 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Analysis of NetFlow Datasets for Network Intrusion Detection Systems
Mar 06, 2025This paper investigates the temporal analysis of NetFlow datasets for machine learning (ML)-based network intrusion detection systems (NIDS). Although many previous studies have highlighted the critical role of temporal features, such as inter-packet arrival time and flow length/duration, in NIDS, the currently available NetFlow datasets for NIDS lack these temporal features. This study addresses this gap by creating and making publicly available a set of NetFlow datasets that incorporate these temporal features [1]. With these temporal features, we provide a comprehensive temporal analysis of NetFlow datasets by examining the distribution of various features over time and presenting time-series representations of NetFlow features. This temporal analysis has not been previously provided in the existing literature. We also borrowed an idea from signal processing, time frequency analysis, and tested it to see how different the time frequency signal presentations (TFSPs) are for various attacks. The results indicate that many attacks have unique patterns, which could help ML models to identify them more easily.
FlowTransformer: A Transformer Framework for Flow-based Network Intrusion Detection Systems
Apr 28, 2023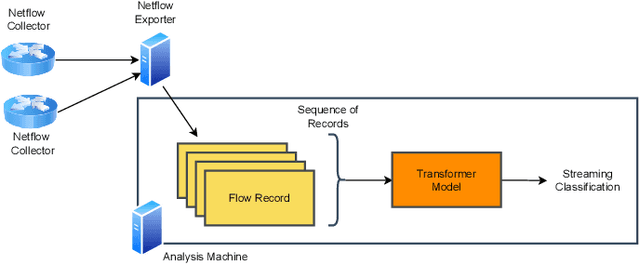
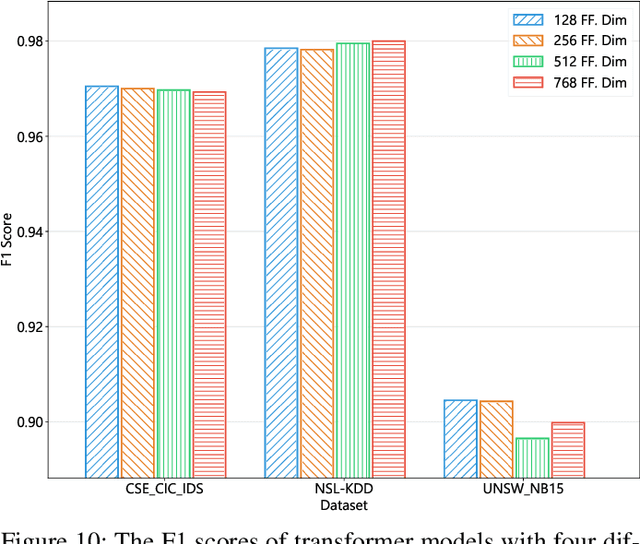
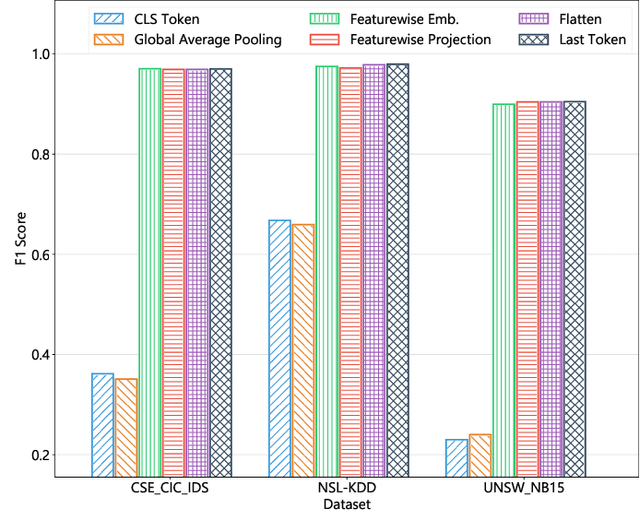
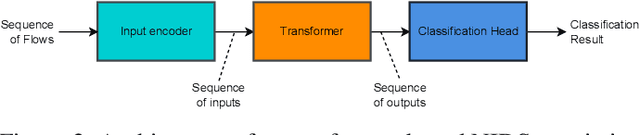
This paper presents the FlowTransformer framework, a novel approach for implementing transformer-based Network Intrusion Detection Systems (NIDSs). FlowTransformer leverages the strengths of transformer models in identifying the long-term behaviour and characteristics of networks, which are often overlooked by most existing NIDSs. By capturing these complex patterns in network traffic, FlowTransformer offers a flexible and efficient tool for researchers and practitioners in the cybersecurity community who are seeking to implement NIDSs using transformer-based models. FlowTransformer allows the direct substitution of various transformer components, including the input encoding, transformer, classification