 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Analysis of NetFlow Datasets for Network Intrusion Detection Systems
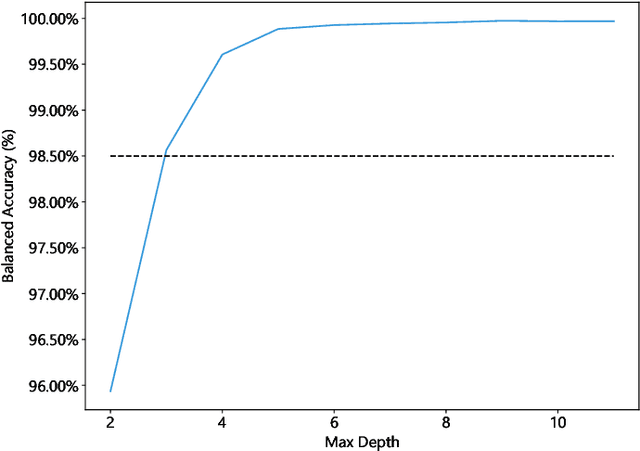
Mar 06, 2025This paper investigates the temporal analysis of NetFlow datasets for machine learning (ML)-based network intrusion detection systems (NIDS). Although many previous studies have highlighted the critical role of temporal features, such as inter-packet arrival time and flow length/duration, in NIDS, the currently available NetFlow datasets for NIDS lack these temporal features. This study addresses this gap by creating and making publicly available a set of NetFlow datasets that incorporate these temporal features [1]. With these temporal features, we provide a comprehensive temporal analysis of NetFlow datasets by examining the distribution of various features over time and presenting time-series representations of NetFlow features. This temporal analysis has not been previously provided in the existing literature. We also borrowed an idea from signal processing, time frequency analysis, and tested it to see how different the time frequency signal presentations (TFSPs) are for various attacks. The results indicate that many attacks have unique patterns, which could help ML models to identify them more easily.
Towards Explainable Network Intrusion Detection using Large Language Models
Aug 08, 2024



Large Language Models (LLMs) have revolutionised natural language processing tasks, particularly as chat agents. However, their applicability to threat detection problems remains unclear. This paper examines the feasibility of employing LLMs as a Network Intrusion Detection System (NIDS), despite their high computational requirements, primarily for the sake of explainability. Furthermore, considerable resources have been invested in developing LLMs, and they may offer utility for NIDS. Current state-of-the-art NIDS rely on artificial benchmarking datasets, resulting in skewed performance when applied to real-world networking environments. Therefore, we compare the GPT-4 and LLama3 models against traditional architectures and transformer-based models to assess their ability to detect malicious NetFlows without depending on artificially skewed datasets, but solely on their vast pre-trained acquired knowledge. Our results reveal that, although LLMs struggle with precise attack detection, they hold significant potential for a path towards explainable NIDS. Our preliminary exploration shows that LLMs are unfit for the detection of Malicious NetFlows. Most promisingly, however, these exhibit significant potential as complementary agents in NIDS, particularly in providing explanations and aiding in threat response when integrated with Retrieval Augmented Generation (RAG) and function calling capabilities.
