 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Combined Use of Extrinsic Semantic Resources for Medical Information Search
May 17, 2020


Semantic concepts and relations encoded in domain-specific ontologies and other medical semantic resources play a crucial role in deciphering terms in medical queries and documents. The exploitation of these resources for tackling the semantic gap issue has been widely studied in the literature. However, there are challenges that hinder their widespread use in real-world applications. Among these challenges is the insufficient knowledge individually encoded in existing medical ontologies, which is magnified when users express their information needs using long-winded natural language queries. In this context, many of the users query terms are either unrecognized by the used ontologies, or cause retrieving false positives that degrade the quality of current medical information search approaches. In this article, we explore the combination of multiple extrinsic semantic resources in the development of a full-fledged medical information search framework to: i) highlight and expand head medical concepts in verbose medical queries (i.e. concepts among query terms that significantly contribute to the informativeness and intent of a given query), ii) build semantically enhanced inverted index documents, iii) contribute to a heuristical weighting technique in the query document matching process. To demonstrate the effectiveness of the proposed approach, we conducted several experiments over the CLEF eHealth 2014 dataset. Findings indicate that the proposed method combining several extrinsic semantic resources proved to be more effective than related approaches in terms of precision measure.
Vision-based techniques for gait recognition
Apr 30, 2020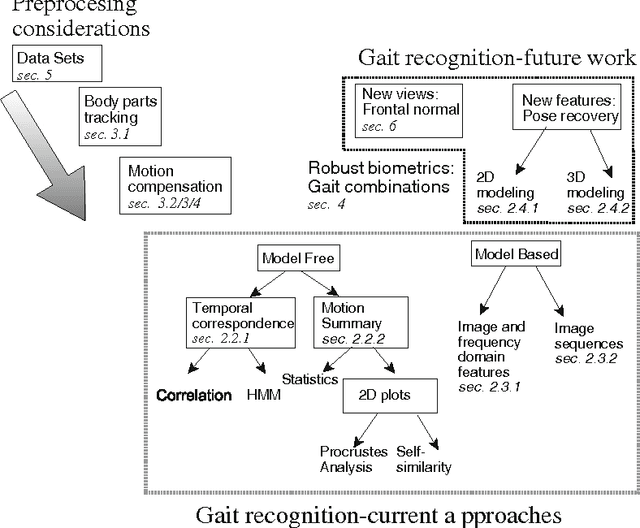

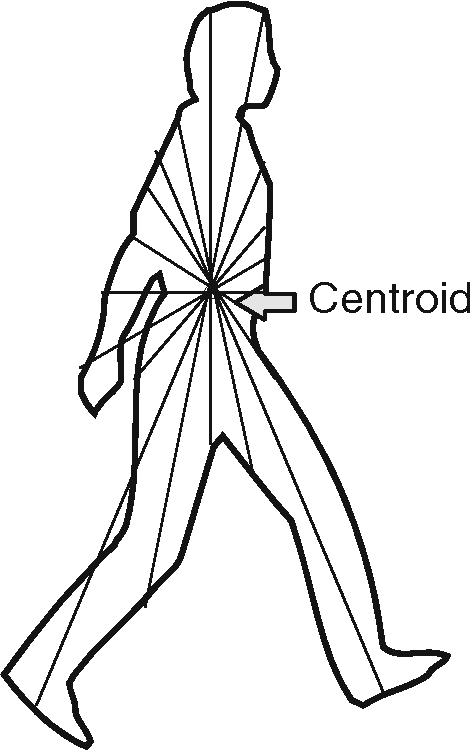

Global security concerns have raised a proliferation of video surveillance devices. Intelligent surveillance systems seek to discover possible threats automatically and raise alerts. Being able to identify the surveyed object can help determine its threat level. The current generation of devices provide digital video data to be analysed for time varying features to assist in the identification process. Commonly, people queue up to access a facility and approach a video camera in full frontal view. In this environment, a variety of biometrics are available - for example, gait which includes temporal features like stride period. Gait can be measured unobtrusively at a distance. The video data will also include face features, which are short-range biometrics. In this way, one can combine biometrics naturally using one set of data. In this paper we survey current techniques of gait recognition and modelling with the environment in which the research was conducted. We also discuss in detail the issues arising from deriving gait data, such as perspective and occlusion effects, together with the associated computer vision challenges of reliable tracking of human movement. Then, after highlighting these issues and challenges related to gait processing, we proceed to discuss the frameworks combining gait with other biometrics. We then provide motivations for a novel paradigm in biometrics-based human recognition, i.e. the use of the fronto-normal view of gait as a far-range biometrics combined with biometrics operating at a near distance.
