 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUgly Ducklings or Swans: A Tiered Quadruplet Network with Patient-Specific Mining for Improved Skin Lesion Classification
Sep 18, 2023



An ugly duckling is an obviously different skin lesion from surrounding lesions of an individual, and the ugly duckling sign is a criterion used to aid in the diagnosis of cutaneous melanoma by differentiating between highly suspicious and benign lesions. However, the appearance of pigmented lesions, can change drastically from one patient to another, resulting in difficulties in visual separation of ugly ducklings. Hence, we propose DMT-Quadruplet - a deep metric learning network to learn lesion features at two tiers - patient-level and lesion-level. We introduce a patient-specific quadruplet mining approach together with a tiered quadruplet network, to drive the network to learn more contextual information both globally and locally between the two tiers. We further incorporate a dynamic margin within the patient-specific mining to allow more useful quadruplets to be mined within individuals. Comprehensive experiments show that our proposed method outperforms traditional classifiers, achieving 54% higher sensitivity than a baseline ResNet18 CNN and 37% higher than a naive triplet network in classifying ugly duckling lesions. Visualisation of the data manifold in the metric space further illustrates that DMT-Quadruplet is capable of classifying ugly duckling lesions in both patient-specific and patient-agnostic manner successfully.
FlowTransformer: A Transformer Framework for Flow-based Network Intrusion Detection Systems
Apr 28, 2023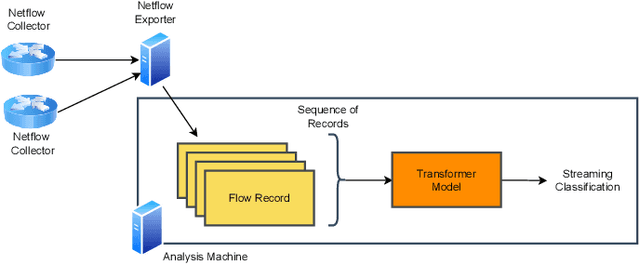
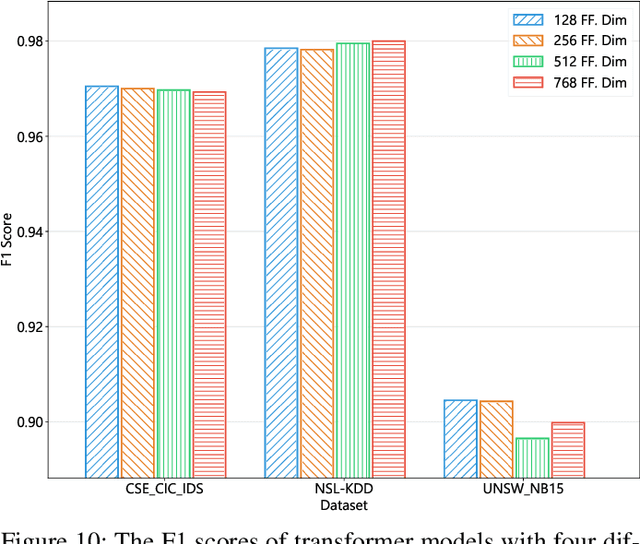
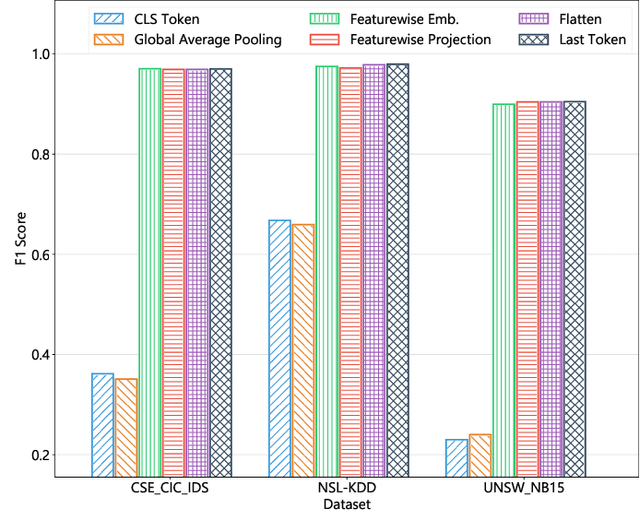
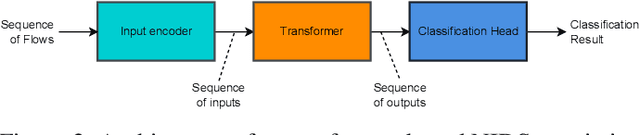
This paper presents the FlowTransformer framework, a novel approach for implementing transformer-based Network Intrusion Detection Systems (NIDSs). FlowTransformer leverages the strengths of transformer models in identifying the long-term behaviour and characteristics of networks, which are often overlooked by most existing NIDSs. By capturing these complex patterns in network traffic, FlowTransformer offers a flexible and efficient tool for researchers and practitioners in the cybersecurity community who are seeking to implement NIDSs using transformer-based models. FlowTransformer allows the direct substitution of various transformer components, including the input encoding, transformer, classification head, and the evaluation of these across any flow-based network dataset. To demonstrate the effectiveness and efficiency of the FlowTransformer framework, we utilise it to provide an extensive evaluation of various common transformer