FlowTransformer: A Transformer Framework for Flow-based Network Intrusion Detection Systems
Apr 28, 2023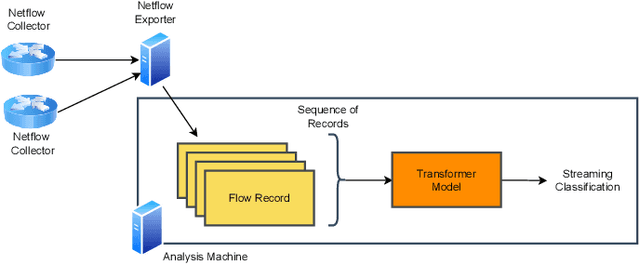
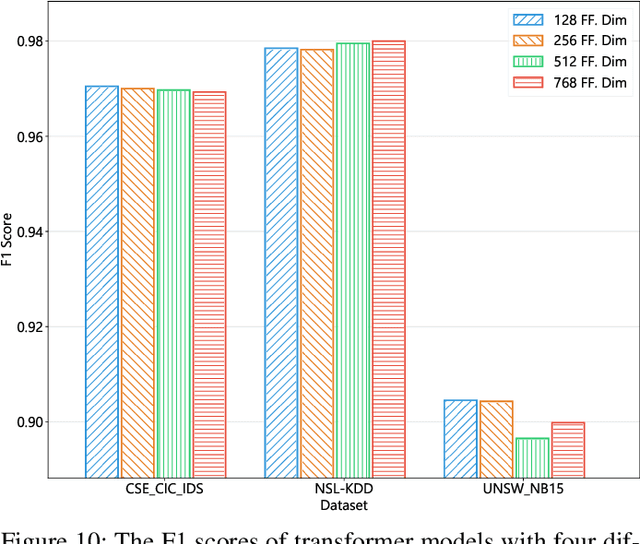
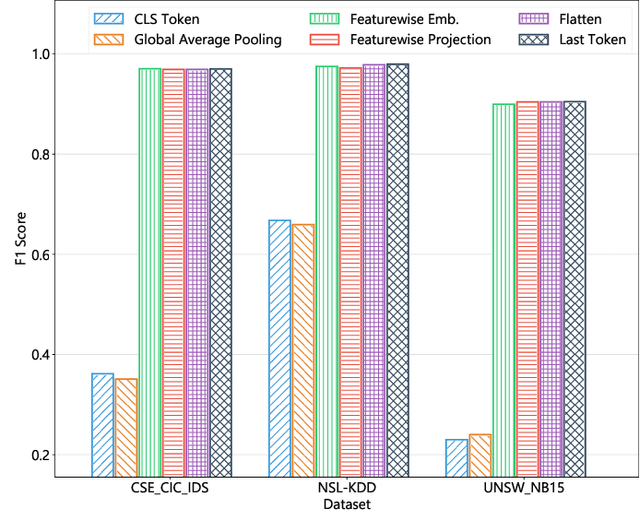
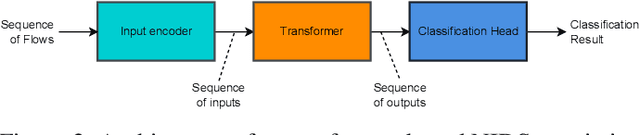
This paper presents the FlowTransformer framework, a novel approach for implementing transformer-based Network Intrusion Detection Systems (NIDSs). FlowTransformer leverages the strengths of transformer models in identifying the long-term behaviour and characteristics of networks, which are often overlooked by most existing NIDSs. By capturing these complex patterns in network traffic, FlowTransformer offers a flexible and efficient tool for researchers and practitioners in the cybersecurity community who are seeking to implement NIDSs using transformer-based models. FlowTransformer allows the direct substitution of various transformer components, including the input encoding, transformer, classification head, and the evaluation of these across any flow-based network dataset. To demonstrate the effectiveness and efficiency of the FlowTransformer framework, we utilise it to provide an extensive evaluation of various common transformer architectures, such as GPT 2.0 and BERT, on three commonly used public NIDS benchmark datasets. We provide results for accuracy, model size and speed. A key finding of our evaluation is that the choice of classification head has the most significant impact on the model performance. Surprisingly, Global Average Pooling, which is commonly used in text classification, performs very poorly in the context of NIDS. In addition, we show that model size can be reduced by over 50\%, and inference and training times improved, with no loss of accuracy, by making specific choices of input encoding and classification head instead of other commonly used alternatives.
