for encoding distance information of objects in the scene and show that adding depth features along with image features improves the performance both qualitatively and quantitatively. We propose a novel encoder-decoder architecture, where we use a hierarchical attention mechanism to encode the image and depth feature extracted from individual transformer backbone, with audio features at each layer of the decoder.
Coordinated Joint Multimodal Embeddings for Generalized Audio-Visual Zeroshot Classification and Retrieval of Videos
Oct 19, 2019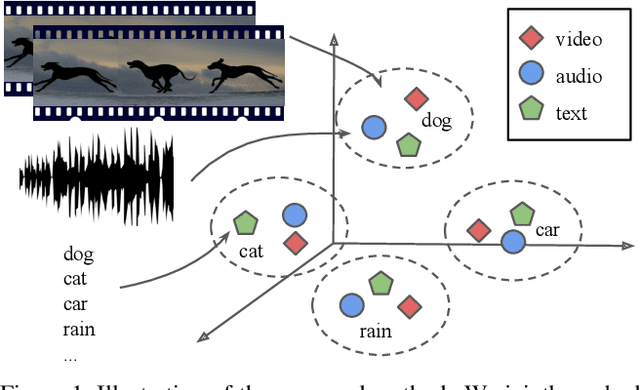

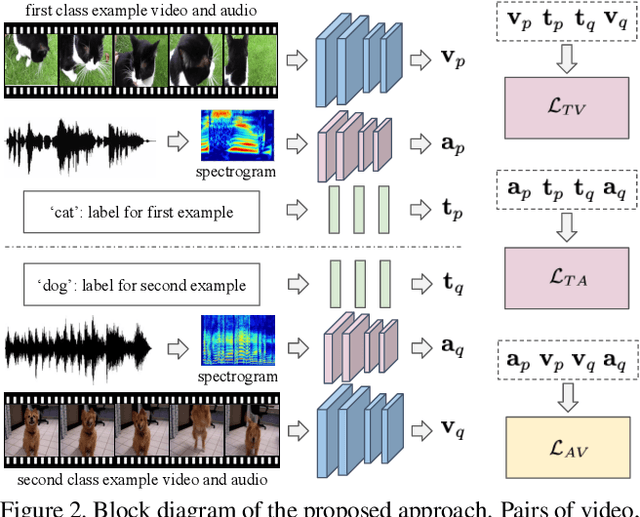
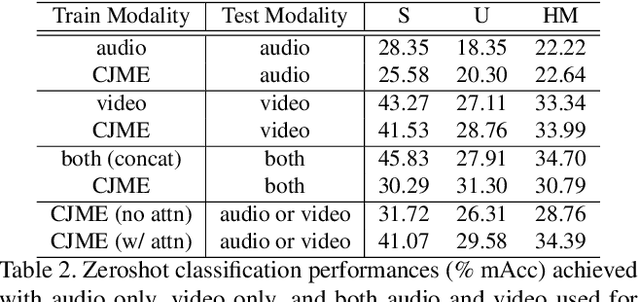
We present an audio-visual multimodal approach for the task of zeroshot learning (ZSL) for classification and retrieval of videos. ZSL has been studied extensively in the recent past but has primarily been limited to visual modality and to images. We demonstrate that both audio and visual modalities are important for ZSL for videos. Since a dataset to study the task is currently not available, we also construct an appropriate multimodal dataset with 33 classes containing 156,416 videos, from an existing large scale audio event dataset. We empirically show that the performance improves by adding audio modality for both tasks of zeroshot classification and retrieval, when using multimodal extensions of embedding learning methods. We also propose a novel method to predict the `dominant' modality using a jointly learned modality attention network. We learn the attention in a semi-supervised setting and thus do not require any additional explicit labelling for the modalities. We provide qualitative validation of the modality specific attention, which also successfully generalizes to unseen test classes.
Video Person Re-Identification using Learned Clip Similarity Aggregation
Oct 17, 2019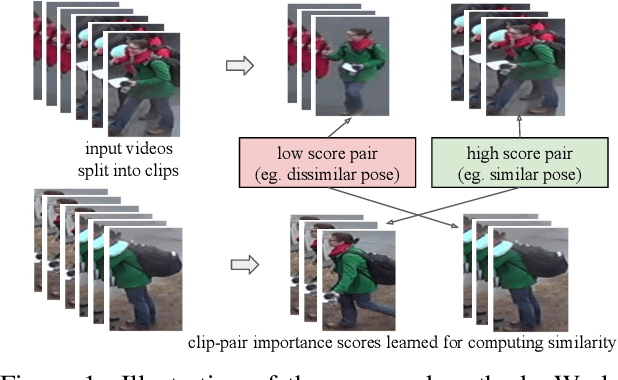



