 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Breast Lesion Classification by Joint Neural Analysis of Mammography and Ultrasound
Sep 23, 2020
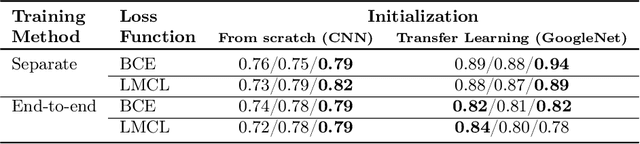
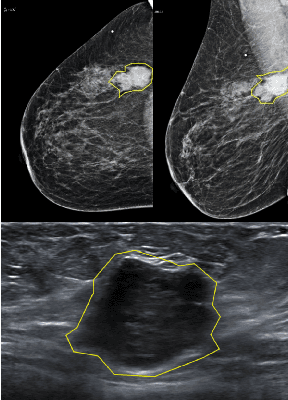
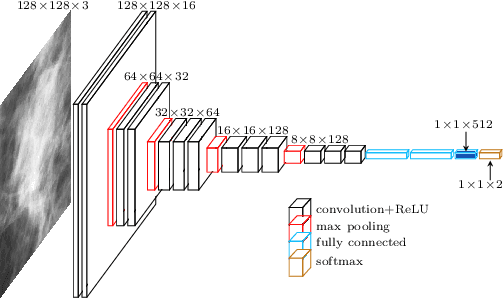
Mammography and ultrasound are extensively used by radiologists as complementary modalities to achieve better performance in breast cancer diagnosis. However, existing computer-aided diagnosis (CAD) systems for the breast are generally based on a single modality. In this work, we propose a deep-learning based method for classifying breast cancer lesions from their respective mammography and ultrasound images. We present various approaches and show a consistent improvement in performance when utilizing both modalities. The proposed approach is based on a GoogleNet architecture, fine-tuned for our data in two training steps. First, a distinct neural network is trained separately for each modality, generating high-level features. Then, the aggregated features originating from each modality are used to train a multimodal network to provide the final classification. In quantitative experiments, the proposed approach achieves an AUC of 0.94, outperforming state-of-the-art models trained over a single modality. Moreover, it performs similarly to an average radiologist, surpassing two out of four radiologists participating in a reader study. The promising results suggest that the proposed method may become a valuable decision support tool for breast radiologists.
Labeling of Multilingual Breast MRI Reports
Jul 06, 2020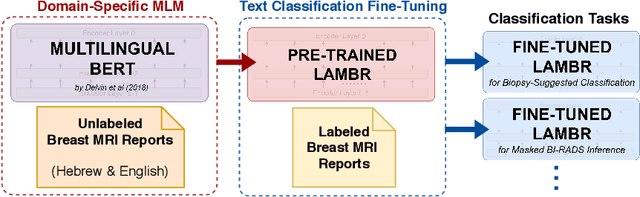
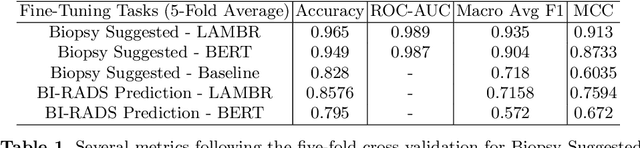
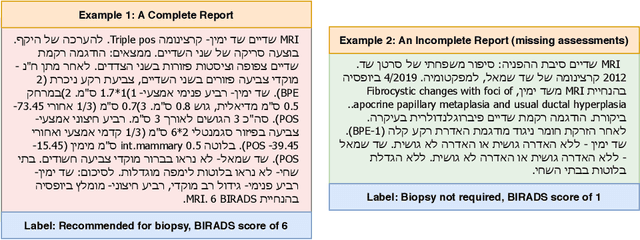
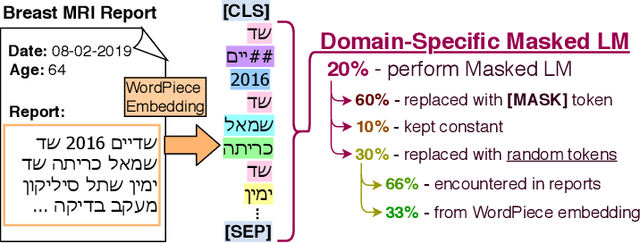
Medical reports are an essential medium in recording a patient's condition throughout a clinical trial. They contain valuable information that can be extracted to generate a large labeled dataset needed for the development of clinical tools. However, the majority of medical reports are stored in an unregularized format, and a trained human annotator (typically a doctor) must manually assess and label each case, resulting in an expensive and time consuming procedure. In this work, we present a framework for developing a multilingual breast MRI report classifier using a custom-built language representation called LAMBR. Our proposed method overcomes practical challenges faced in clinical settings, and we demonstrate improved performance in extracting labels from medical reports when compared with conventional approaches.