head, and the evaluation of these across any flow-based network dataset. To demonstrate the effectiveness and efficiency of the FlowTransformer framework, we utilise it to provide an extensive evaluation of various common transformer architectures, such as GPT 2.0 and BERT, on three commonly used public NIDS benchmark datasets. We provide results for accuracy, model size and speed. A key finding of our evaluation is that the choice of classification head has the most significant impact on the model performance. Surprisingly, Global Average Pooling, which is commonly used in text classification, performs very poorly in the context of NIDS. In addition, we show that model size can be reduced by over 50\%, and inference and training times improved, with no loss of accuracy, by making specific choices of input encoding and classification head instead of other commonly used alternatives.
DOC-NAD: A Hybrid Deep One-class Classifier for Network Anomaly Detection
Dec 15, 2022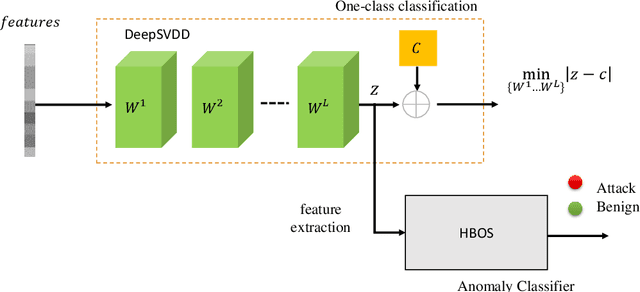

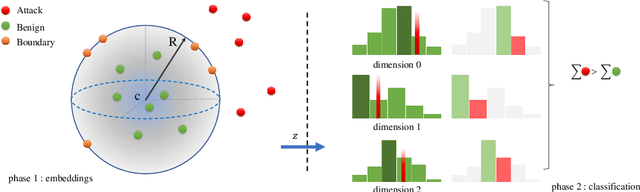
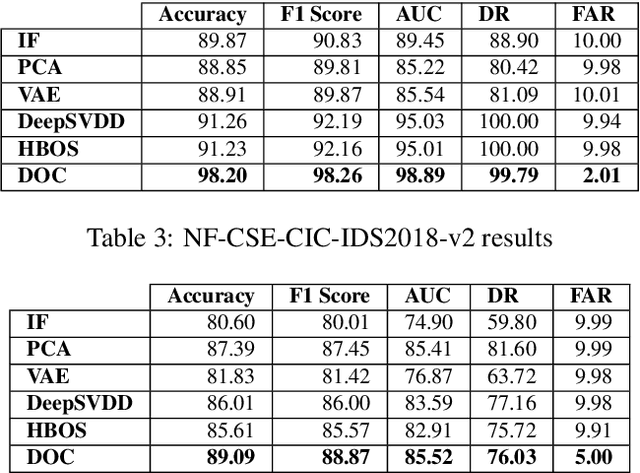
Machine Learning (ML) approaches have been used to enhance the detection capabilities of Network Intrusion Detection Systems (NIDSs). Recent work has achieved near-perfect performance by following binary- and multi-class network anomaly detection tasks. Such systems depend on the availability of both (benign and malicious) network data classes during the training phase. However, attack data samples are often challenging to collect in most organisations due to security controls preventing the penetration of known malicious traffic to their networks. Therefore, this paper proposes a Deep One-Class (DOC) classifier for network intrusion detection by only training on benign network data samples. The novel one-class classification architecture consists of a histogram-based deep feed-forward classifier to extract useful network data features and use efficient outlier detection. The DOC classifier has been extensively evaluated using two benchmark NIDS datasets. The results demonstrate its superiority over current state-of-the-art one-class classifiers in terms of detection and false positive rates.