architectures, such as GPT 2.0 and BERT, on three commonly used public NIDS benchmark datasets. We provide results for accuracy, model size and speed. A key finding of our evaluation is that the choice of classification head has the most significant impact on the model performance. Surprisingly, Global Average Pooling, which is commonly used in text classification, performs very poorly in the context of NIDS. In addition, we show that model size can be reduced by over 50\%, and inference and training times improved, with no loss of accuracy, by making specific choices of input encoding and classification head instead of other commonly used alternatives.
NBC-Softmax : Darkweb Author fingerprinting and migration tracking
Dec 15, 2022Metric learning aims to learn distances from the data, which enhances the performance of similarity-based algorithms. An author style detection task is a metric learning problem, where learning style features with small intra-class variations and larger inter-class differences is of great importance to achieve better performance. Recently, metric learning based on softmax loss has been used successfully for style detection. While softmax loss can produce separable representations, its discriminative power is relatively poor. In this work, we propose NBC-Softmax, a contrastive loss based clustering technique for softmax loss, which is more intuitive and able to achieve superior performance. Our technique meets the criterion for larger number of samples, thus achieving block contrastiveness, which is proven to outperform pair-wise losses. It uses mini-batch sampling effectively and is scalable. Experiments on 4 darkweb social forums, with NBCSAuthor that uses the proposed NBC-Softmax for author and sybil detection, shows that our negative block contrastive approach constantly outperforms state-of-the-art methods using the same network architecture. Our code is publicly available at : https://github.com/gayanku/NBC-Softmax
Efficient block contrastive learning via parameter-free meta-node approximation
Sep 28, 2022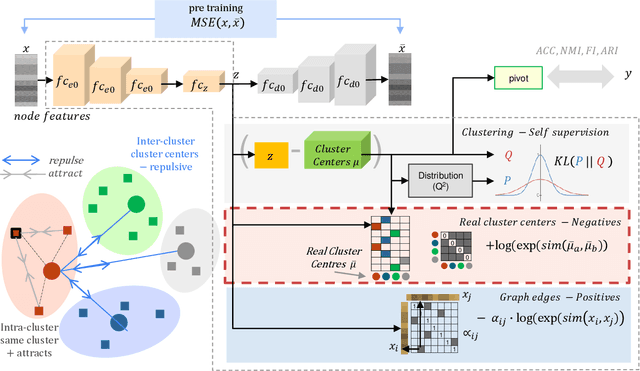

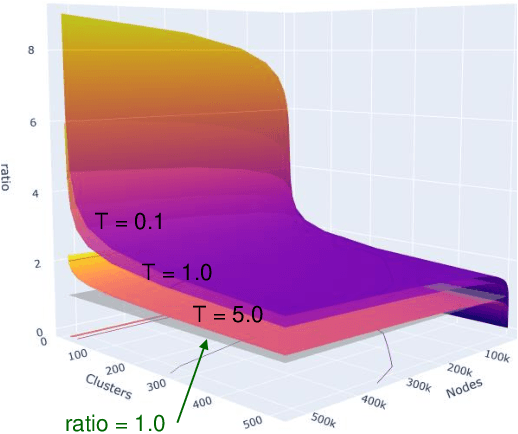
Contrastive learning has recently achieved remarkable success in many domains including graphs. However contrastive loss, especially for graphs, requires a large number of negative samples which is unscalable and computationally prohibitive with a quadratic time complexity. Sub-sampling is not optimal and incorrect negative sampling leads to sampling bias. In this work, we propose a meta-node based approximation technique that can (a) proxy all negative combinations (b) in quadratic cluster size time complexity, (c) at graph level, not node level, and (d) exploit graph sparsity. By replacing node-pairs