 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Controllable Image Restoration Networks
Dec 21, 2020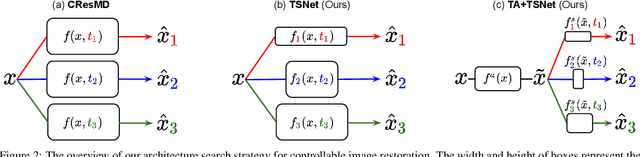


Diverse user preferences over images have recently led to a great amount of interest in controlling the imagery effects for image restoration tasks. However, existing methods require separate inference through the entire network per each output, which hinders users from readily comparing multiple imagery effects due to long latency. To this end, we propose a novel framework based on a neural architecture search technique that enables efficient generation of multiple imagery effects via two stages of pruning: task-agnostic and task-specific pruning. Specifically, task-specific pruning learns to adaptively remove the irrelevant network parameters for each task, while task-agnostic pruning learns to find an efficient architecture by sharing the early layers of the network across different tasks. Since the shared layers allow for feature reuse, only a single inference of the task-agnostic layers is needed to generate multiple imagery effects from the input image. Using the proposed task-agnostic and task-specific pruning schemes together significantly reduces the FLOPs and the actual latency of inference compared to the baseline. We reduce 95.7% of the FLOPs when generating 27 imagery effects, and make the GPU latency 73.0% faster on 4K-resolution images.
DynaVSR: Dynamic Adaptive Blind Video Super-Resolution
Nov 09, 2020
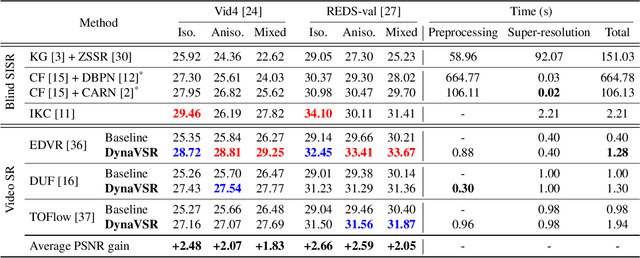

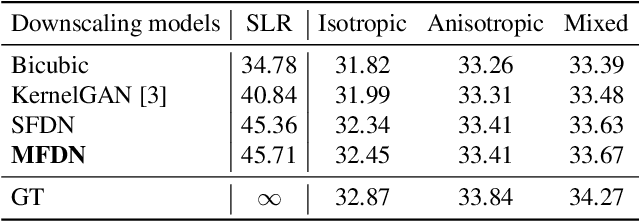
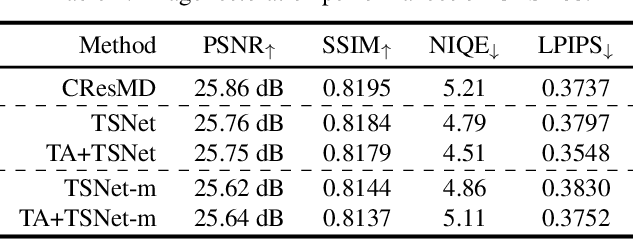
Most conventional supervised super-resolution (SR) algorithms assume that low-resolution (LR) data is obtained by downscaling high-resolution (HR) data with a fixed known kernel, but such an assumption often does not hold in real scenarios. Some recent blind SR algorithms have been proposed to estimate different downscaling kernels for each input LR image. However, they suffer from heavy computational overhead, making them infeasible for direct application to videos. In this work, we present DynaVSR, a novel meta-learning-based framework for real-world video SR that enables efficient downscaling model estimation and adaptation to the current input. Specifically, we train a multi-frame downscaling module with various types of synthetic blur kernels, which is seamlessly combined with a video SR network for input-aware adaptation. Experimental results show that DynaVSR consistently improves the performance of the state-of-the-art video SR models by a large margin, with an order of magnitude faster inference time compared to the existing blind SR approaches.
Meta-Learning with Adaptive Hyperparameters
Oct 31, 2020
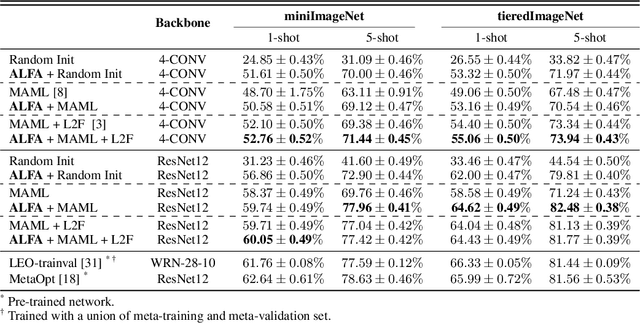
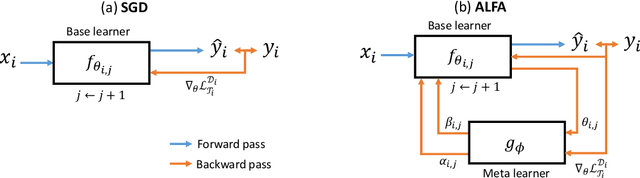

