 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Management for IRS-assisted WP-MEC Networks with Practical Phase Shift Model
Sep 07, 2023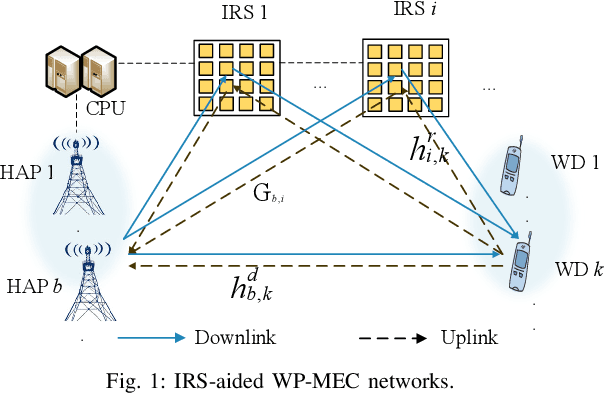
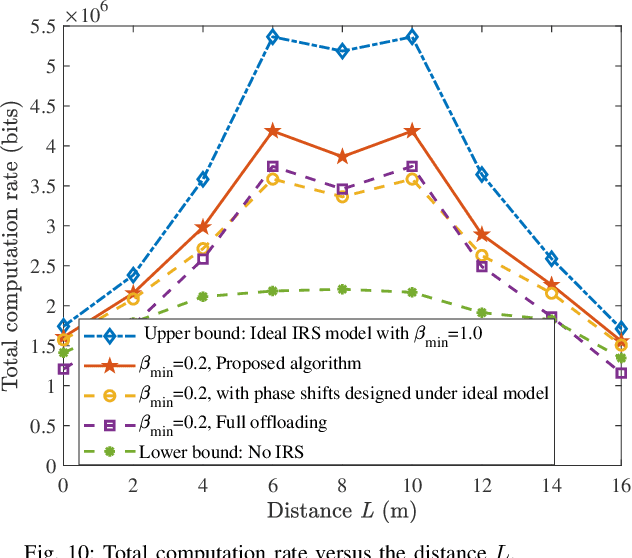
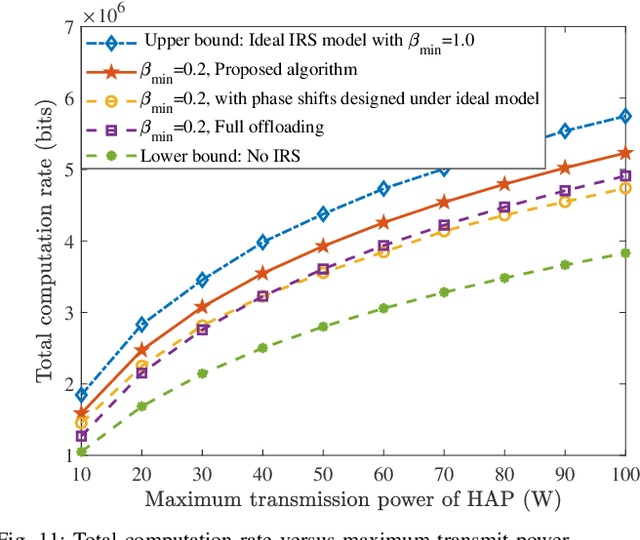
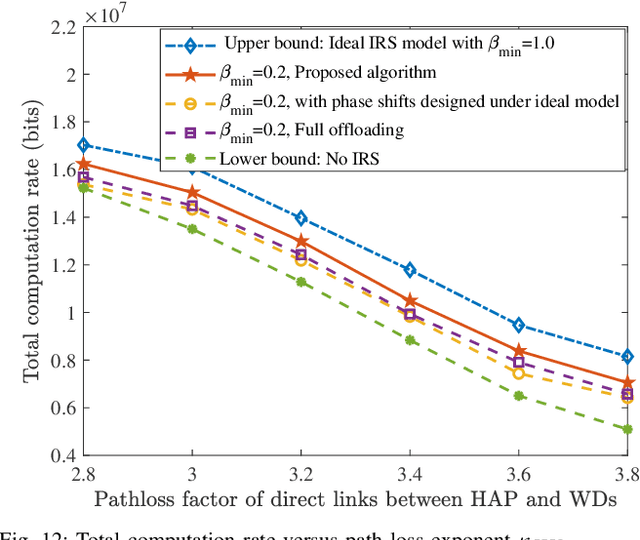
Wireless powered mobile edge computing (WP-MEC) has been recognized as a promising solution to enhance the computational capability and sustainable energy supply for low-power wireless devices (WDs). However, when the communication links between the hybrid access point (HAP) and WDs are hostile, the energy transfer efficiency and task offloading rate are compromised. To tackle this problem, we propose to employ multiple intelligent reflecting surfaces (IRSs) to WP-MEC networks. Based on the practical IRS phase shift model, we formulate a total computation rate maximization problem by jointly optimizing downlink/uplink IRSs passive beamforming, downlink energy beamforming and uplink multi-user detection (MUD) vector at HAPs, task offloading power and local computing frequency of WDs, and the time slot allocation. Specifically, we first derive the optimal time allocation for downlink wireless energy transmission (WET) to IRSs and the corresponding energy beamforming. Next, with fixed time allocation for the downlink WET to WDs, the original optimization problem can be divided into two independent subproblems. For the WD charging subproblem, the optimal IRSs passive beamforming is derived by utilizing the successive convex approximation (SCA) method and the penalty-based optimization technique, and for the offloading computing subproblem, we propose a joint optimization framework based on the fractional programming (FP) method. Finally, simulation results validate that our proposed optimization method based on the practical phase shift model can achieve a higher total computation rate compared to the baseline schemes.