with additive cluster-pairs, we compute the negatives in cluster-time at graph level. The resulting Proxy approximated meta-node Contrastive (PamC) loss, based on simple optimized GPU operations, captures the full set of negatives, yet is efficient with a linear time complexity. By avoiding sampling, we effectively eliminate sample bias. We meet the criterion for larger number of samples, thus achieving block-contrastiveness, which is proven to outperform pair-wise losses. We use learnt soft cluster assignments for the meta-node constriction, and avoid possible heterophily and noise added during edge creation. Theoretically, we show that real world graphs easily satisfy conditions necessary for our approximation. Empirically, we show promising accuracy gains over state-of-the-art graph clustering on 6 benchmarks. Importantly, we gain substantially in efficiency; up to 3x in training time, 1.8x in inference time and over 5x in GPU memory reduction.
Empirical study of Machine Learning Classifier Evaluation Metrics behavior in Massively Imbalanced and Noisy data
Aug 25, 2022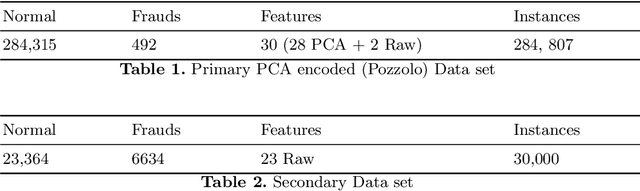
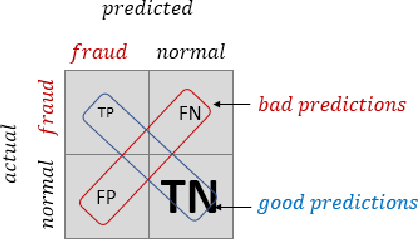
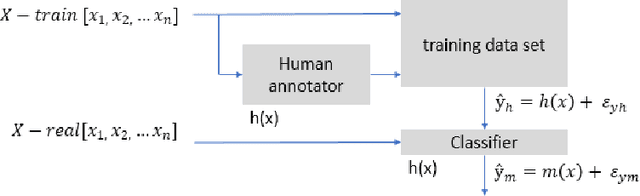
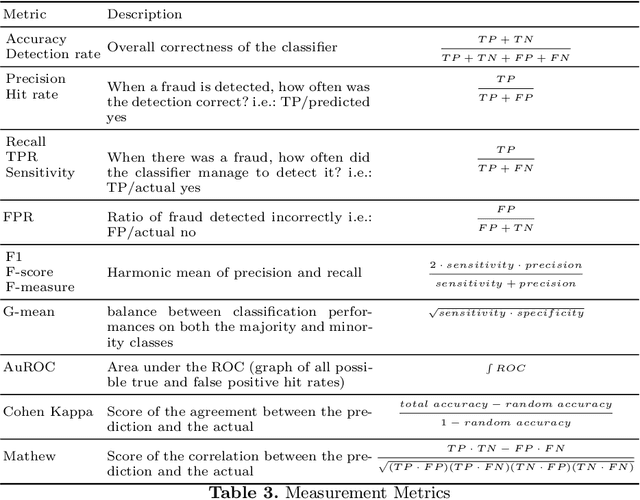
With growing credit card transaction volumes, the fraud percentages are also rising, including overhead costs for institutions to combat and compensate victims. The use of machine learning into the financial sector permits more effective protection against fraud and other economic crime. Suitably trained machine learning classifiers help proactive fraud detection, improving stakeholder trust and robustness against illicit transactions. However, the design of machine learning based fraud detection algorithms has been challenging and slow due the massively unbalanced nature of fraud data and the challenges of identifying the frauds accurately and completely to create a gold standard ground truth. Furthermore, there are no benchmarks or standard classifier evaluation metrics to measure and identify better performing classifiers, thus keeping researchers in the dark. In this work, we develop a theoretical foundation to model human annotation errors and extreme imbalance typical in real world fraud detection data sets. By conducting empirical experiments on a hypothetical classifier, with a synthetic data distribution approximated to a popular real world credit card fraud data set, we simulate human annotation errors and extreme imbalance to observe the behavior of popular machine learning classifier evaluation matrices. We demonstrate that a combined F1 score and g-mean, in that specific order, is the best evaluation metric for typical imbalanced fraud detection model classification.