NBC-Softmax : Darkweb Author fingerprinting and migration tracking
Dec 15, 2022Metric learning aims to learn distances from the data, which enhances the performance of similarity-based algorithms. An author style detection task is a metric learning problem, where learning style features with small intra-class variations and larger inter-class differences is of great importance to achieve better performance. Recently, metric learning based on softmax loss has been used successfully for style detection. While softmax loss can produce separable representations, its discriminative power is relatively poor. In this work, we propose NBC-Softmax, a contrastive loss based clustering technique for softmax loss, which is more intuitive and able to achieve superior performance. Our technique meets the criterion for larger number of samples, thus achieving block contrastiveness, which is proven to outperform pair-wise losses. It uses mini-batch sampling effectively and is scalable. Experiments on 4 darkweb social forums, with NBCSAuthor that uses the proposed NBC-Softmax for author and sybil detection, shows that our negative block contrastive approach constantly outperforms state-of-the-art methods using the same network architecture. Our code is publicly available at : https://github.com/gayanku/NBC-Softmax
DOC-NAD: A Hybrid Deep One-class Classifier for Network Anomaly Detection
Dec 15, 2022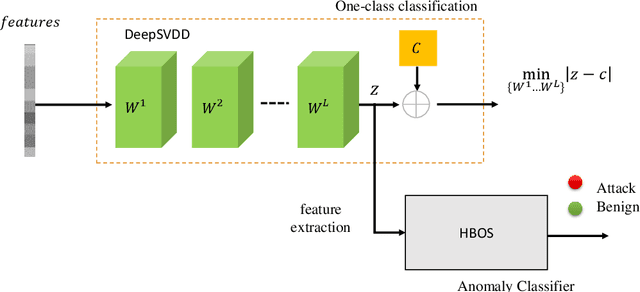

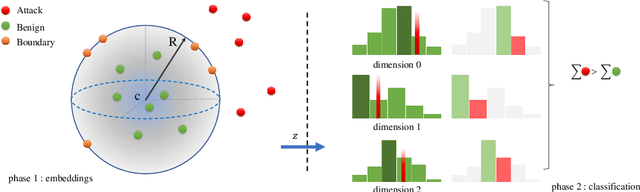
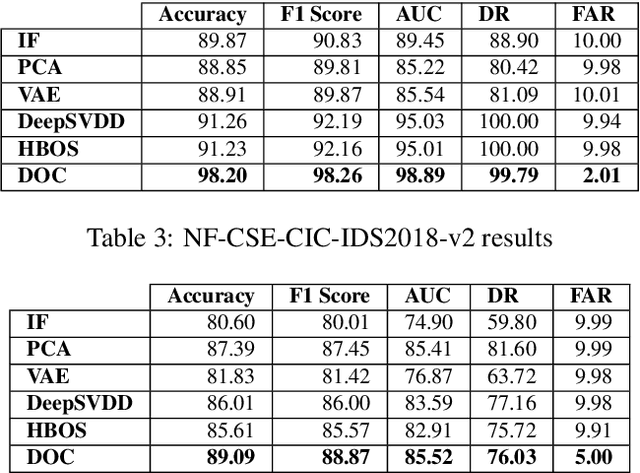
Machine Learning (ML) approaches have been used to enhance the detection capabilities of Network Intrusion Detection Systems (NIDSs). Recent work has achieved near-perfect performance by following binary- and multi-class network anomaly detection tasks. Such systems depend on the availability of both (benign and malicious) network data classes during the training phase. However, attack data samples are often challenging to collect in most organisations due to security controls preventing the penetration of known malicious traffic to their networks. Therefore, this paper proposes a Deep One-Class (DOC) classifier for network intrusion detection by only training on benign network data samples. The novel one-class classification architecture consists of a histogram-based deep feed-forward classifier to extract useful network data features and use efficient outlier detection. The DOC classifier has been extensively evaluated using two benchmark NIDS datasets. The results demonstrate its superiority over current state-of-the-art one-class classifiers in terms of detection and false positive rates.