Min-Max Latency Optimization for IRS-aided Cell-Free Mobile Edge Computing Systems
Jun 09, 2022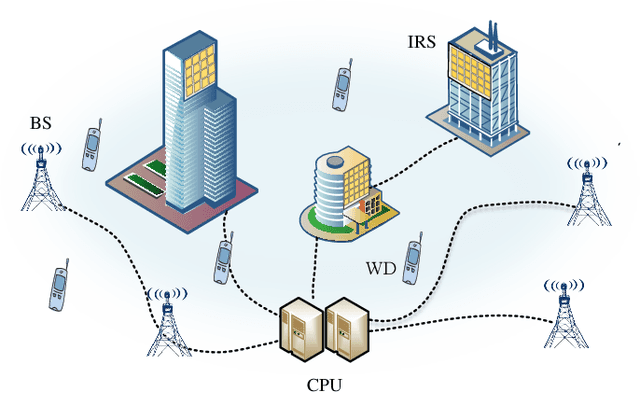
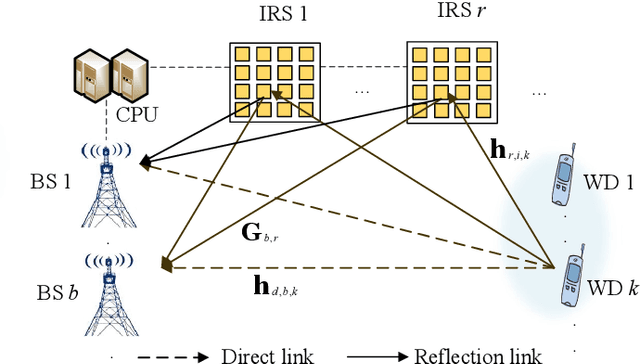
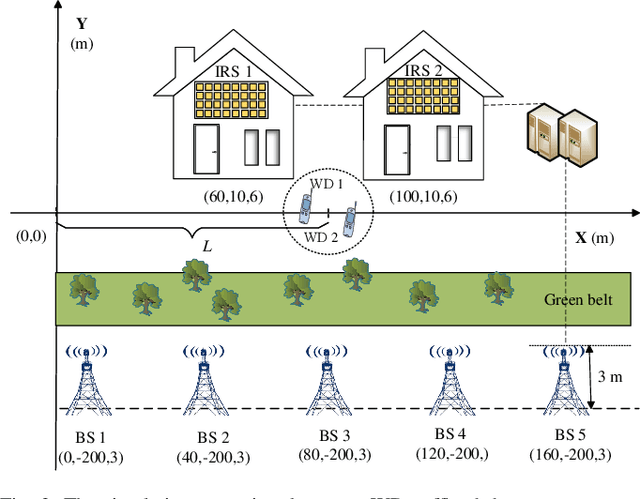
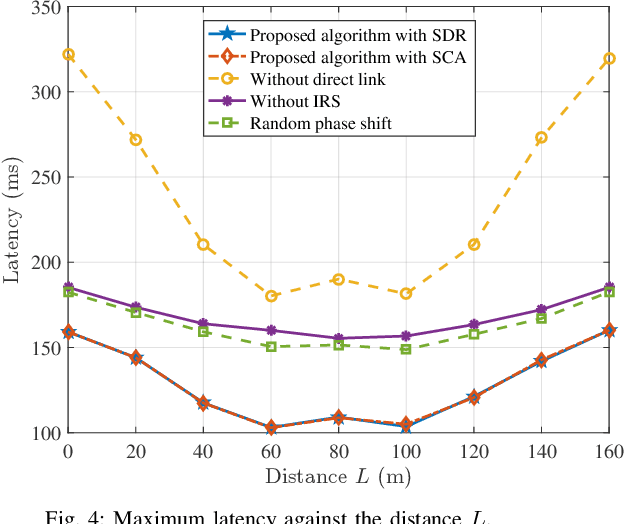
Mobile-edge computing (MEC) is expected to provide low-latency computation service for wireless devices (WDs). However, when WDs are located at cell edge or communication links between base stations (BSs) and WDs are blocked, the offloading latency will be large. To address this issue, we propose an intelligent reflecting surface (IRS)-assisted cell-free MEC system consisting of multiple BSs and IRSs for improving the transmission environment. Consequently, we formulate a min-max latency optimization problem by jointly designing multi-user detection (MUD) matrices, IRSs' reflecting beamforming vectors, WDs' transmit power and edge computing resource, subject to constraints on edge computing capability and IRSs phase shifts. To solve it, an alternating optimization algorithm based on the block coordinate descent (BCD) technique is proposed, in which the original non-convex problem is decoupled into two subproblems for alternately optimizing computing and communication parameters. In particular, we optimize the MUD matrix based on the second-order cone programming (SOCP) technique, and then develop two efficient algorithms to optimize IRSs' reflecting vectors based on the semi-definite relaxation (SDR) and successive convex approximation (SCA) techniques, respectively. Numerical results show that employing IRSs in cell-free MEC systems outperforms conventional MEC systems, resulting in up to about 60% latency reduction can be attained. Moreover, numerical results confirm that our proposed algorithms enjoy a fast convergence, which is beneficial for practical implementation.