A Linguistically Driven Framework for Query Expansion via Grammatical Constituent Highlighting and Role-Based Concept Weighting
Apr 25, 2020



In this paper, we propose a linguistically-motivated query expansion framework that recognizes and en-codes significant query constituents that characterize query intent in order to improve retrieval performance. Concepts-of-Interest are recognized as the core concepts that represent the gist of the search goal whilst the remaining query constituents which serve to specify the search goal and complete the query structure are classified as descriptive, relational or structural. Acknowledging the need to form semantically-associated base pairs for the purpose of extracting related potential expansion concepts, an algorithm which capitalizes on syntactical dependencies to capture relationships between adjacent and non-adjacent query concepts is proposed. Lastly, a robust weighting scheme that duly emphasizes the importance of query constituents based on their linguistic role within the expanded query is presented. We demonstrate improvements in retrieval effectiveness in terms of increased mean average precision (MAP) garnered by the proposed linguistic-based query expansion framework through experimentation on the TREC ad hoc test collections.
Natural language technology and query expansion: issues, state-of-the-art and perspectives
Apr 23, 2020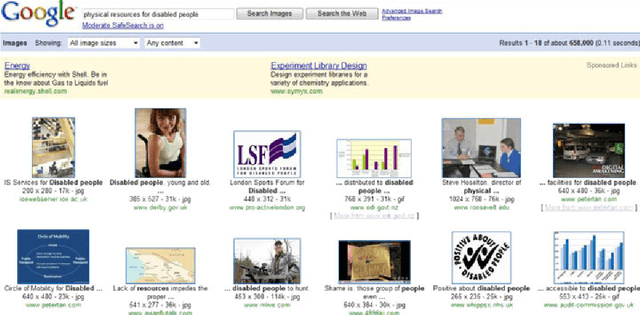
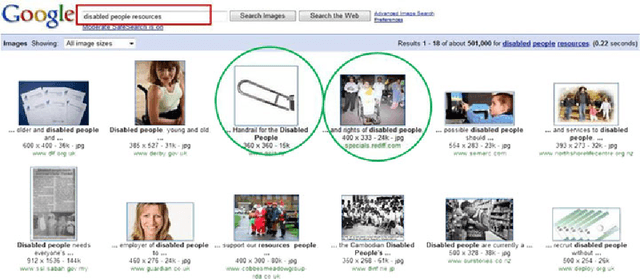
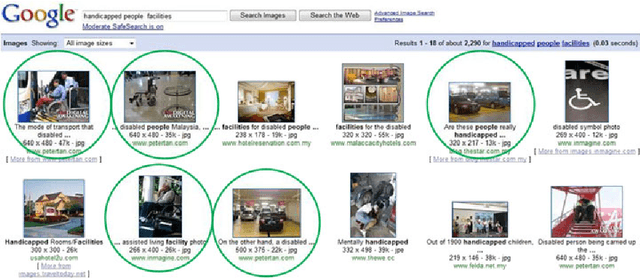
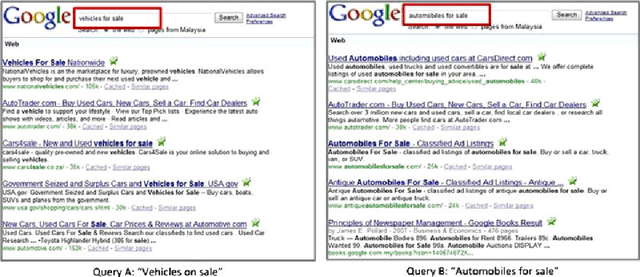
