 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial LSTM with Dynamic Occupancy Modeling for Realistic Pedestrian Trajectory Prediction
Nov 12, 2025In dynamic and crowded environments, realistic pedestrian trajectory prediction remains a challenging task due to the complex nature of human motion and the mutual influences among individuals. Deep learning models have recently achieved promising results by implicitly learning such patterns from 2D trajectory data. However, most approaches treat pedestrians as point entities, ignoring the physical space that each person occupies. To address these limitations, this paper proposes a novel deep learning model that enhances the Social LSTM with a new Dynamic Occupied Space loss function. This loss function guides Social LSTM in learning to avoid realistic collisions without increasing displacement error across different crowd densities, ranging from low to high, in both homogeneous and heterogeneous density settings. Such a function achieves this by combining the average displacement error with a new collision penalty that is sensitive to scene density and individual spatial occupancy. For efficient training and evaluation, five datasets were generated from real pedestrian trajectories recorded during the Festival of Lights in Lyon 2022. Four datasets represent homogeneous crowd conditions -- low, medium, high, and very high density -- while the fifth corresponds to a heterogeneous density distribution. The experimental findings indicate that the proposed model not only lowers collision rates but also enhances displacement prediction accuracy in each dataset. Specifically, the model achieves up to a 31% reduction in the collision rate and reduces the average displacement error and the final displacement error by 5% and 6%, respectively, on average across all datasets compared to the baseline. Moreover, the proposed model consistently outperforms several state-of-the-art deep learning models across most test sets.
A Novel Voronoi-based Convolutional Neural Network Framework for Pushing Person Detection in Crowd Videos
Oct 11, 2023



Analyzing the microscopic dynamics of pushing behavior within crowds can offer valuable insights into crowd patterns and interactions. By identifying instances of pushing in crowd videos, a deeper understanding of when, where, and why such behavior occurs can be achieved. This knowledge is crucial to creating more effective crowd management strategies, optimizing crowd flow, and enhancing overall crowd experiences. However, manually identifying pushing behavior at the microscopic level is challenging, and the existing automatic approaches cannot detect such microscopic behavior. Thus, this article introduces a novel automatic framework for identifying pushing in videos of crowds on a microscopic level. The framework comprises two main components: i) Feature extraction and ii) Video labeling. In the feature extraction component, a new Voronoi-based method is developed for determining the local regions associated with each person in the input video. Subsequently, these regions are fed into EfficientNetV1B0 Convolutional Neural Network to extract the deep features of each person over time. In the second component, a combination of a fully connected layer with a Sigmoid activation function is employed to analyze these deep features and annotate the individuals involved in pushing within the video. The framework is trained and evaluated on a new dataset created using six real-world experiments, including their corresponding ground truths. The experimental findings indicate that the suggested framework outperforms seven baseline methods that are employed for comparative analysis purposes.
A cloud-based deep learning system for improving crowd safety at event entrances
Feb 16, 2023Crowding at the entrances of large events may lead to critical and life-threatening situations, particularly when people start pushing each other to reach the event faster. A system for automatic and timely identification of pushing behavior would help organizers and security forces to intervene early and mitigate dangerous situations. In this paper, we propose a cloud-based deep learning system for early detection of pushing automatically in the live video stream of crowded event entrances. The proposed system relies mainly on two models: a pre-trained deep optical flow and an adapted version of the EfficientNetV2B0 classifier. The optical flow model extracts the characteristics of the crowd motion in the live video stream, while the classifier analyses the crowd motion and annotates pushing patches in the live stream. A novel dataset is generated based on five real-world experiments and their associated ground truth data to train the adapted EfficientNetV2B0 model. The experimental situations simulated a crowded event entrance, and social psychologists manually created the ground truths for each video experiment. Several experiments on the videos and the generated dataset are carried out to evaluate the accuracy and annotation delay time of the proposed system. Furthermore, the experts manually revised the annotation results of the system. Findings indicate that the system identified pushing behaviors with an accuracy rate of 89% within an acceptable delay time.
Wayfinding and cognitive maps for pedestrian models
Feb 05, 2016
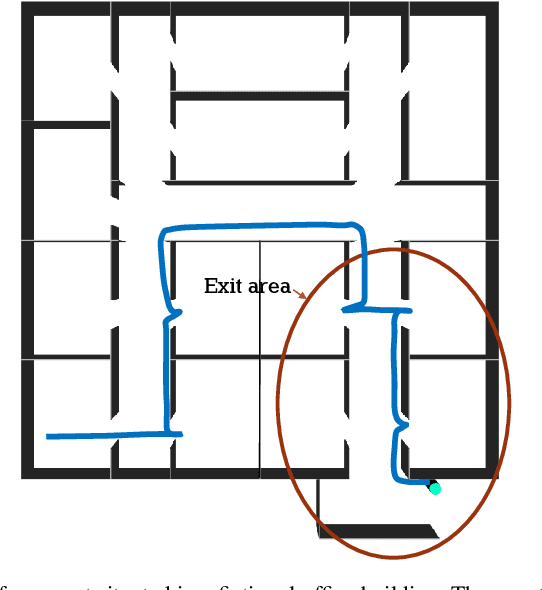

Usually, routing models in pedestrian dynamics assume that agents have fulfilled and global knowledge about the building's structure. However, they neglect the fact that pedestrians possess no or only parts of information about their position relative to final exits and possible routes leading to them. To get a more realistic description we introduce the systematics of gathering and using spatial knowledge. A new wayfinding model for pedestrian dynamics is proposed. The model defines for every pedestrian an individual knowledge representation implying inaccuracies and uncertainties. In addition, knowledge-driven search strategies are introduced. The presented concept is tested on a fictive example scenario.