Knee Injury Detection using MRI with Efficiently-Layered Network (ELNet)
May 06, 2020
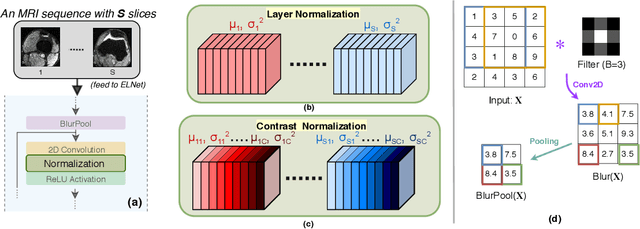
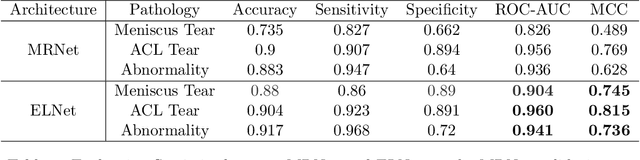
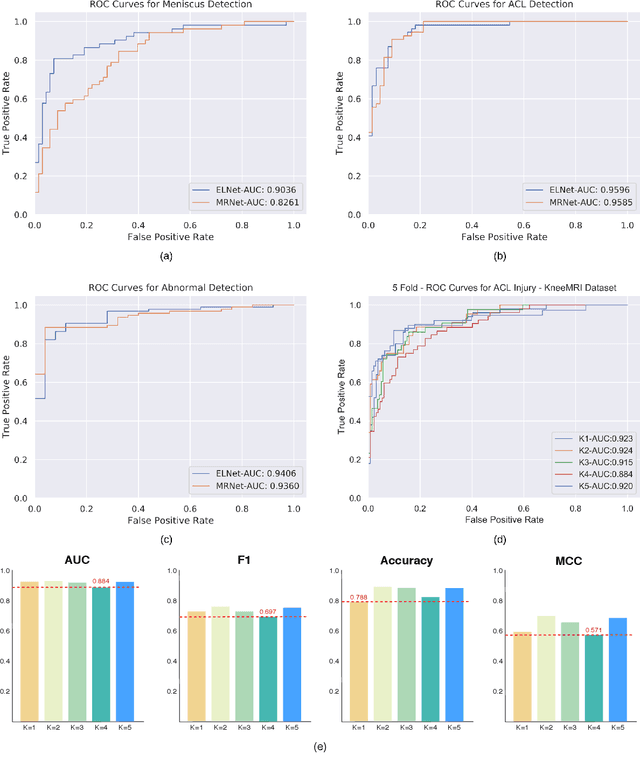
Magnetic Resonance Imaging (MRI) is a widely-accepted imaging technique for knee injury analysis. Its advantage of capturing knee structure in three dimensions makes it the ideal tool for radiologists to locate potential tears in the knee. In order to better confront the ever growing workload of musculoskeletal (MSK) radiologists, automated tools for patients' triage are becoming a real need, reducing delays in the reading of pathological cases. In this work, we present the Efficiently-Layered Network (ELNet), a convolutional neural network (CNN) architecture optimized for the task of initial knee MRI diagnosis for triage. Unlike past approaches, we train ELNet from scratch instead of using a transfer-learning approach. The proposed method is validated quantitatively and qualitatively, and compares favorably against state-of-the-art MRNet while using a single imaging stack (axial or coronal) as input. Additionally, we demonstrate our model's capability to locate tears in the knee despite the absence of localization information during training. Lastly, the proposed model is extremely lightweight ($<$ 1MB) and therefore easy to train and deploy in real clinical settings.