The availability of an abundance of knowledge sources has spurred a large amount of effort in the development and enhancement of Information Retrieval techniques. Users information needs are expressed in natural language and successful retrieval is very much dependent on the effective communication of the intended purpose. Natural language queries consist of multiple linguistic features which serve to represent the intended search goal. Linguistic characteristics that cause semantic ambiguity and misinterpretation of queries as well as additional factors such as the lack of familiarity with the search environment affect the users ability to accurately represent their information needs, coined by the concept intention gap. The latter directly affects the relevance of the returned search results which may not be to the users satisfaction and therefore is a major issue impacting the effectiveness of information retrieval systems. Central to our discussion is the identification of the significant constituents that characterize the query intent and their enrichment through the addition of meaningful terms, phrases or even latent representations, either manually or automatically to capture their intended meaning. Specifically, we discuss techniques to achieve the enrichment and in particular those utilizing the information gathered from statistical processing of term dependencies within a document corpus or from external knowledge sources such as ontologies. We lay down the anatomy of a generic linguistic based query expansion framework and propose its module-based decomposition, covering topical issues from query processing, information retrieval, computational linguistics and ontology engineering. For each of the modules we review state-of-the-art solutions in the literature categorized and analyzed under the light of the techniques used.
Coupled intrinsic and extrinsic human language resource-based query expansion
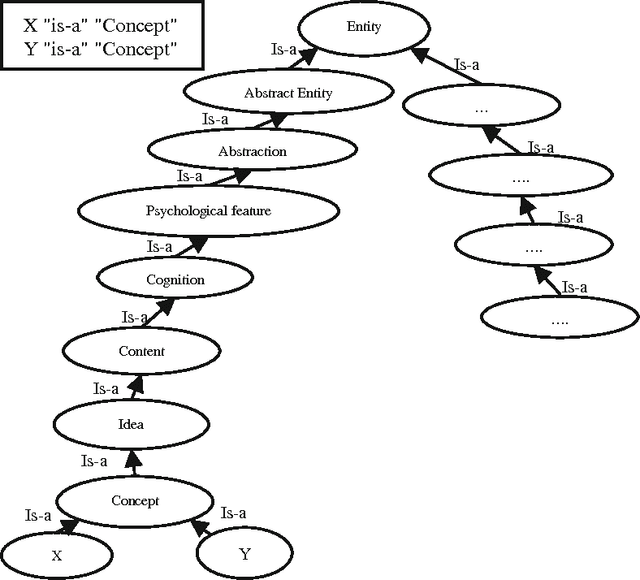
Apr 23, 2020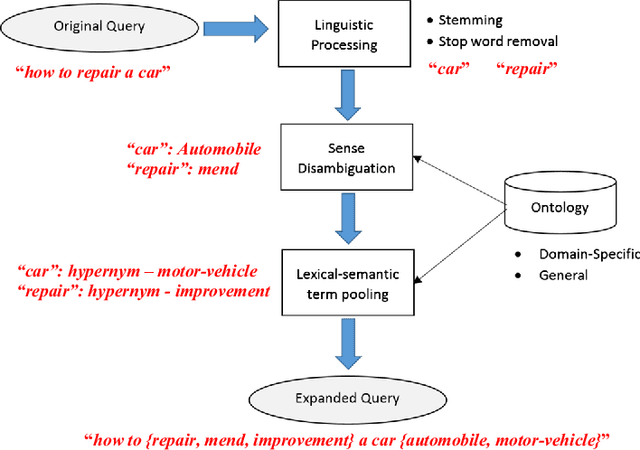
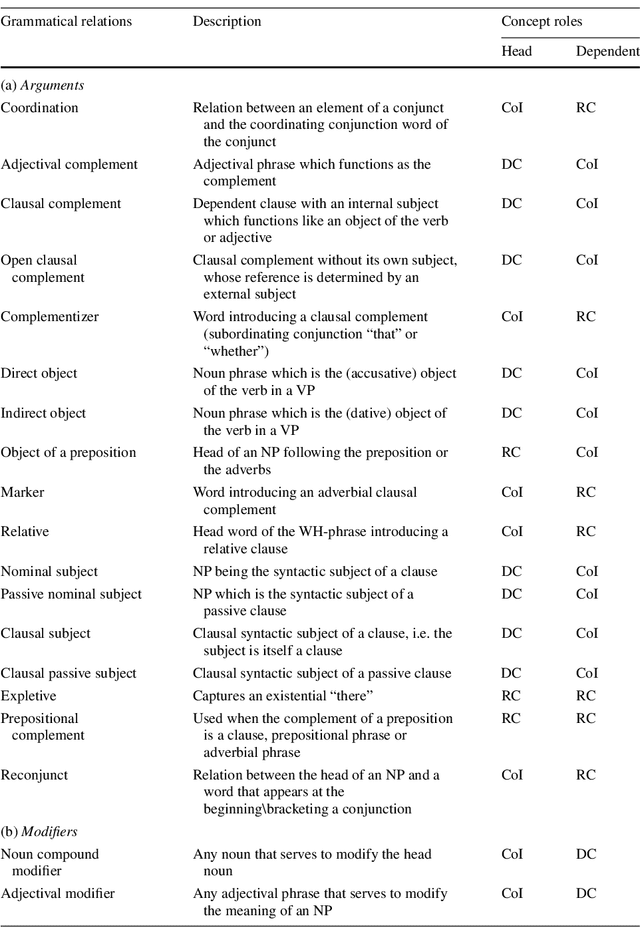
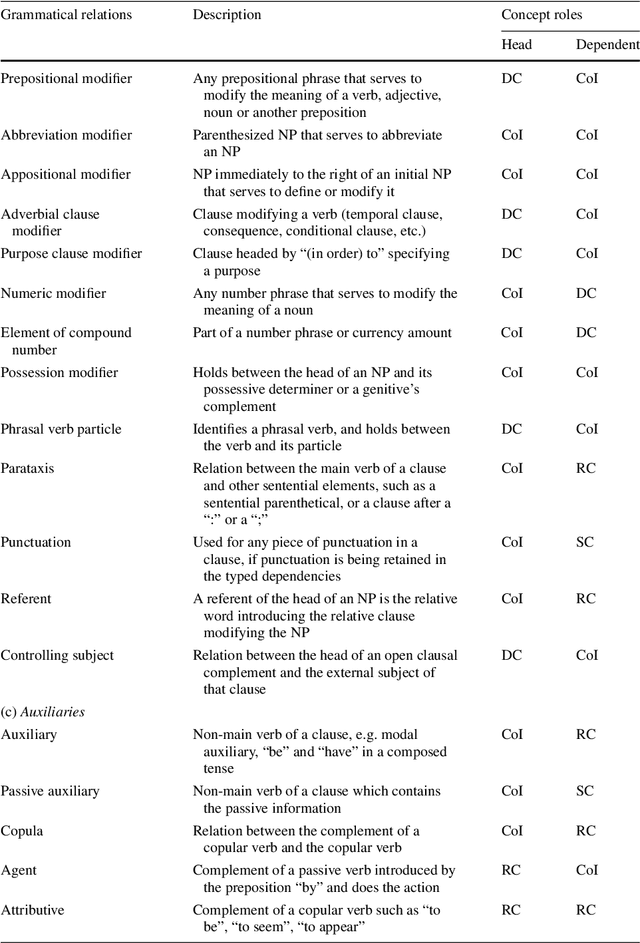

Poor information retrieval performance has often been attributed to the query-document vocabulary mismatch problem which is defined as the difficulty for human users to formulate precise natural language queries that are in line with the vocabulary of the documents deemed relevant to a specific search goal. To alleviate this problem, query expansion processes are applied in order to spawn and integrate additional terms to an initial query. This requires accurate identification of main query concepts to ensure the intended search goal is duly emphasized and relevant expansion concepts are extracted and included in the enriched query. Natural language queries have intrinsic linguistic properties such as parts-of-speech labels and grammatical relations which can be utilized in determining the intended search goal. Additionally, extrinsic language-based resources such as ontologies are needed to suggest expansion concepts semantically coherent with the query content. We present here a query expansion framework which capitalizes on both linguistic characteristics of user queries and ontology resources for query constituent encoding, expansion concept extraction and concept weighting. A thorough empirical evaluation on real-world datasets validates our approach against unigram language model, relevance model and a sequential dependence based technique.
