 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion with Deep Neural Networks for Audio-Video Emotion Recognition
Jul 06, 2019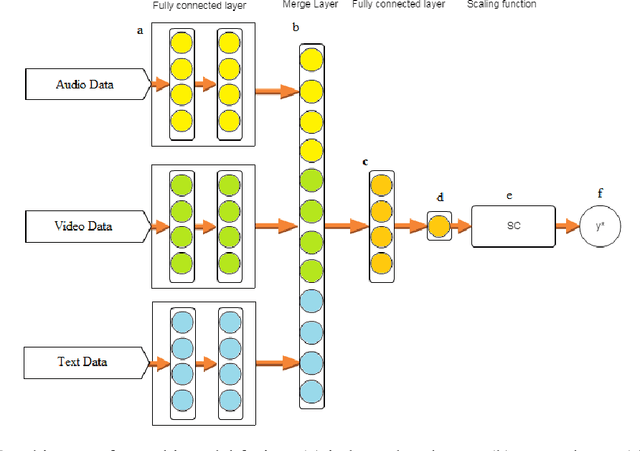
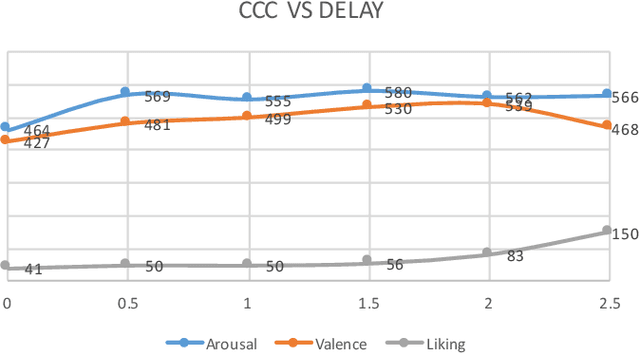
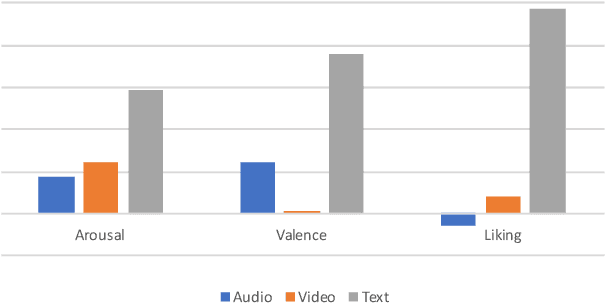
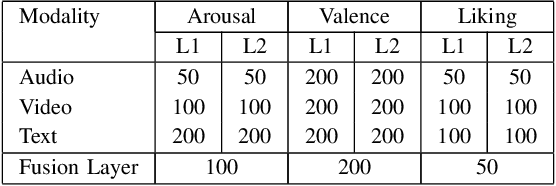
This paper presents a novel deep neural network (DNN) for multimodal fusion of audio, video and text modalities for emotion recognition. The proposed DNN architecture has independent and shared layers which aim to learn the representation for each modality, as well as the best combined representation to achieve the best prediction. Experimental results on the AVEC Sentiment Analysis in the Wild dataset indicate that the proposed DNN can achieve a higher level of Concordance Correlation Coefficient (CCC) than other state-of-the-art systems that perform early fusion of modalities at feature-level (i.e., concatenation) and late fusion at score-level (i.e., weighted average) fusion. The proposed DNN has achieved CCCs of 0.606, 0.534, and 0.170 on the development partition of the dataset for predicting arousal, valence and liking, respectively.
Bag-of-Audio-Words based on Autoencoder Codebook for Continuous Emotion Prediction
Jul 06, 2019

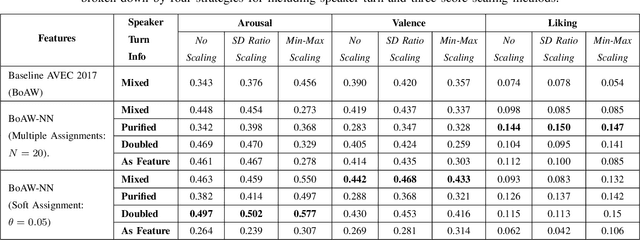
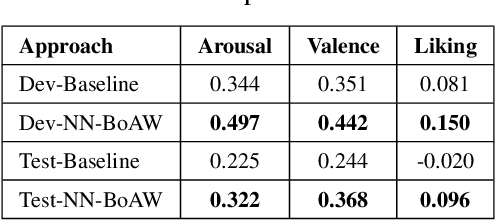
In this paper we present a novel approach for extracting a Bag-of-Words (BoW) representation based on a Neural Network codebook. The conventional BoW model is based on a dictionary (codebook) built from elementary representations which are selected randomly or by using a clustering algorithm on a training dataset. A metric is then used to assign unseen elementary representations to the closest dictionary entries in order to produce a histogram. In the proposed approach, an autoencoder (AE) encompasses the role of both the dictionary creation and the assignment metric. The dimension of the encoded layer of the AE corresponds to the size of the dictionary and the output of its neurons represents the assignment metric. Experimental results for the continuous emotion prediction task on the AVEC 2017 audio dataset have shown an improvement of the Concordance Correlation Coefficient (CCC) from 0.225 to 0.322 for arousal dimension and from 0.244 to 0.368 for valence dimension relative to the conventional BoW version implemented in a baseline system.
Speaker Sincerity Detection based on Covariance Feature Vectors and Ensemble Methods
Apr 26, 2019

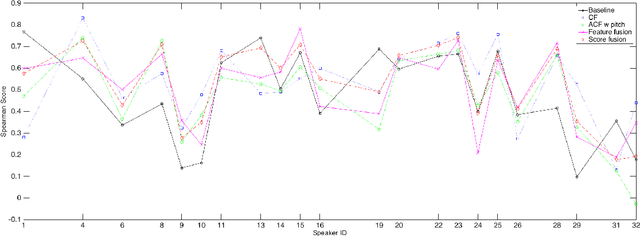
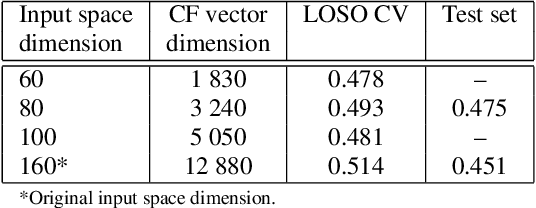
Automatic measuring of speaker sincerity degree is a novel research problem in computational paralinguistics. This paper proposes covariance-based feature vectors to model speech and ensembles of support vector regressors to estimate the degree of sincerity of a speaker. The elements of each covariance vector are pairwise statistics between the short-term feature components. These features are used alone as well as in combination with the ComParE acoustic feature set. The experimental results on the development set of the Sincerity Speech Corpus using a cross-validation procedure have shown an 8.1% relative improvement in the Spearman's correlation coefficient over the baseline system.