We address the challenging task of video-based person re-identification. Recent works have shown that splitting the video sequences into clips and then aggregating clip based similarity is appropriate for the task. We show that using a learned clip similarity aggregation function allows filtering out hard clip pairs, e.g. where the person is not clearly visible, is in a challenging pose, or where the poses in the two clips are too different to be informative. This allows the method to focus on clip-pairs which are more informative for the task. We also introduce the use of 3D CNNs for video-based re-identification and show their effectiveness by performing equivalent to previous works, which use optical flow in addition to RGB, while using RGB inputs only. We give quantitative results on three challenging public benchmarks and show better or competitive performance. We also validate our method qualitatively.
Multi-layer Pruning Framework for Compressing Single Shot MultiBox Detector
Nov 20, 2018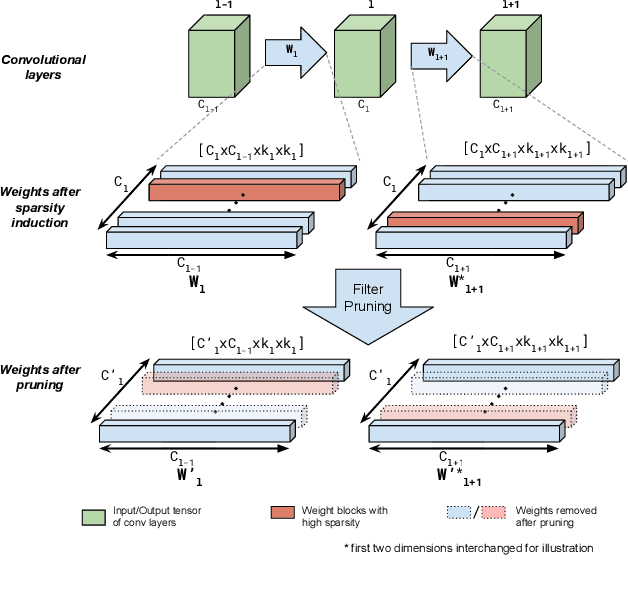

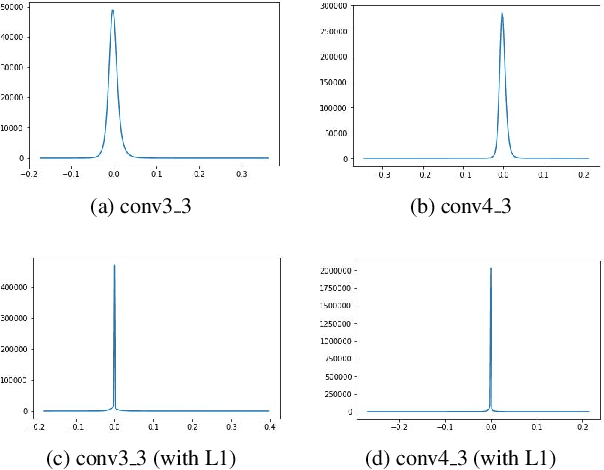

We propose a framework for compressing state-of-the-art Single Shot MultiBox Detector (SSD). The framework addresses compression in the following stages: Sparsity Induction, Filter Selection, and Filter Pruning. In the Sparsity Induction stage, the object detector model is sparsified via an improved global threshold. In Filter Selection & Pruning stage, we select and remove filters using sparsity statistics of filter weights in two consecutive convolutional layers. This results in the model with the size smaller than most existing compact architectures. We evaluate the performance of our framework with multiple datasets and compare over multiple methods. Experimental results show that our method achieves state-of-the-art compression of 6.7X and 4.9X on PASCAL VOC dataset on models SSD300 and SSD512 respectively. We further show that the method produces maximum compression of 26X with SSD512 on German Traffic Sign Detection Benchmark (GTSDB). Additionally, we also empirically show our method's adaptability for classification based architecture VGG16 on datasets CIFAR and German Traffic Sign Recognition Benchmark (GTSRB) achieving a compression rate of 125X and 200X with the reduction in flops by 90.50% and 96.6% respectively with no loss of accuracy. In addition to this, our method does not require any special libraries or hardware support for the resulting compressed models.