XG-BoT: An Explainable Deep Graph Neural Network for Botnet Detection and Forensics
Jul 19, 2022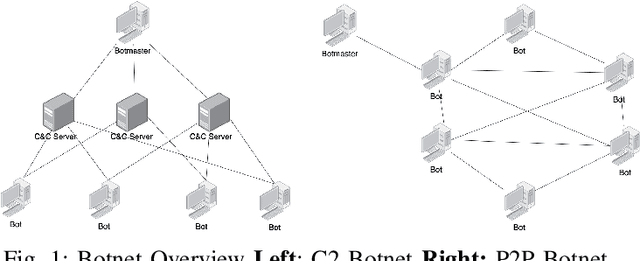

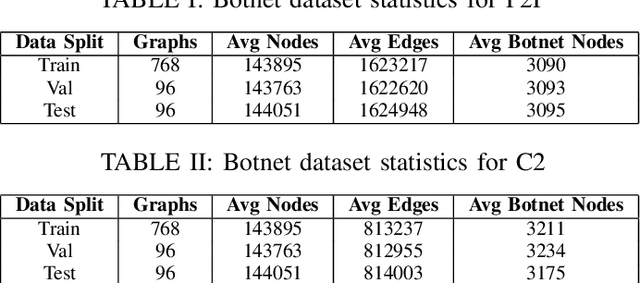

In this paper, we proposed XG-BoT, an explainable deep graph neural network model for botnet node detection. The proposed model is mainly composed of a botnet detector and an explainer for automatic forensics. The XG-BoT detector can effectively detect malicious botnet nodes under large-scale networks. Specifically, it utilizes a grouped reversible residual connection with a graph isomorphism network to learn expressive node representations from the botnet communication graphs. The explainer in XG-BoT can perform automatic network forensics by highlighting suspicious network flows and related botnet nodes. We evaluated XG-BoT on real-world, large-scale botnet network graphs. Overall, XG-BoT is able to outperform the state-of-the-art in terms of evaluation metrics. In addition, we show that the XG-BoT explainer can generate useful explanations based on GNNExplainer for automatic network forensics.
HBFL: A Hierarchical Blockchain-based Federated Learning Framework for a Collaborative IoT Intrusion Detection
Apr 08, 2022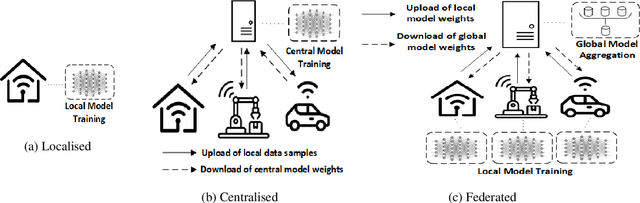
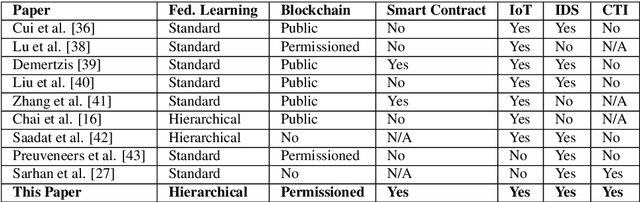
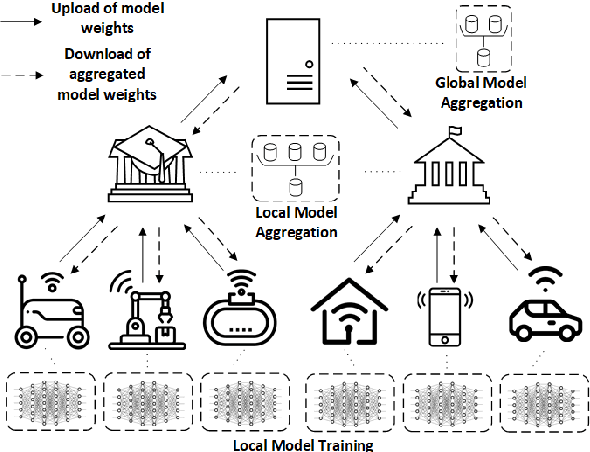
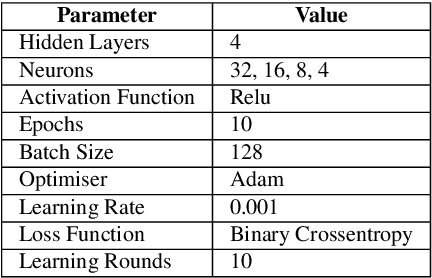
The continuous strengthening of the security posture of IoT ecosystems is vital due to the increasing number of interconnected devices and the volume of sensitive data shared. The utilisation of Machine Learning (ML) capabilities in the defence against IoT cyber attacks has many potential benefits. However, the currently proposed frameworks do not consider data privacy, secure architectures, and/or scalable deployments of IoT ecosystems. In this paper, we propose a hierarchical blockchain-based federated learning framework to enable secure and privacy-preserved collaborative IoT intrusion detection. We highlight and demonstrate the importance of sharing cyber threat intelligence among inter-organisational IoT networks to improve the model's detection capabilities. The proposed ML-based intrusion detection framework follows a hierarchical federated learning architecture to ensure the privacy of the learning process and organisational data. The transactions (model updates) and processes will run on a secure immutable ledger, and the conformance of executed tasks will be verified by the smart contract. We have tested our solution and demonstrated its feasibility by implementing it and evaluating the intrusion detection performance using a key IoT data set. The outcome is a securely designed ML-based intrusion detection system capable of detecting a wide range of malicious activities while preserving data privacy.
Graph Neural Network-based Android Malware Classification with Jumping Knowledge
Feb 08, 2022