DI-NIDS: Domain Invariant Network Intrusion Detection System
Oct 15, 2022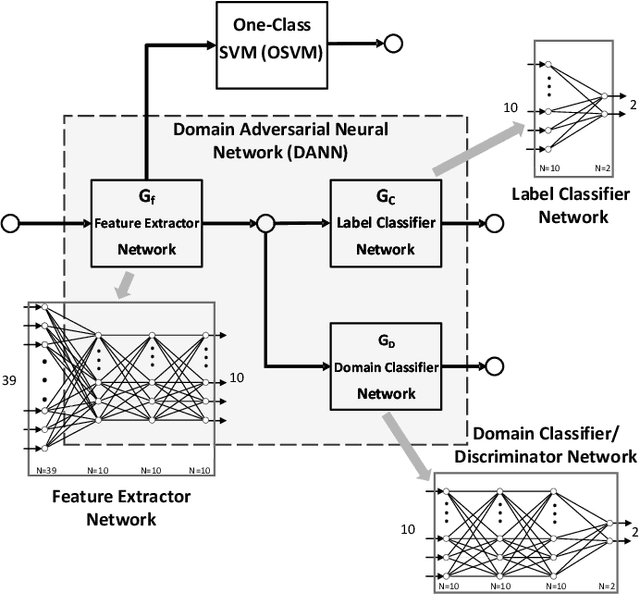
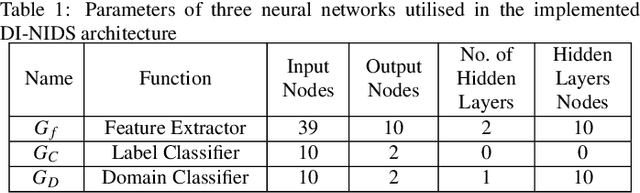
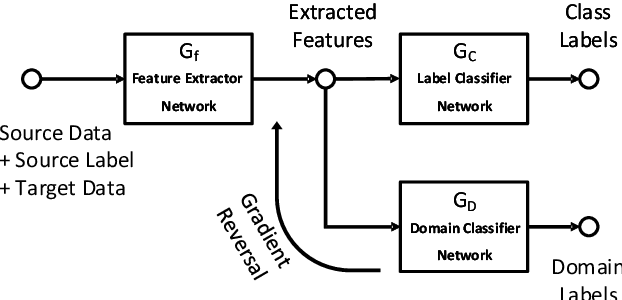
The performance of machine learning based network intrusion detection systems (NIDSs) severely degrades when deployed on a network with significantly different feature distributions from the ones of the training dataset. In various applications, such as computer vision, domain adaptation techniques have been successful in mitigating the gap between the distributions of the training and test data. In the case of network intrusion detection however, the state-of-the-art domain adaptation approaches have had limited success. According to recent studies, as well as our own results, the performance of an NIDS considerably deteriorates when the `unseen' test dataset does not follow the training dataset distribution. In some cases, swapping the train and test datasets makes this even more severe. In order to enhance the generalisibility of machine learning based network intrusion detection systems, we propose to extract domain invariant features using adversarial domain adaptation from multiple network domains, and then apply an unsupervised technique for recognising abnormalities, i.e., intrusions. More specifically, we train a domain adversarial neural network on labelled source domains, extract the domain invariant features, and train a One-Class SVM (OSVM) model to detect anomalies. At test time, we feedforward the unlabeled test data to the feature extractor network to project it into a domain invariant space, and then apply OSVM on the extracted features to achieve our final goal of detecting intrusions. Our extensive experiments on the NIDS benchmark datasets of NFv2-CIC-2018 and NFv2-UNSW-NB15 show that our proposed setup demonstrates superior cross-domain performance in comparison to the previous approaches.
Network Intrusion Detection System in a Light Bulb
Oct 06, 2022

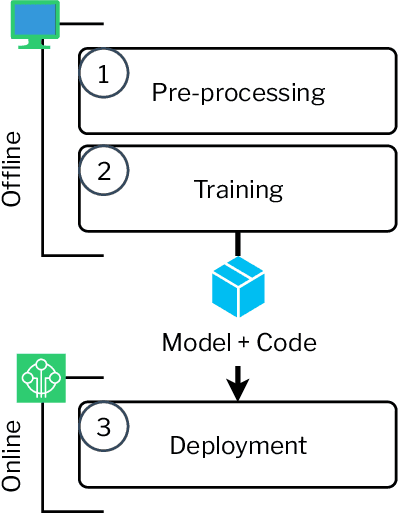
Internet of Things (IoT) devices are progressively being utilised in a variety of edge applications to monitor and control home and industry infrastructure. Due to the limited compute and energy resources, active security protections are usually minimal in many IoT devices. This has created a critical security challenge that has attracted researchers' attention in the field of network security. Despite a large number of proposed Network Intrusion Detection Systems (NIDSs), there is limited research into practical IoT implementations, and to the best of our knowledge, no edge-based NIDS has been demonstrated to operate on common low-power chipsets found in the majority of IoT devices, such as the ESP8266. This research aims to address this gap by pushing the boundaries on low-power Machine Learning (ML) based NIDSs. We propose and develop an efficient and low-power ML-based NIDS, and demonstrate its applicability for IoT edge applications by running it on a typical smart light bulb. We also evaluate our system against other proposed edge-based NIDSs and show that our model has a higher detection performance, and is significantly faster and smaller, and therefore more applicable to a wider range of IoT edge devices.
