 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARUBA: An Architecture-Agnostic Balanced Loss for Aerial Object Detection
Oct 10, 2022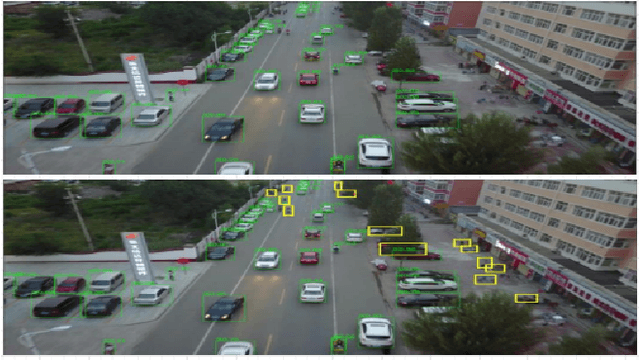
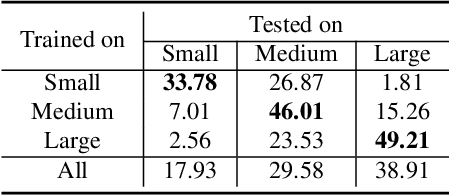
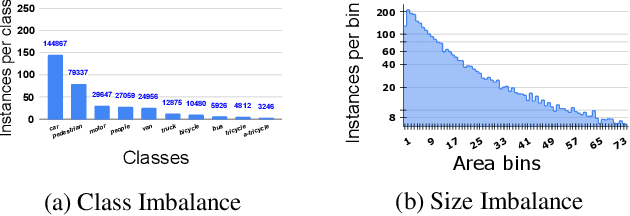

Deep neural networks tend to reciprocate the bias of their training dataset. In object detection, the bias exists in the form of various imbalances such as class, background-foreground, and object size. In this paper, we denote size of an object as the number of pixels it covers in an image and size imbalance as the over-representation of certain sizes of objects in a dataset. We aim to address the problem of size imbalance in drone-based aerial image datasets. Existing methods for solving size imbalance are based on architectural changes that utilize multiple scales of images or feature maps for detecting objects of different sizes. We, on the other hand, propose a novel ARchitectUre-agnostic BAlanced Loss (ARUBA) that can be applied as a plugin on top of any object detection model. It follows a neighborhood-driven approach inspired by the ordinality of object size. We evaluate the effectiveness of our approach through comprehensive experiments on aerial datasets such as HRSC2016, DOTAv1.0, DOTAv1.5 and VisDrone and obtain consistent improvement in performance.
Proto2Proto: Can you recognize the car, the way I do?
May 02, 2022

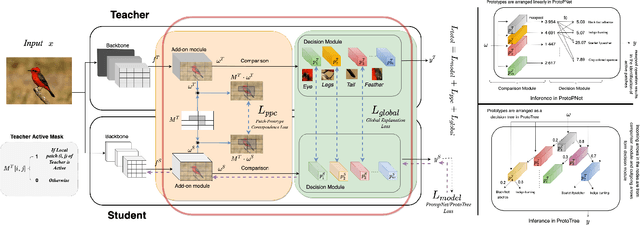
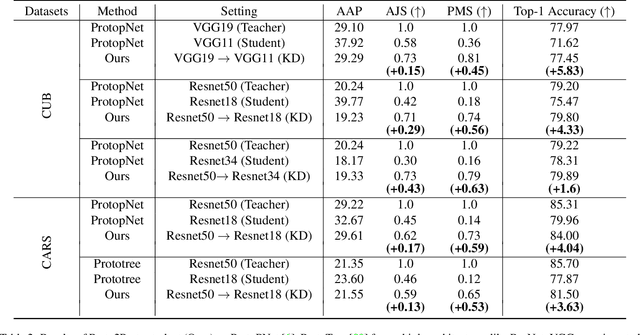
Prototypical methods have recently gained a lot of attention due to their intrinsic interpretable nature, which is obtained through the prototypes. With growing use cases of model reuse and distillation, there is a need to also study transfer of interpretability from one model to another. We present Proto2Proto, a novel method to transfer interpretability of one prototypical part network to another via knowledge distillation. Our approach aims to add interpretability to the "dark" knowledge transferred from the teacher to the shallower student model. We propose two novel losses: "Global Explanation" loss and "Patch-Prototype Correspondence" loss to facilitate such a transfer. Global Explanation loss forces the student prototypes to be close to teacher prototypes, and Patch-Prototype Correspondence loss enforces the local representations of the student to be similar to that of the teacher. Further, we propose three novel metrics to evaluate the student's proximity to the teacher as measures of interpretability transfer in our settings. We qualitatively and quantitatively demonstrate the effectiveness of our method on CUB-200-2011 and Stanford Cars datasets. Our experiments show that the proposed method indeed achieves interpretability transfer from teacher to student while simultaneously exhibiting competitive performance.
Beyond Classification: Knowledge Distillation using Multi-Object Impressions
Oct 27, 2021
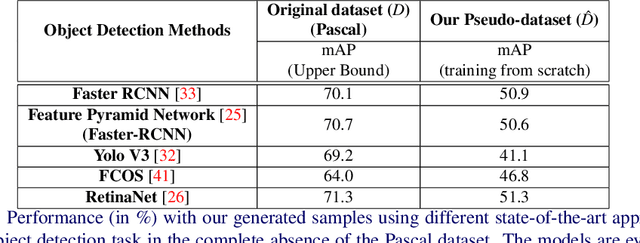
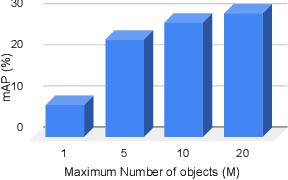
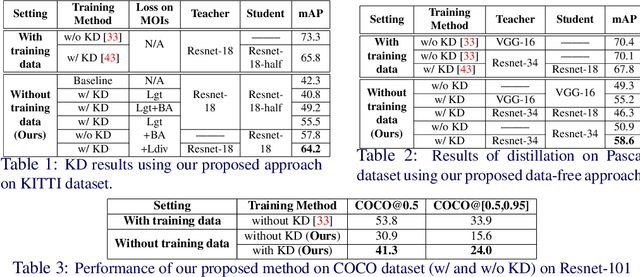
Knowledge Distillation (KD) utilizes training data as a transfer set to transfer knowledge from a complex network (Teacher) to a smaller network (Student). Several works have recently identified many scenarios where the training data may not be available due to data privacy or sensitivity concerns and have proposed solutions under this restrictive constraint for the classification task. Unlike existing works, we, for the first time, solve a much more challenging problem, i.e., "KD for object detection with zero knowledge about the training data and its statistics". Our proposed approach prepares pseudo-targets and synthesizes corresponding samples (termed as "Multi-Object Impressions"), using only the pretrained Faster RCNN Teacher network. We use this pseudo-dataset as a transfer set to conduct zero-shot KD for object detection. We demonstrate the efficacy of our proposed method through several ablations and extensive experiments on benchmark datasets like KITTI, Pascal and COCO. Our approach with no training samples, achieves a respectable mAP of 64.2% and 55.5% on the student with same and half capacity while performing distillation from a Resnet-18 Teacher of 73.3% mAP on KITTI.