This paper presents a new Android malware detection method based on Graph Neural Networks (GNNs) with Jumping-Knowledge (JK). Android function call graphs (FCGs) consist of a set of program functions and their inter-procedural calls. Thus, this paper proposes a GNN-based method for Android malware detection by capturing meaningful intra-procedural call path patterns. In addition, a Jumping-Knowledge technique is applied to minimize the effect of the over-smoothing problem, which is common in GNNs. The proposed method has been extensively evaluated using two benchmark datasets. The results demonstrate the superiority of our approach compared to state-of-the-art approaches in terms of key classification metrics, which demonstrates the potential of GNNs in Android malware detection and classification.
A Cyber Threat Intelligence Sharing Scheme based on Federated Learning for Network Intrusion Detection
Nov 04, 2021

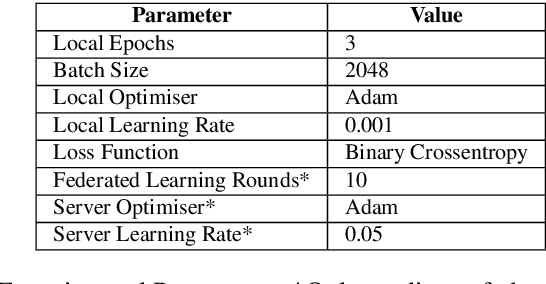
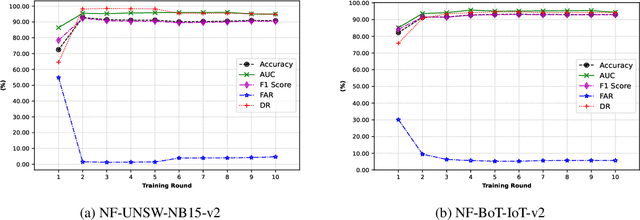
The uses of Machine Learning (ML) in detection of network attacks have been effective when designed and evaluated in a single organisation. However, it has been very challenging to design an ML-based detection system by utilising heterogeneous network data samples originating from several sources. This is mainly due to privacy concerns and the lack of a universal format of datasets. In this paper, we propose a collaborative federated learning scheme to address these issues. The proposed framework allows multiple organisations to join forces in the design, training, and evaluation of a robust ML-based network intrusion detection system. The threat intelligence scheme utilises two critical aspects for its application; the availability of network data traffic in a common format to allow for the extraction of meaningful patterns across data sources. Secondly, the adoption of a federated learning mechanism to avoid the necessity of sharing sensitive users' information between organisations. As a result, each organisation benefits from other organisations cyber threat intelligence while maintaining the privacy of its data internally. The model is trained locally and only the updated weights are shared with the remaining participants in the federated averaging process. The framework has been designed and evaluated in this paper by using two key datasets in a NetFlow format known as NF-UNSW-NB15-v2 and NF-BoT-IoT-v2. Two other common scenarios are considered in the evaluation process; a centralised training method where the local data samples are shared with other organisations and a localised training method where no threat intelligence is shared. The results demonstrate the efficiency and effectiveness of the proposed framework by designing a universal ML model effectively classifying benign and intrusive traffic originating from multiple organisations without the need for local data exchange.
