 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Knowledge Distillation using Multi-Object Impressions
Paper and Code
Oct 27, 2021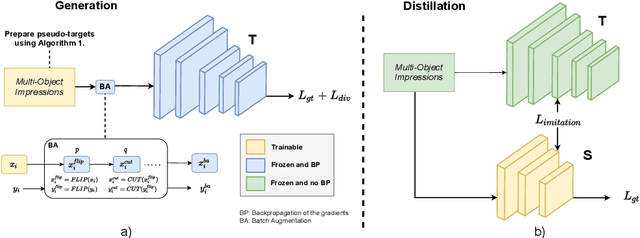
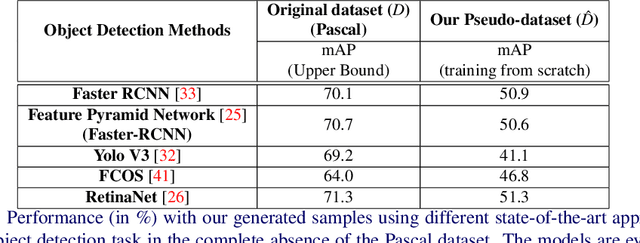
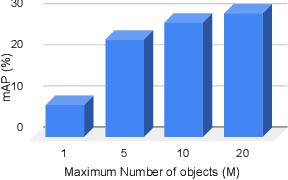
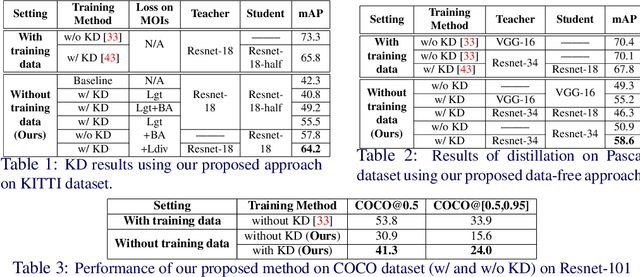
Knowledge Distillation (KD) utilizes training data as a transfer set to transfer knowledge from a complex network (Teacher) to a smaller network (Student). Several works have recently identified many scenarios where the training data may not be available due to data privacy or sensitivity concerns and have proposed solutions under this restrictive constraint for the classification task. Unlike existing works, we, for the first time, solve a much more challenging problem, i.e., "KD for object detection with zero knowledge about the training data and its statistics". Our proposed approach prepares pseudo-targets and synthesizes corresponding samples (termed as "Multi-Object Impressions"), using only the pretrained Faster RCNN Teacher network. We use this pseudo-dataset as a transfer set to conduct zero-shot KD for object detection. We demonstrate the efficacy of our proposed method through several ablations and extensive experiments on benchmark datasets like KITTI, Pascal and COCO. Our approach with no training samples, achieves a respectable mAP of 64.2% and 55.5% on the student with same and half capacity while performing distillation from a Resnet-18 Teacher of 73.3% mAP on KITTI.