 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Relational Exploration in Cultural Heritage Knowledge Graphs with LLMs: A Neuro-Symbolic Approach
Jan 11, 2025



This paper introduces a neuro-symbolic approach for relational exploration in cultural heritage knowledge graphs, leveraging Large Language Models (LLMs) for explanation generation and a novel mathematical framework to quantify the interestingness of relationships. We demonstrate the importance of interestingness measure using a quantitative analysis, by highlighting its impact on the overall performance of our proposed system, particularly in terms of precision, recall, and F1-score. Using the Wikidata Cultural Heritage Linked Open Data (WCH-LOD) dataset, our approach yields a precision of 0.70, recall of 0.68, and an F1-score of 0.69, representing an improvement compared to graph-based (precision: 0.28, recall: 0.25, F1-score: 0.26) and knowledge-based baselines (precision: 0.45, recall: 0.42, F1-score: 0.43). Furthermore, our LLM-powered explanations exhibit better quality, reflected in BLEU (0.52), ROUGE-L (0.58), and METEOR (0.63) scores, all higher than the baseline approaches. We show a strong correlation (0.65) between interestingness measure and the quality of generated explanations, validating its effectiveness. The findings highlight the importance of LLMs and a mathematical formalization for interestingness in enhancing the effectiveness of relational exploration in cultural heritage knowledge graphs, with results that are measurable and testable. We further show that the system enables more effective exploration compared to purely knowledge-based and graph-based methods.
A Novel Voronoi-based Convolutional Neural Network Framework for Pushing Person Detection in Crowd Videos
Oct 11, 2023



Analyzing the microscopic dynamics of pushing behavior within crowds can offer valuable insights into crowd patterns and interactions. By identifying instances of pushing in crowd videos, a deeper understanding of when, where, and why such behavior occurs can be achieved. This knowledge is crucial to creating more effective crowd management strategies, optimizing crowd flow, and enhancing overall crowd experiences. However, manually identifying pushing behavior at the microscopic level is challenging, and the existing automatic approaches cannot detect such microscopic behavior. Thus, this article introduces a novel automatic framework for identifying pushing in videos of crowds on a microscopic level. The framework comprises two main components: i) Feature extraction and ii) Video labeling. In the feature extraction component, a new Voronoi-based method is developed for determining the local regions associated with each person in the input video. Subsequently, these regions are fed into EfficientNetV1B0 Convolutional Neural Network to extract the deep features of each person over time. In the second component, a combination of a fully connected layer with a Sigmoid activation function is employed to analyze these deep features and annotate the individuals involved in pushing within the video. The framework is trained and evaluated on a new dataset created using six real-world experiments, including their corresponding ground truths. The experimental findings indicate that the suggested framework outperforms seven baseline methods that are employed for comparative analysis purposes.
Towards the Exploitation of LLM-based Chatbot for Providing Legal Support to Palestinian Cooperatives
Jun 09, 2023
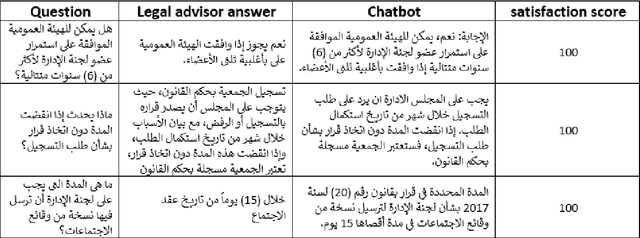