From Zero-Shot Machine Learning to Zero-Day Attack Detection
Sep 30, 2021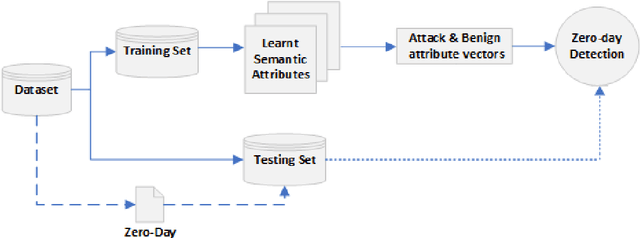
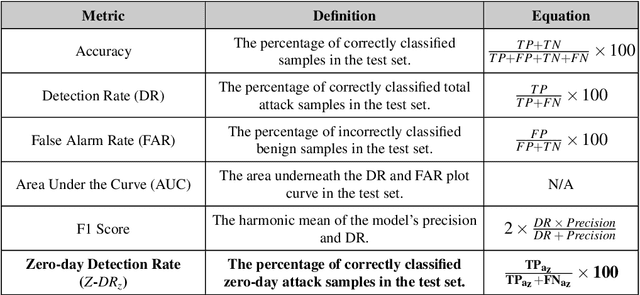

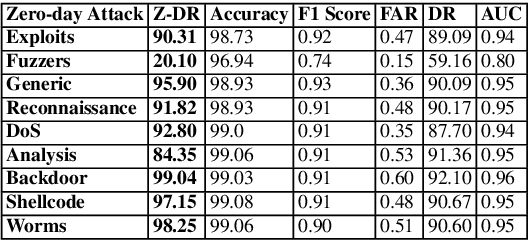
The standard ML methodology assumes that the test samples are derived from a set of pre-observed classes used in the training phase. Where the model extracts and learns useful patterns to detect new data samples belonging to the same data classes. However, in certain applications such as Network Intrusion Detection Systems, it is challenging to obtain data samples for all attack classes that the model will most likely observe in production. ML-based NIDSs face new attack traffic known as zero-day attacks, that are not used in the training of the learning models due to their non-existence at the time. In this paper, a zero-shot learning methodology has been proposed to evaluate the ML model performance in the detection of zero-day attack scenarios. In the attribute learning stage, the ML models map the network data features to distinguish semantic attributes from known attack (seen) classes. In the inference stage, the models are evaluated in the detection of zero-day attack (unseen) classes by constructing the relationships between known attacks and zero-day attacks. A new metric is defined as Zero-day Detection Rate, which measures the effectiveness of the learning model in the inference stage. The results demonstrate that while the majority of the attack classes do not represent significant risks to organisations adopting an ML-based NIDS in a zero-day attack scenario. However, for certain attack groups identified in this paper, such systems are not effective in applying the learnt attributes of attack behaviour to detect them as malicious. Further Analysis was conducted using the Wasserstein Distance technique to measure how different such attacks are from other attack types used in the training of the ML model. The results demonstrate that sophisticated attacks with a low zero-day detection rate have a significantly distinct feature distribution compared to the other attack classes.
