 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural language technology and query expansion: issues, state-of-the-art and perspectives
Paper and Code
Apr 23, 2020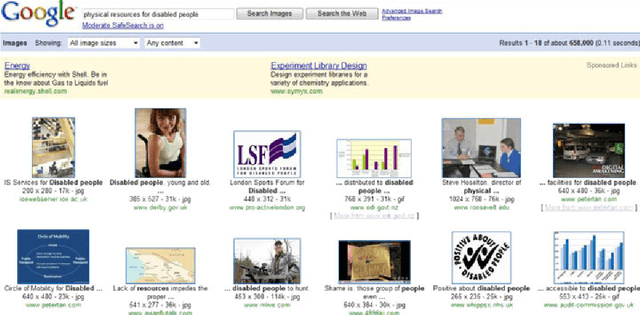
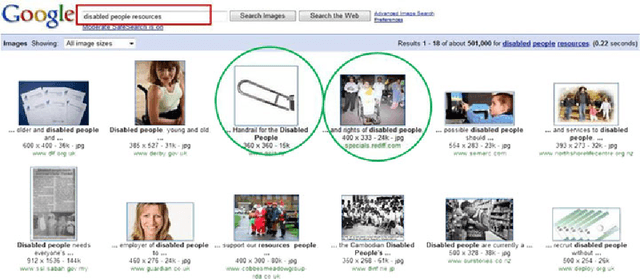
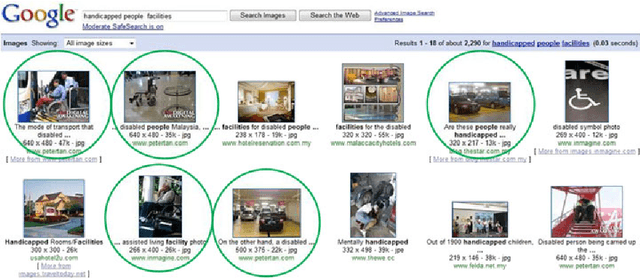
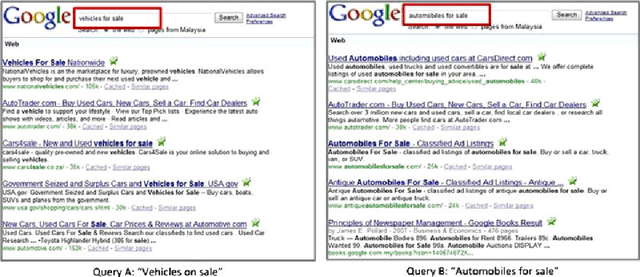
The availability of an abundance of knowledge sources has spurred a large amount of effort in the development and enhancement of Information Retrieval techniques. Users information needs are expressed in natural language and successful retrieval is very much dependent on the effective communication of the intended purpose. Natural language queries consist of multiple linguistic features which serve to represent the intended search goal. Linguistic characteristics that cause semantic ambiguity and misinterpretation of queries as well as additional factors such as the lack of familiarity with the search environment affect the users ability to accurately represent their information needs, coined by the concept intention gap. The latter directly affects the relevance of the returned search results which may not be to the users satisfaction and therefore is a major issue impacting the effectiveness of information retrieval systems. Central to our discussion is the identification of the significant constituents that characterize the query intent and their enrichment through the addition of meaningful terms, phrases or even latent representations, either manually or automatically to capture their intended meaning. Specifically, we discuss techniques to achieve the enrichment and in particular those utilizing the information gathered from statistical processing of term dependencies within a document corpus or from external knowledge sources such as ontologies. We lay down the anatomy of a generic linguistic based query expansion framework and propose its module-based decomposition, covering topical issues from query processing, information retrieval, computational linguistics and ontology engineering. For each of the modules we review state-of-the-art solutions in the literature categorized and analyzed under the light of the techniques used.