With the ever-increasing utilization of natural language processing (NLP), we started to witness over the past few years a significant transformation in our interaction with legal texts. This technology has advanced the analysis and enhanced the understanding of complex legal terminology and contexts. The development of recent large language models (LLMs), particularly ChatGPT, has also introduced a revolutionary contribution to the way that legal texts can be processed and comprehended. In this paper, we present our work on a cooperative-legal question-answering LLM-based chatbot, where we developed a set of legal questions about Palestinian cooperatives, associated with their regulations and compared the auto-generated answers by the chatbot to their correspondences that are designed by a legal expert. To evaluate the proposed chatbot, we have used 50 queries generated by the legal expert and compared the answers produced by the chart to their relevance judgments. Finding demonstrated that an overall accuracy rate of 82% has been achieved when answering the queries, while exhibiting an F1 score equivalent to 79%.
A cloud-based deep learning system for improving crowd safety at event entrances
Feb 16, 2023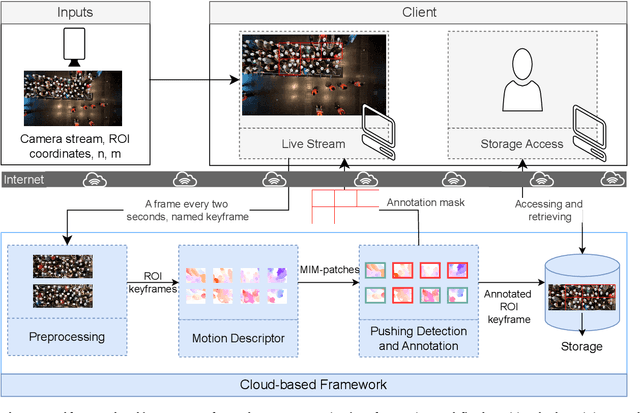
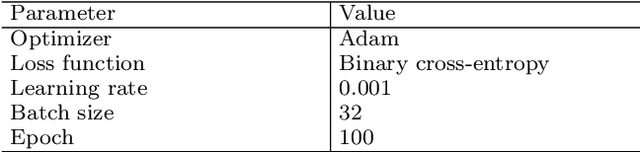
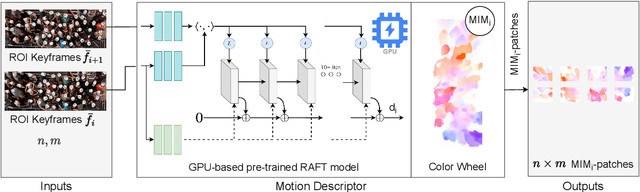

Crowding at the entrances of large events may lead to critical and life-threatening situations, particularly when people start pushing each other to reach the event faster. A system for automatic and timely identification of pushing behavior would help organizers and security forces to intervene early and mitigate dangerous situations. In this paper, we propose a cloud-based deep learning system for early detection of pushing automatically in the live video stream of crowded event entrances. The proposed system relies mainly on two models: a pre-trained deep optical flow and an adapted version of the EfficientNetV2B0 classifier. The optical flow model extracts the characteristics of the crowd motion in the live video stream, while the classifier analyses the crowd motion and annotates pushing patches in the live stream. A novel dataset is generated based on five real-world experiments and their associated ground truth data to train the adapted EfficientNetV2B0 model. The experimental situations simulated a crowded event entrance, and social psychologists manually created the ground truths for each video experiment. Several experiments on the videos and the generated dataset are carried out to evaluate the accuracy and annotation delay time of the proposed system. Furthermore, the experts manually revised the annotation results of the system. Findings indicate that the system identified pushing behaviors with an accuracy rate of 89% within an acceptable delay time.
On the Combined Use of Extrinsic Semantic Resources for Medical Information Search
May 17, 2020


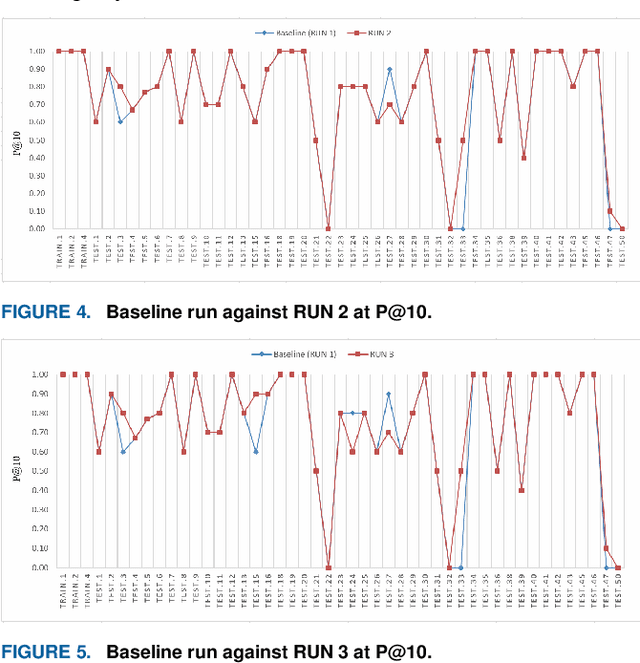
Semantic concepts and relations encoded in domain-specific ontologies and other medical semantic resources play a crucial role in deciphering terms in medical queries and documents. The exploitation of these resources for tackling the semantic gap issue has been widely studied in the literature. However, there are challenges that hinder their widespread use in real-world applications. Among these challenges is the insufficient knowledge individually encoded in existing medical ontologies, which is magnified when users express their information needs using long-winded natural language queries. In this context, many of the users query terms are either unrecognized by the used ontologies, or cause retrieving false positives that degrade the quality of current medical information search approaches. In this article, we explore the combination of multiple extrinsic semantic resources in the development of a full-fledged medical information search framework to: i) highlight and expand head medical concepts in verbose medical queries (i.e. concepts among query terms that significantly contribute to the informativeness and intent of a given query), ii) build semantically enhanced inverted index documents, iii) contribute to a heuristical weighting technique in the query document matching process. To demonstrate the effectiveness of the proposed approach, we conducted several experiments over the CLEF eHealth 2014 dataset. Findings indicate that the proposed method combining several extrinsic semantic resources proved to be more effective than related approaches in terms of precision measure.
Coupling semantic and statistical techniques for dynamically enriching web ontologies
Apr 23, 2020

