 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing neural networks as mappings of correlation functions
Feb 10, 2022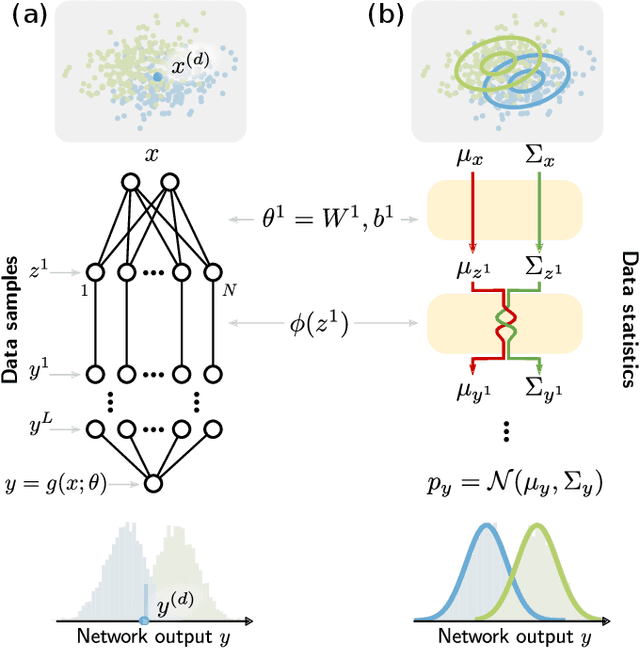
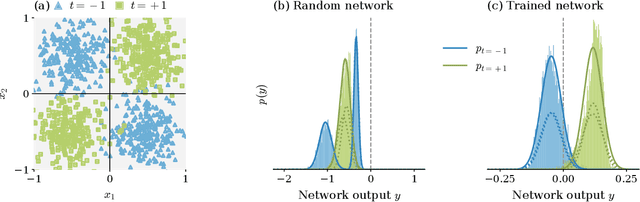
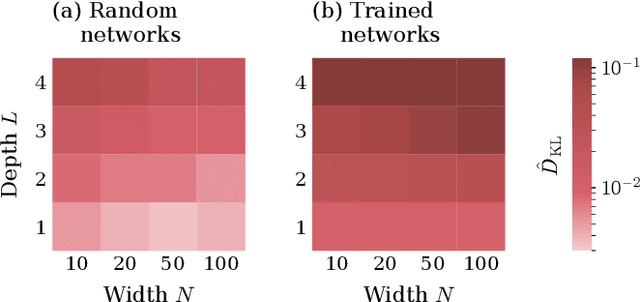
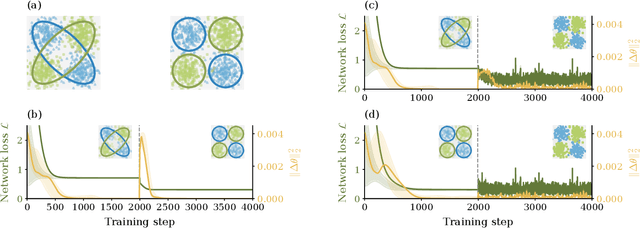
Understanding the functional principles of information processing in deep neural networks continues to be a challenge, in particular for networks with trained and thus non-random weights. To address this issue, we study the mapping between probability distributions implemented by a deep feed-forward network. We characterize this mapping as an iterated transformation of distributions, where the non-linearity in each layer transfers information between different orders of correlation functions. This allows us to identify essential statistics in the data, as well as different information representations that can be used by neural networks. Applied to an XOR task and to MNIST, we show that correlations up to second order predominantly capture the information processing in the internal layers, while the input layer also extracts higher-order correlations from the data. This analysis provides a quantitative and explainable perspective on classification.