Structural Correspondence Learning for Cross-lingual Sentiment Classification with One-to-many Mappings
Nov 26, 2016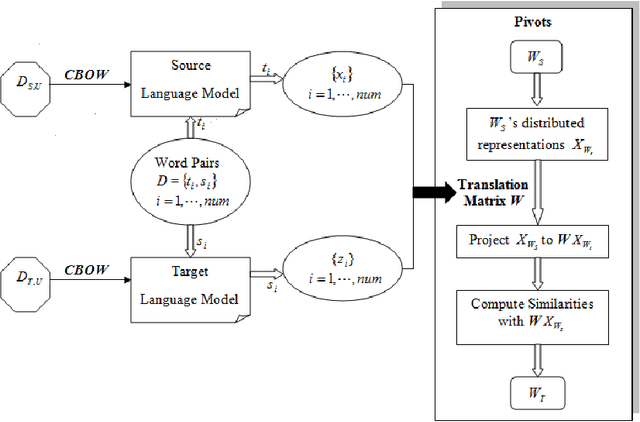
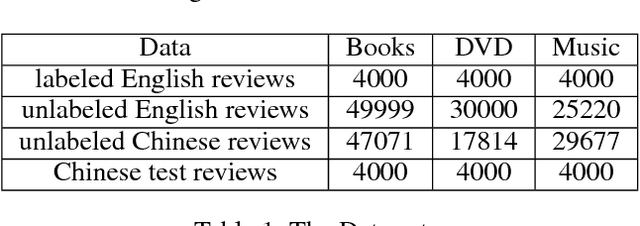
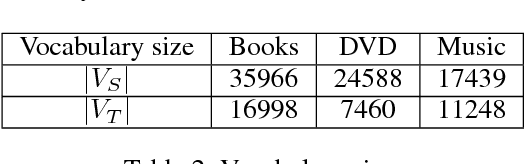
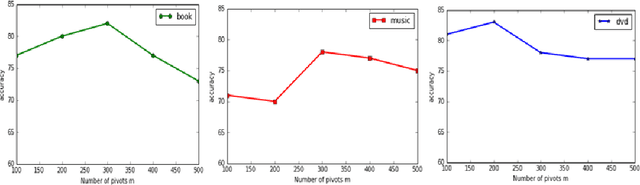
Structural correspondence learning (SCL) is an effective method for cross-lingual sentiment classification. This approach uses unlabeled documents along with a word translation oracle to automatically induce task specific, cross-lingual correspondences. It transfers knowledge through identifying important features, i.e., pivot features. For simplicity, however, it assumes that the word translation oracle maps each pivot feature in source language to exactly only one word in target language. This one-to-one mapping between words in different languages is too strict. Also the context is not considered at all. In this paper, we propose a cross-lingual SCL based on distributed representation of words; it can learn meaningful one-to-many mappings for pivot words using large amounts of monolingual data and a small dictionary. We conduct experiments on NLP\&CC 2013 cross-lingual sentiment analysis dataset, employing English as source language, and Chinese as target language. Our method does not rely on the parallel corpora and the experimental results show that our approach is more competitive than the state-of-the-art methods in cross-lingual sentiment classification.