Efficient block contrastive learning via parameter-free meta-node approximation
Sep 28, 2022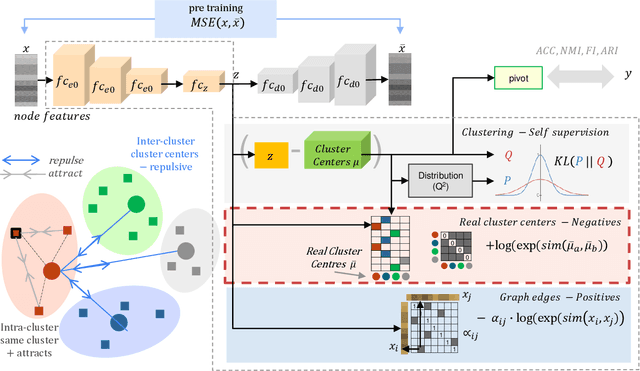

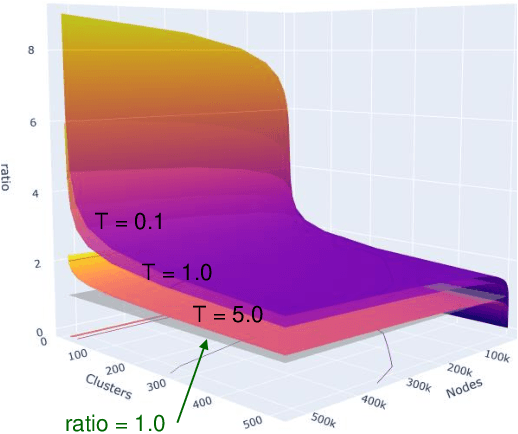
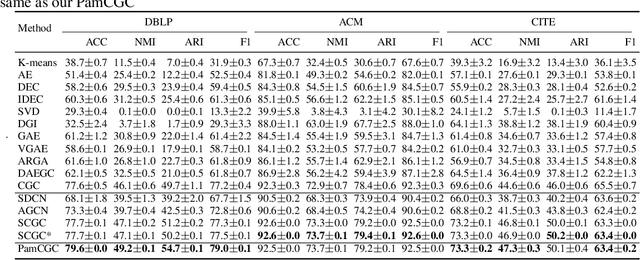
Contrastive learning has recently achieved remarkable success in many domains including graphs. However contrastive loss, especially for graphs, requires a large number of negative samples which is unscalable and computationally prohibitive with a quadratic time complexity. Sub-sampling is not optimal and incorrect negative sampling leads to sampling bias. In this work, we propose a meta-node based approximation technique that can (a) proxy all negative combinations (b) in quadratic cluster size time complexity, (c) at graph level, not node level, and (d) exploit graph sparsity. By replacing node-pairs with additive cluster-pairs, we compute the negatives in cluster-time at graph level. The resulting Proxy approximated meta-node Contrastive (PamC) loss, based on simple optimized GPU operations, captures the full set of negatives, yet is efficient with a linear time complexity. By avoiding sampling, we effectively eliminate sample bias. We meet the criterion for larger number of samples, thus achieving block-contrastiveness, which is proven to outperform pair-wise losses. We use learnt soft cluster assignments for the meta-node constriction, and avoid possible heterophily and noise added during edge creation. Theoretically, we show that real world graphs easily satisfy conditions necessary for our approximation. Empirically, we show promising accuracy gains over state-of-the-art graph clustering on 6 benchmarks. Importantly, we gain substantially in efficiency; up to 3x in training time, 1.8x in inference time and over 5x in GPU memory reduction.