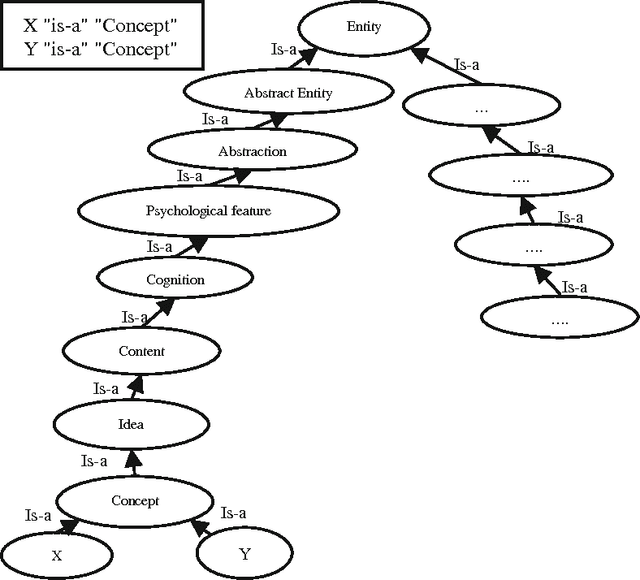
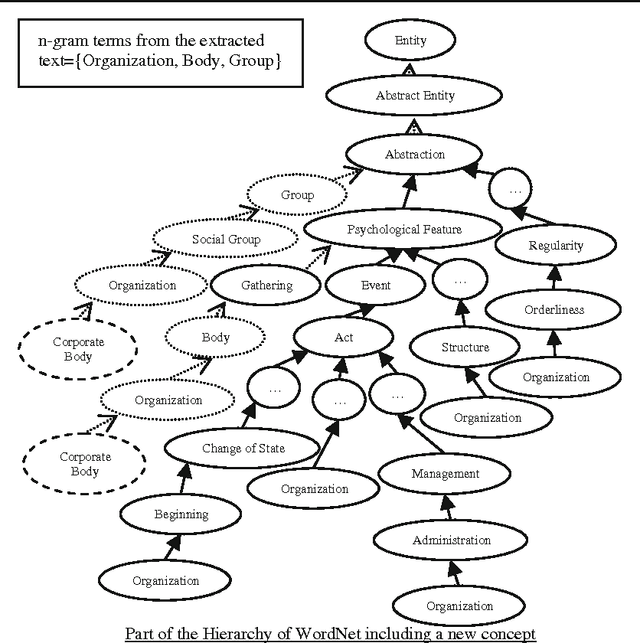
With the development of the Semantic Web technology, the use of ontologies to store and retrieve information covering several domains has increased. However, very few ontologies are able to cope with the ever-growing need of frequently updated semantic information or specific user requirements in specialized domains. As a result, a critical issue is related to the unavailability of relational information between concepts, also coined missing background knowledge. One solution to address this issue relies on the manual enrichment of ontologies by domain experts which is however a time consuming and costly process, hence the need for dynamic ontology enrichment. In this paper we present an automatic coupled statistical/semantic framework for dynamically enriching large-scale generic ontologies from the World Wide Web. Using the massive amount of information encoded in texts on the Web as a corpus, missing background knowledge can therefore be discovered through a combination of semantic relatedness measures and pattern acquisition techniques and subsequently exploited. The benefits of our approach are: (i) proposing the dynamic enrichment of large-scale generic ontologies with missing background knowledge, and thus, enabling the reuse of such knowledge, (ii) dealing with the issue of costly ontological manual enrichment by domain experts. Experimental results in a precision-based evaluation setting demonstrate the effectiveness of the proposed techniques.