Dataset Growth in Medical Image Analysis Research
Aug 21, 2019
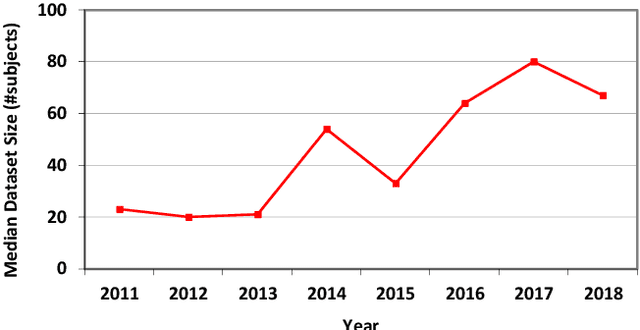
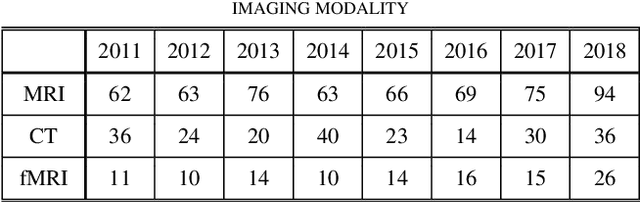

Medical image analysis studies usually require medical image datasets for training, testing and validation of algorithms. The need is underscored by the deep learning revolution and the dominance of machine learning in recent medical image analysis research. Nevertheless, due to ethical and legal constraints, commercial conflicts and the dependence on busy medical professionals, medical image analysis researchers have been described as "data starved". Due to the lack of objective criteria for sufficiency of dataset size, the research community implicitly sets ad-hoc standards by means of the peer review process. We hypothesize that peer review requires researchers to report the use of ever-increasing datasets as one condition for acceptance of their work to reputable publication venues. To test this hypothesis, we scanned the proceedings of the eminent MICCAI (Medical Image Computing and Computer-Assisted Intervention) conferences from 2011 to 2018. From a total of 2136 articles, we focused on 907 papers involving human datasets of MRI (Magnetic Resonance Imaging), CT (Computed Tomography) and fMRI (functional MRI) images. For each modality, for each of the years 2011-2018 we calculated the average, geometric mean and median number of human subjects used in that year's MICCAI articles. The results corroborate the dataset growth hypothesis. Specifically, the annual median dataset size in MICCAI articles has grown roughly 3-10 times from 2011 to 2018, depending on the imaging modality. Statistical analysis further supports the dataset growth hypothesis and reveals exponential growth of the geometric mean dataset size, with annual growth of about 21% for MRI, 24% for CT and 31% for fMRI. In slight analogy to Moore's law, the results can provide guidance about trends in the expectations of the medical image analysis community regarding dataset size.
Fast and easy blind deblurring using an inverse filter and PROBE
Feb 04, 2017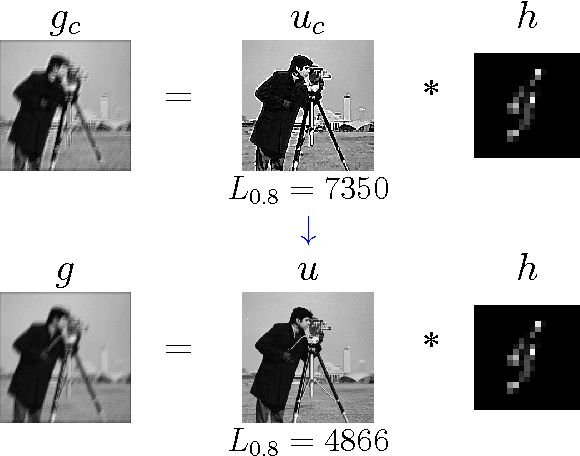
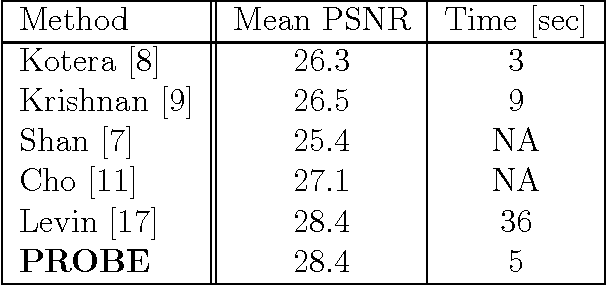

PROBE (Progressive Removal of Blur Residual) is a recursive framework for blind deblurring. Using the elementary modified inverse filter at its core, PROBE's experimental performance meets or exceeds the state of the art, both visually and quantitatively. Remarkably, PROBE lends itself to analysis that reveals its convergence properties. PROBE is motivated by recent ideas on progressive blind deblurring, but breaks away from previous research by its simplicity, speed, performance and potential for analysis. PROBE is neither a functional minimization approach, nor an open-loop sequential method (blur kernel estimation followed by non-blind deblurring). PROBE is a feedback scheme, deriving its unique strength from the closed-loop architecture rather than from the accuracy of its algorithmic components.