Anomal-E: A Self-Supervised Network Intrusion Detection System based on Graph Neural Networks
Jul 23, 2022
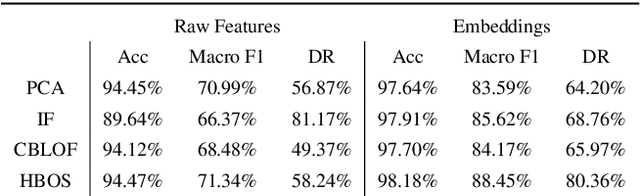
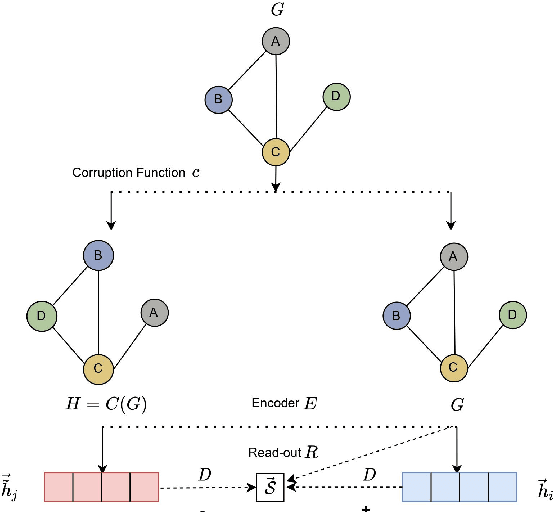
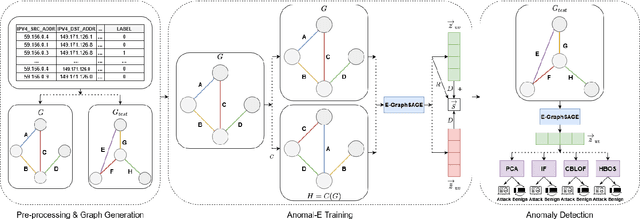
This paper investigates Graph Neural Networks (GNNs) application for self-supervised network intrusion and anomaly detection. GNNs are a deep learning approach for graph-based data that incorporate graph structures into learning to generalise graph representations and output embeddings. As network flows are naturally graph-based, GNNs are a suitable fit for analysing and learning network behaviour. The majority of current implementations of GNN-based Network Intrusion Detection Systems (NIDSs) rely heavily on labelled network traffic which can not only restrict the amount and structure of input traffic, but also the NIDSs potential to adapt to unseen attacks. To overcome these restrictions, we present Anomal-E, a GNN approach to intrusion and anomaly detection that leverages edge features and graph topological structure in a self-supervised process. This approach is, to the best our knowledge, the first successful and practical approach to network intrusion detection that utilises network flows in a self-supervised, edge leveraging GNN. Experimental results on two modern benchmark NIDS datasets not only clearly display the improvement of using Anomal-E embeddings rather than raw features, but also the potential Anomal-E has for detection on wild network traffic.
XG-BoT: An Explainable Deep Graph Neural Network for Botnet Detection and Forensics
Jul 19, 2022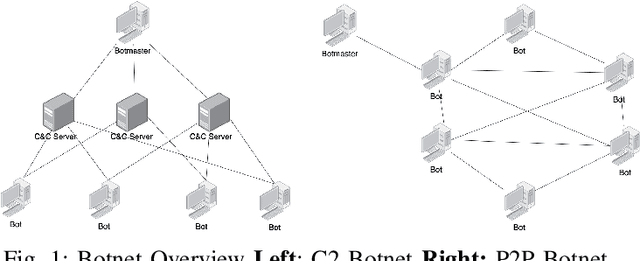

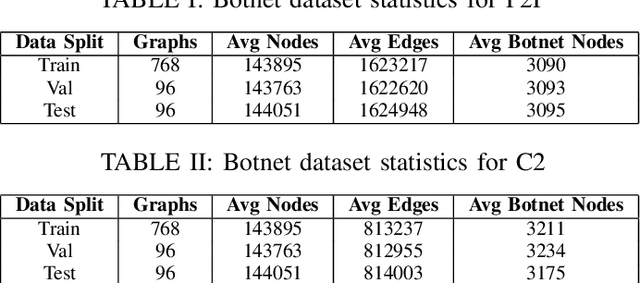

In this paper, we proposed XG-BoT, an explainable deep graph neural network model for botnet node detection. The proposed model is mainly composed of a botnet detector and an explainer for automatic forensics. The XG-BoT detector can effectively detect malicious botnet nodes under large-scale networks. Specifically, it utilizes a grouped reversible residual connection with a graph isomorphism network to learn expressive node representations from the botnet communication graphs. The explainer in XG-BoT can perform automatic network forensics by highlighting suspicious network flows and related botnet nodes. We evaluated XG-BoT on real-world, large-scale botnet network graphs. Overall, XG-BoT is able to outperform the state-of-the-art in terms of evaluation metrics. In addition, we show that the XG-BoT explainer can generate useful explanations based on GNNExplainer for automatic network forensics.