Feature Analysis for ML-based IIoT Intrusion Detection
Aug 29, 2021
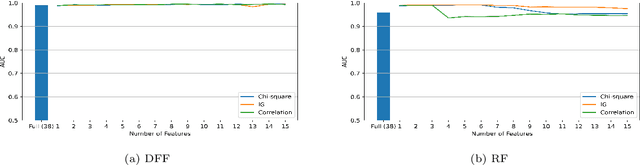

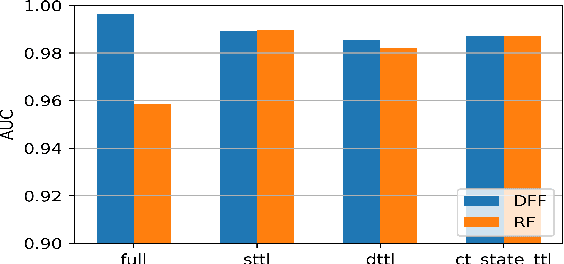
Industrial Internet of Things (IIoT) networks have become an increasingly attractive target of cyberattacks. Powerful Machine Learning (ML) models have recently been adopted to implement Network Intrusion Detection Systems (NIDSs), which can protect IIoT networks. For the successful training of such ML models, it is important to select the right set of data features, which maximise the detection accuracy as well as computational efficiency. This paper provides an extensive analysis of the optimal feature sets in terms of the importance and predictive power of network attacks. Three feature selection algorithms; chi-square, information gain and correlation have been utilised to identify and rank data features. The features are fed into two ML classifiers; deep feed-forward and random forest, to measure their attack detection accuracy. The experimental evaluation considered three NIDS datasets: UNSW-NB15, CSE-CIC-IDS2018, and ToN-IoT in their proprietary flow format. In addition, the respective variants in NetFlow format were also considered, i.e., NF-UNSW-NB15, NF-CSE-CIC-IDS2018, and NF-ToN-IoT. The experimental evaluation explored the marginal benefit of adding features one-by-one. Our results show that the accuracy initially increases rapidly with the addition of features, but converges quickly to the maximum achievable detection accuracy. Our results demonstrate a significant potential of reducing the computational and storage cost of NIDS while maintaining near-optimal detection accuracy. This has particular relevance in IIoT systems, with typically limited computational and storage resource.
Feature Extraction for Machine Learning-based Intrusion Detection in IoT Networks
Aug 28, 2021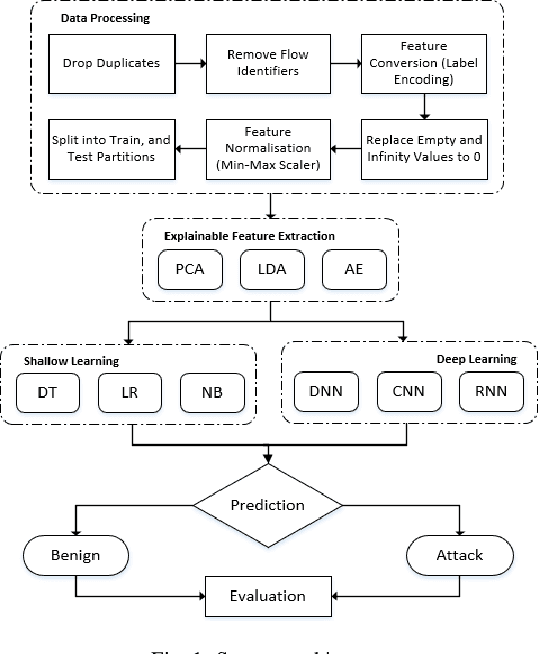
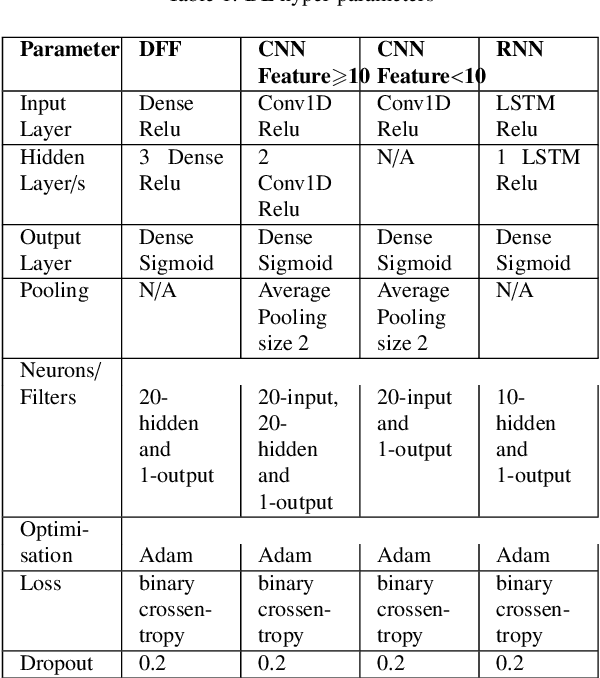