Credit card fraud detection - Classifier selection strategy
Aug 25, 2022


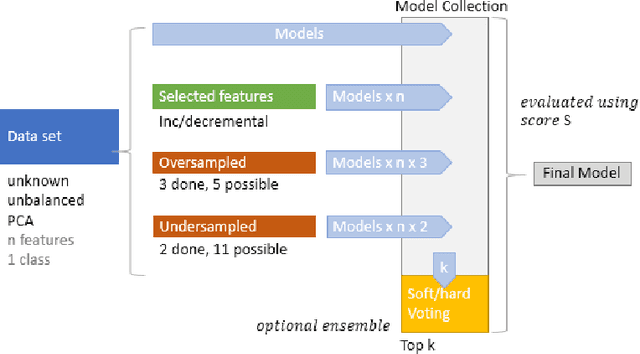
Machine learning has opened up new tools for financial fraud detection. Using a sample of annotated transactions, a machine learning classification algorithm learns to detect frauds. With growing credit card transaction volumes and rising fraud percentages there is growing interest in finding appropriate machine learning classifiers for detection. However, fraud data sets are diverse and exhibit inconsistent characteristics. As a result, a model effective on a given data set is not guaranteed to perform on another. Further, the possibility of temporal drift in data patterns and characteristics over time is high. Additionally, fraud data has massive and varying imbalance. In this work, we evaluate sampling methods as a viable pre-processing mechanism to handle imbalance and propose a data-driven classifier selection strategy for characteristic highly imbalanced fraud detection data sets. The model derived based on our selection strategy surpasses peer models, whilst working in more realistic conditions, establishing the effectiveness of the strategy.
Challenges and Complexities in Machine Learning based Credit Card Fraud Detection
Aug 20, 2022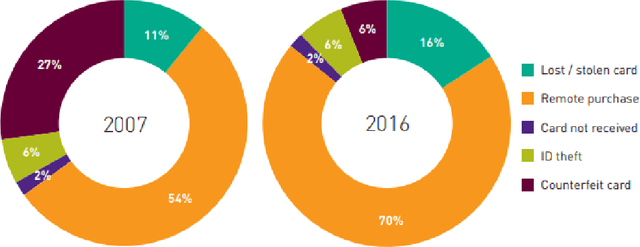

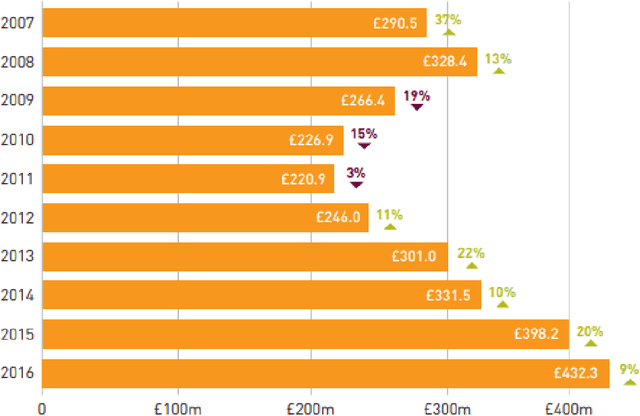

Credit cards play an exploding role in modern economies. Its popularity and ubiquity have created a fertile ground for fraud, assisted by the cross boarder reach and instantaneous confirmation. While transactions are growing, the fraud percentages are also on the rise as well as the true cost of a dollar fraud. Volume of transactions, uniqueness of frauds and ingenuity of the fraudster are main challenges in detecting frauds. The advent of machine learning, artificial intelligence and big data has opened up new tools in the fight against frauds. Given past transactions, a machine learning algorithm has the ability to 'learn' infinitely complex characteristics in order to identify frauds in real-time, surpassing the best human investigators. However, the developments in fraud detection algorithms has been challenging and slow due the massively unbalanced nature of fraud data, absence of benchmarks and standard evaluation metrics to identify better performing classifiers, lack of sharing and disclosure of research findings and the difficulties in getting access to confidential transaction data for research. This work investigates the properties of typical massively imbalanced fraud data sets, their availability, suitability for research use while exploring the widely varying nature of fraud distributions. Furthermore, we show how human annotation errors compound with machine classification errors. We also carry out experiments to determine the effect of PCA obfuscation (as a means of disseminating sensitive transaction data for research and machine learning) on algorithmic performance of classifiers and show that while PCA does not significantly degrade performance, care should be taken to use the appropriate principle component size (dimensions) to avoid overfitting.