Crossing the Road Without Traffic Lights: An Android-based Safety Device
Oct 11, 2016

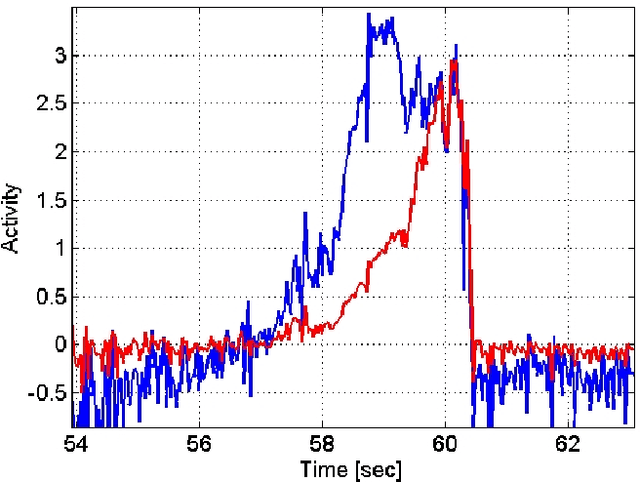
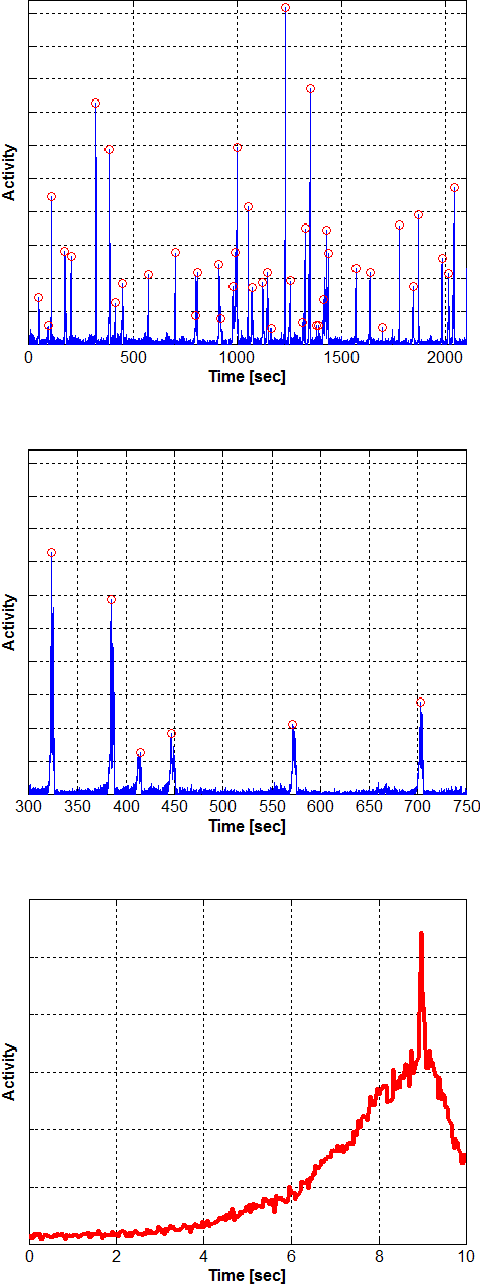
In the absence of pedestrian crossing lights, finding a safe moment to cross the road is often hazardous and challenging, especially for people with visual impairments. We present a reliable low-cost solution, an Android device attached to a traffic sign or lighting pole near the crossing, indicating whether it is safe to cross the road. The indication can be by sound, display, vibration, and various communication modalities provided by the Android device. The integral system camera is aimed at approaching traffic. Optical flow is computed from the incoming video stream, and projected onto an influx map, automatically acquired during a brief training period. The crossing safety is determined based on a 1-dimensional temporal signal derived from the projection. We implemented the complete system on a Samsung Galaxy K-Zoom Android smartphone, and obtained real-time operation. The system achieves promising experimental results, providing pedestrians with sufficiently early warning of approaching vehicles. The system can serve as a stand-alone safety device, that can be installed where pedestrian crossing lights are ruled out. Requiring no dedicated infrastructure, it can be powered by a solar panel and remotely maintained via the cellular network.