Coupling semantic and statistical techniques for dynamically enriching web ontologies
Apr 23, 2020

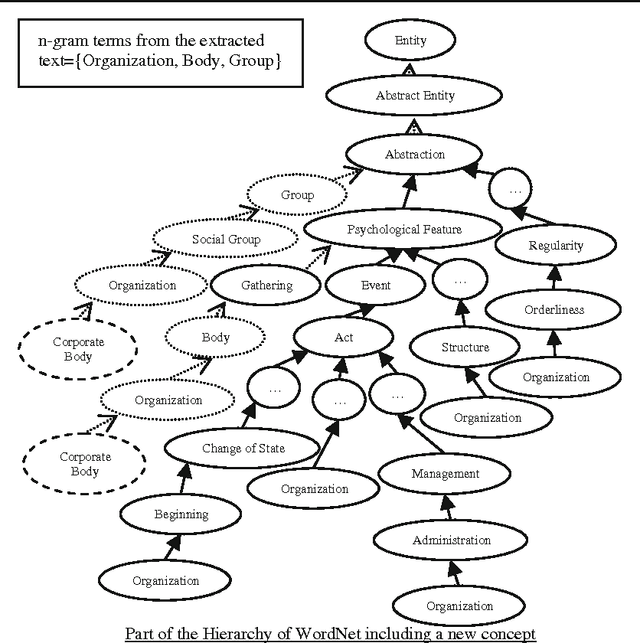
With the development of the Semantic Web technology, the use of ontologies to store and retrieve information covering several domains has increased. However, very few ontologies are able to cope with the ever-growing need of frequently updated semantic information or specific user requirements in specialized domains. As a result, a critical issue is related to the unavailability of relational information between concepts, also coined missing background knowledge. One solution to address this issue relies on the manual enrichment of ontologies by domain experts which is however a time consuming and costly process, hence the need for dynamic ontology enrichment. In this paper we present an automatic coupled statistical/semantic framework for dynamically enriching large-scale generic ontologies from the World Wide Web. Using the massive amount of information encoded in texts on the Web as a corpus, missing background knowledge can therefore be discovered through a combination of semantic relatedness measures and pattern acquisition techniques and subsequently exploited. The benefits of our approach are: (i) proposing the dynamic enrichment of large-scale generic ontologies with missing background knowledge, and thus, enabling the reuse of such knowledge, (ii) dealing with the issue of costly ontological manual enrichment by domain experts. Experimental results in a precision-based evaluation setting demonstrate the effectiveness of the proposed techniques.
Leveraging Cognitive Search Patterns to Enhance Automated Natural Language Retrieval Performance
Apr 21, 2020



The search of information in large text repositories has been plagued by the so-called document-query vocabulary gap, i.e. the semantic discordance between the contents in the stored document entities on the one hand and the human query on the other hand. Over the past two decades, a significant body of works has advanced technical retrieval prowess while several studies have shed light on issues pertaining to human search behavior. We believe that these efforts should be conjoined, in the sense that automated retrieval systems have to fully emulate human search behavior and thus consider the procedure according to which users incrementally enhance their initial query. To this end, cognitive reformulation patterns that mimic user search behaviour are highlighted and enhancement terms which are statistically collocated with or lexical-semantically related to the original terms adopted in the retrieval process. We formalize the application of these patterns by considering a query conceptual representation and introducing a set of operations allowing to operate modifications on the initial query. A genetic algorithm-based weighting process allows placing emphasis on terms according to their conceptual role-type. An experimental evaluation on real-world datasets against relevance, language, conceptual and knowledge-based models is conducted. We also show, when compared to language and relevance models, a better performance in terms of mean average precision than a word embedding-based model instantiation.