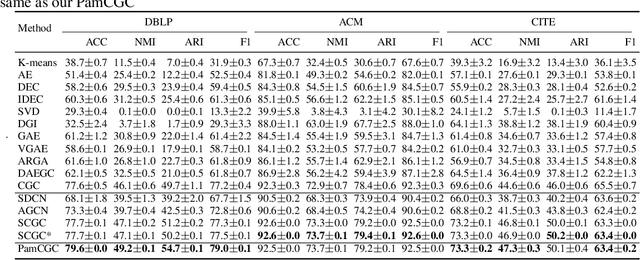
SCGC : Self-Supervised Contrastive Graph Clustering
Apr 27, 2022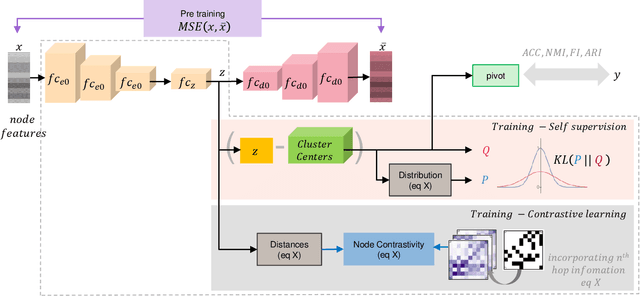

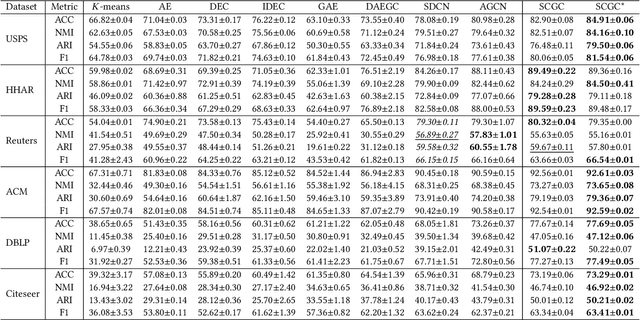
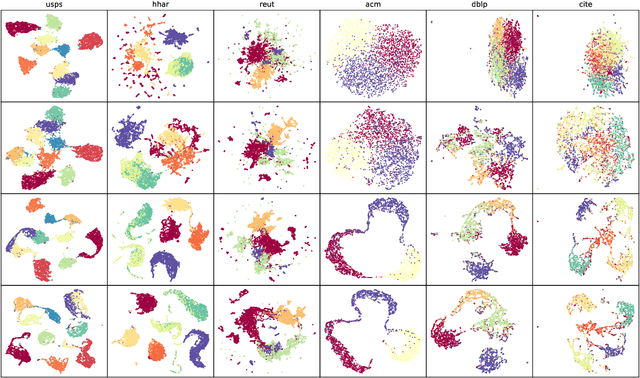
Graph clustering discovers groups or communities within networks. Deep learning methods such as autoencoders (AE) extract effective clustering and downstream representations but cannot incorporate rich structural information. While Graph Neural Networks (GNN) have shown great success in encoding graph structure, typical GNNs based on convolution or attention variants suffer from over-smoothing, noise, heterophily, are computationally expensive and typically require the complete graph being present. Instead, we propose Self-Supervised Contrastive Graph Clustering (SCGC), which imposes graph-structure via contrastive loss signals to learn discriminative node representations and iteratively refined soft cluster labels. We also propose SCGC*, with a more effective, novel, Influence Augmented Contrastive (IAC) loss to fuse richer structural information, and half the original model parameters. SCGC(*) is faster with simple linear units, completely eliminate convolutions and attention of traditional GNNs, yet efficiently incorporates structure. It is impervious to layer depth and robust to over-smoothing, incorrect edges and heterophily. It is scalable by batching, a limitation in many prior GNN models, and trivially parallelizable. We obtain significant improvements over state-of-the-art on a wide range of benchmark graph datasets, including images, sensor data, text, and citation networks efficiently. Specifically, 20% on ARI and 18% on NMI for DBLP; overall 55% reduction in training time and overall, 81% reduction on inference time. Our code is available at : https://github.com/gayanku/SCGC