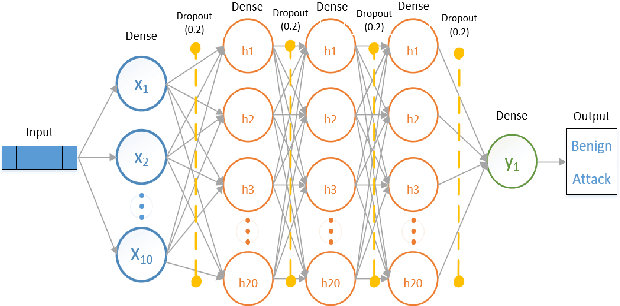
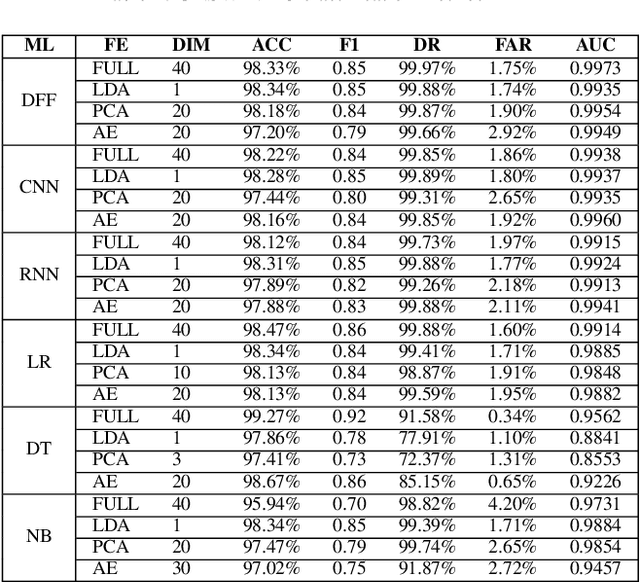
The tremendous numbers of network security breaches that have occurred in IoT networks have demonstrated the unreliability of current Network Intrusion Detection Systems (NIDSs). Consequently, network interruptions and loss of sensitive data have occurred which led to an active research area for improving NIDS technologies. During an analysis of related works, it was observed that most researchers aimed to obtain better classification results by using a set of untried combinations of Feature Reduction (FR) and Machine Learning (ML) techniques on NIDS datasets. However, these datasets are different in feature sets, attack types, and network design. Therefore, this paper aims to discover whether these techniques can be generalised across various datasets. Six ML models are utilised: a Deep Feed Forward, Convolutional Neural Network, Recurrent Neural Network, Decision Tree, Logistic Regression, and Naive Bayes. The detection accuracy of three Feature Extraction (FE) algorithms; Principal Component Analysis (PCA), Auto-encoder (AE), and Linear Discriminant Analysis (LDA) is evaluated using three benchmark datasets; UNSW-NB15, ToN-IoT and CSE-CIC-IDS2018. Although PCA and AE algorithms have been widely used, determining their optimal number of extracted dimensions has been overlooked. The results obtained indicate that there is no clear FE method or ML model that can achieve the best scores for all datasets. The optimal number of extracted dimensions has been identified for each dataset and LDA decreases the performance of the ML models on two datasets. The variance is used to analyse the extracted dimensions of LDA and PCA. Finally, this paper concludes that the choice of datasets significantly alters the performance of the applied techniques and we argue for the need for a universal (benchmark) feature set to facilitate further advancement and progress in this field of research.