 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Correspondence Learning for Cross-lingual Sentiment Classification with One-to-many Mappings
Paper and Code
Nov 26, 2016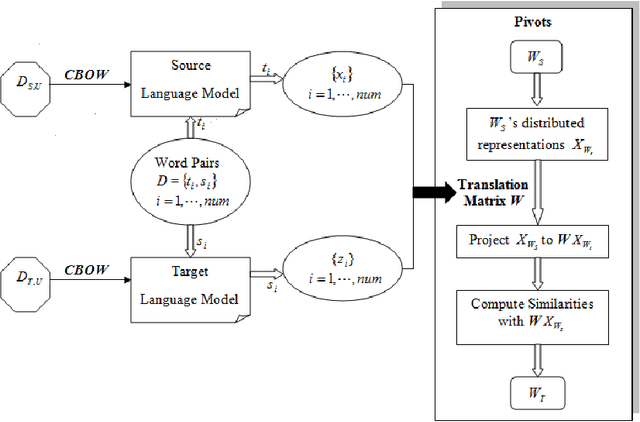
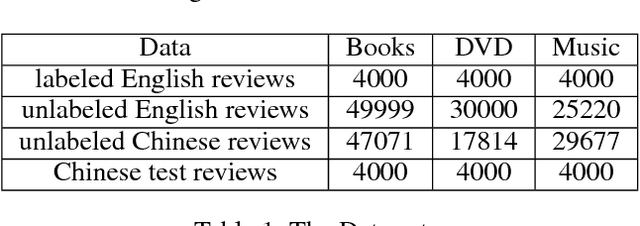
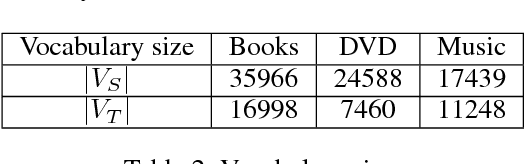
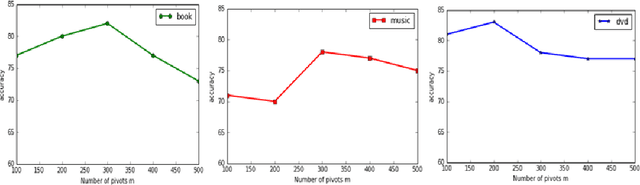
Structural correspondence learning (SCL) is an effective method for cross-lingual sentiment classification. This approach uses unlabeled documents along with a word translation oracle to automatically induce task specific, cross-lingual correspondences. It transfers knowledge through identifying important features, i.e., pivot features. For simplicity, however, it assumes that the word translation oracle maps each pivot feature in source language to exactly only one word in target language. This one-to-one mapping between words in different languages is too strict. Also the context is not considered at all. In this paper, we propose a cross-lingual SCL based on distributed representation of words; it can learn meaningful one-to-many mappings for pivot words using large amounts of monolingual data and a small dictionary. We conduct experiments on NLP\&CC 2013 cross-lingual sentiment analysis dataset, employing English as source language, and Chinese as target language. Our method does not rely on the parallel corpora and the experimental results show that our approach is more competitive than the state-of-the-art methods in cross-lingual sentiment classification.