FDGATII : Fast Dynamic Graph Attention with Initial Residual and Identity Mapping
Oct 25, 2021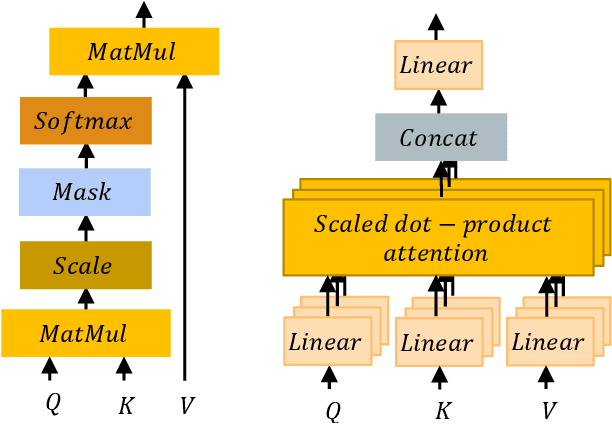

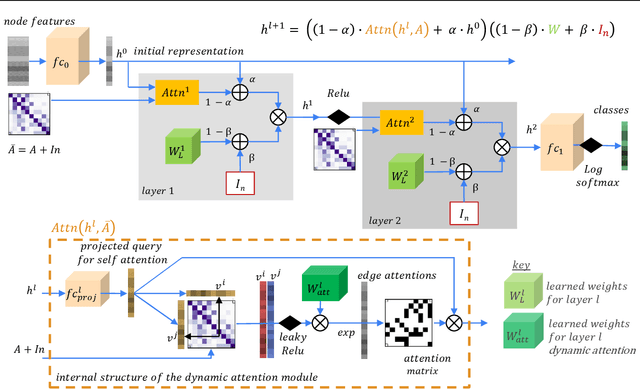
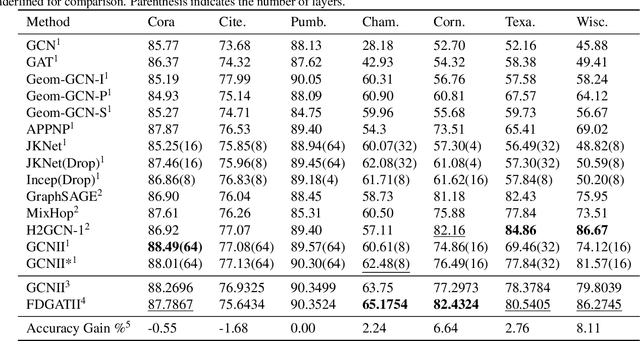
While Graph Neural Networks have gained popularity in multiple domains, graph-structured input remains a major challenge due to (a) over-smoothing, (b) noisy neighbours (heterophily), and (c) the suspended animation problem. To address all these problems simultaneously, we propose a novel graph neural network FDGATII, inspired by attention mechanism's ability to focus on selective information supplemented with two feature preserving mechanisms. FDGATII combines Initial Residuals and Identity Mapping with the more expressive dynamic self-attention to handle noise prevalent from the neighbourhoods in heterophilic data sets. By using sparse dynamic attention, FDGATII is inherently parallelizable in design, whist efficient in operation; thus theoretically able to scale to arbitrary graphs with ease. Our approach has been extensively evaluated on 7 datasets. We show that FDGATII outperforms GAT and GCN based benchmarks in accuracy and performance on fully supervised tasks, obtaining state-of-the-art results on Chameleon and Cornell datasets with zero domain-specific graph pre-processing, and demonstrate its versatility and fairness.