 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Extraction for Machine Learning-based Intrusion Detection in IoT Networks
Paper and Code
Aug 28, 2021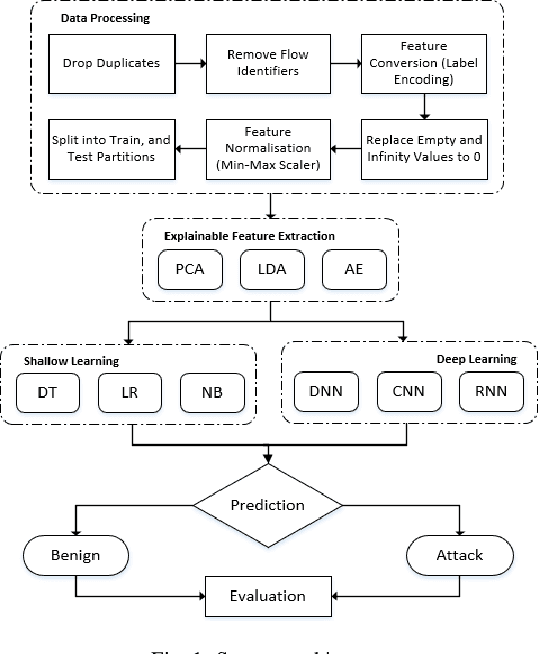
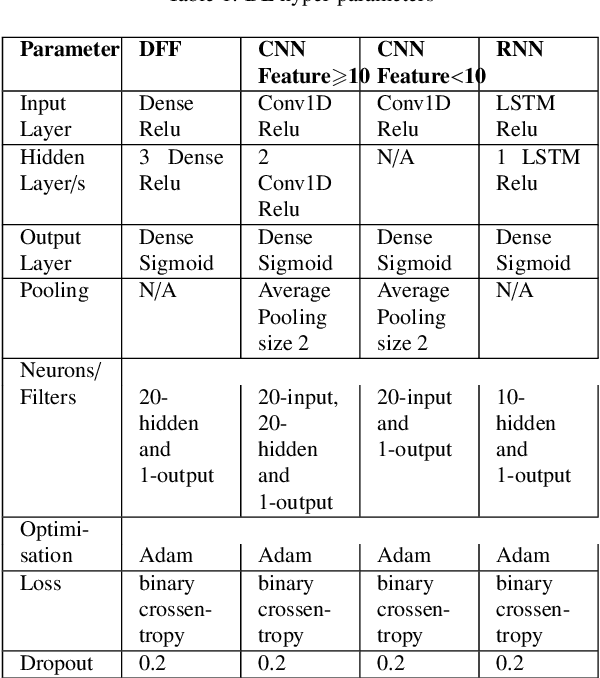
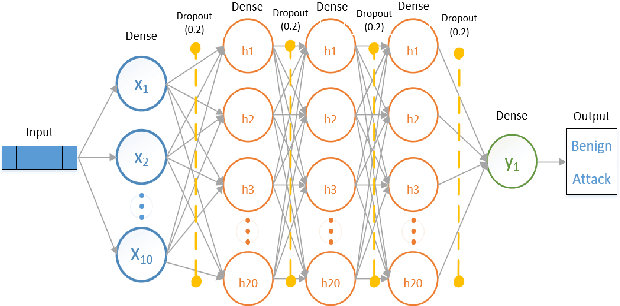
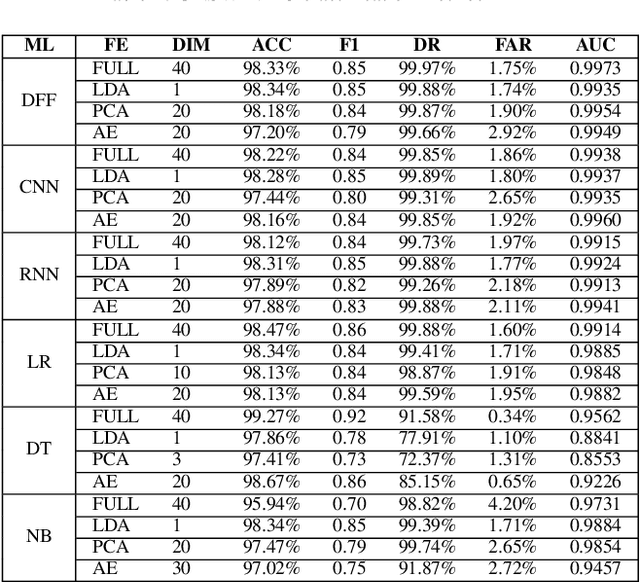
The tremendous numbers of network security breaches that have occurred in IoT networks have demonstrated the unreliability of current Network Intrusion Detection Systems (NIDSs). Consequently, network interruptions and loss of sensitive data have occurred which led to an active research area for improving NIDS technologies. During an analysis of related works, it was observed that most researchers aimed to obtain better classification results by using a set of untried combinations of Feature Reduction (FR) and Machine Learning (ML) techniques on NIDS datasets. However, these datasets are different in feature sets, attack types, and network design. Therefore, this paper aims to discover whether these techniques can be generalised across various datasets. Six ML models are utilised: a Deep Feed Forward, Convolutional Neural Network, Recurrent Neural Network, Decision Tree, Logistic Regression, and Naive Bayes. The detection accuracy of three Feature Extraction (FE) algorithms; Principal Component Analysis (PCA), Auto-encoder (AE), and Linear Discriminant Analysis (LDA) is evaluated using three benchmark datasets; UNSW-NB15, ToN-IoT and CSE-CIC-IDS2018. Although PCA and AE algorithms have been widely used, determining their optimal number of extracted dimensions has been overlooked. The results obtained indicate that there is no clear FE method or ML model that can achieve the best scores for all datasets. The optimal number of extracted dimensions has been identified for each dataset and LDA decreases the performance of the ML models on two datasets. The variance is used to analyse the extracted dimensions of LDA and PCA. Finally, this paper concludes that the choice of datasets significantly alters the performance of the applied techniques and we argue for the need for a universal (benchmark) feature set to facilitate further advancement and progress in this field of research.