Despite its popularity, several recent works question the effectiveness of MAML when test tasks are different from training tasks, thus suggesting various task-conditioned methodology to improve the initialization. Instead of searching for better task-aware initialization, we focus on a complementary factor in MAML framework, inner-loop optimization (or fast adaptation). Consequently, we propose a new weight update rule that greatly enhances the fast adaptation process. Specifically, we introduce a small meta-network that can adaptively generate per-step hyperparameters: learning rate and weight decay coefficients. The experimental results validate that the Adaptive Learning of hyperparameters for Fast Adaptation (ALFA) is the equally important ingredient that was often neglected in the recent few-shot learning approaches. Surprisingly, fast adaptation from random initialization with ALFA can already outperform MAML.
Scene-Adaptive Video Frame Interpolation via Meta-Learning
Apr 02, 2020

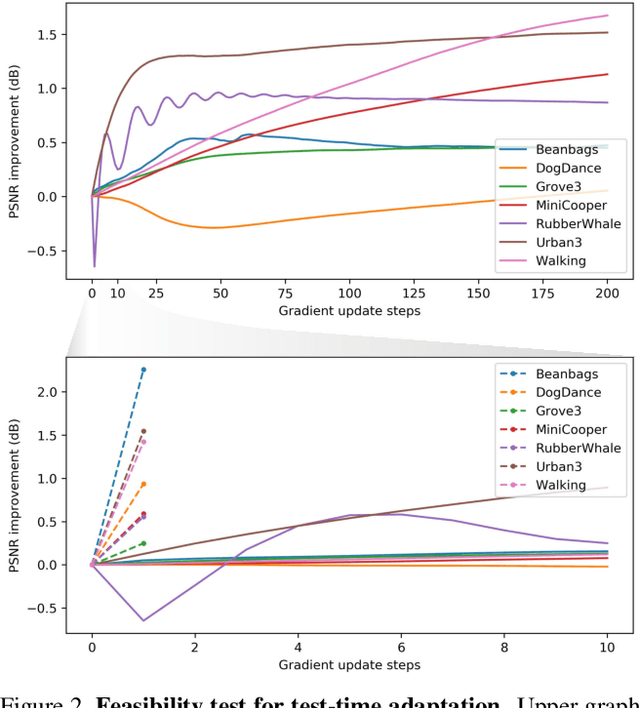

Video frame interpolation is a challenging problem because there are different scenarios for each video depending on the variety of foreground and background motion, frame rate, and occlusion. It is therefore difficult for a single network with fixed parameters to generalize across different videos. Ideally, one could have a different network for each scenario, but this is computationally infeasible for practical applications. In this work, we propose to adapt the model to each video by making use of additional information that is readily available at test time and yet has not been exploited in previous works. We first show the benefits of `test-time adaptation' through simple fine-tuning of a network, then we greatly improve its efficiency by incorporating meta-learning. We obtain significant performance gains with only a single gradient update without any additional parameters. Finally, we show that our meta-learning framework can be easily employed to any video frame interpolation network and can consistently improve its performance on multiple benchmark datasets.