 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCE: Dynamic 3D CNN Pruning: Joint Frame, Channel, and Feature Adaptation for Energy Efficiency on the Edge
Mar 18, 2026Modern convolutional neural networks (CNNs) are workhorses for video and image processing, but fail to adapt to the computational complexity of input samples in a dynamic manner to minimize energy consumption. In this research, we propose DANCE, a fine-grained, input-aware, dynamic pruning framework for 3D CNNs to maximize power efficiency with negligible to zero impact on performance. In the proposed two-step approach, the first step is called activation variability amplification (AVA), and the 3D CNN model is retrained to increase the variance of the magnitude of neuron activations across the network in this step, facilitating pruning decisions across diverse CNN input scenarios. In the second step, called adaptive activation pruning (AAP), a lightweight activation controller network is trained to dynamically prune frames, channels, and features of 3D convolutional layers of the network (different for each layer), based on statistics of the outputs of the first layer of the network. Our method achieves substantial savings in multiply-accumulate (MAC) operations and memory accesses by introducing sparsity within convolutional layers. Hardware validation on the NVIDIA Jetson Nano GPU and the Qualcomm Snapdragon 8 Gen 1 platform demonstrates respective speedups of 1.37X and 2.22X, achieving up to 1.47X higher energy efficiency compared to the state of the art.
RESOLVE: Relational Reasoning with Symbolic and Object-Level Features Using Vector Symbolic Processing
Nov 13, 2024Modern transformer-based encoder-decoder architectures struggle with reasoning tasks due to their inability to effectively extract relational information between input objects (data/tokens). Recent work introduced the Abstractor module, embedded between transformer layers, to address this gap. However, the Abstractor layer while excelling at capturing relational information (pure relational reasoning), faces challenges in tasks that require both object and relational-level reasoning (partial relational reasoning). To address this, we propose RESOLVE, a neuro-vector symbolic architecture that combines object-level features with relational representations in high-dimensional spaces, using fast and efficient operations such as bundling (summation) and binding (Hadamard product) allowing both object-level features and relational representations to coexist within the same structure without interfering with one another. RESOLVE is driven by a novel attention mechanism that operates in a bipolar high dimensional space, allowing fast attention score computation compared to the state-of-the-art. By leveraging this design, the model achieves both low compute latency and memory efficiency. RESOLVE also offers better generalizability while achieving higher accuracy in purely relational reasoning tasks such as sorting as well as partial relational reasoning tasks such as math problem-solving compared to state-of-the-art methods.
LARS-VSA: A Vector Symbolic Architecture For Learning with Abstract Rules
May 23, 2024



Human cognition excels at symbolic reasoning, deducing abstract rules from limited samples. This has been explained using symbolic and connectionist approaches, inspiring the development of a neuro-symbolic architecture that combines both paradigms. In parallel, recent studies have proposed the use of a "relational bottleneck" that separates object-level features from abstract rules, allowing learning from limited amounts of data . While powerful, it is vulnerable to the curse of compositionality meaning that object representations with similar features tend to interfere with each other. In this paper, we leverage hyperdimensional computing, which is inherently robust to such interference to build a compositional architecture. We adapt the "relational bottleneck" strategy to a high-dimensional space, incorporating explicit vector binding operations between symbols and relational representations. Additionally, we design a novel high-dimensional attention mechanism that leverages this relational representation. Our system benefits from the low overhead of operations in hyperdimensional space, making it significantly more efficient than the state of the art when evaluated on a variety of test datasets, while maintaining higher or equal accuracy.
A Novel Hyperdimensional Computing Framework for Online Time Series Forecasting on the Edge
Feb 03, 2024In recent years, both online and offline deep learning models have been developed for time series forecasting. However, offline deep forecasting models fail to adapt effectively to changes in time-series data, while online deep forecasting models are often expensive and have complex training procedures. In this paper, we reframe the online nonlinear time-series forecasting problem as one of linear hyperdimensional time-series forecasting. Nonlinear low-dimensional time-series data is mapped to high-dimensional (hyperdimensional) spaces for linear hyperdimensional prediction, allowing fast, efficient and lightweight online time-series forecasting. Our framework, TSF-HD, adapts to time-series distribution shifts using a novel co-training framework for its hyperdimensional mapping and its linear hyperdimensional predictor. TSF-HD is shown to outperform the state of the art, while having reduced inference latency, for both short-term and long-term time series forecasting. Our code is publicly available at http://github.com/tsfhd2024/tsf-hd.git
Impact of Feature Encoding on Malware Classification Explainability
Jul 10, 2023



This paper investigates the impact of feature encoding techniques on the explainability of XAI (Explainable Artificial Intelligence) algorithms. Using a malware classification dataset, we trained an XGBoost model and compared the performance of two feature encoding methods: Label Encoding (LE) and One Hot Encoding (OHE). Our findings reveal a marginal performance loss when using OHE instead of LE. However, the more detailed explanations provided by OHE compensated for this loss. We observed that OHE enables deeper exploration of details in both global and local contexts, facilitating more comprehensive answers. Additionally, we observed that using OHE resulted in smaller explanation files and reduced analysis time for human analysts. These findings emphasize the significance of considering feature encoding techniques in XAI research and suggest potential for further exploration by incorporating additional encoding methods and innovative visualization approaches.
Semantic Segmentation and Object Detection Towards Instance Segmentation: Breast Tumor Identification
Aug 06, 2021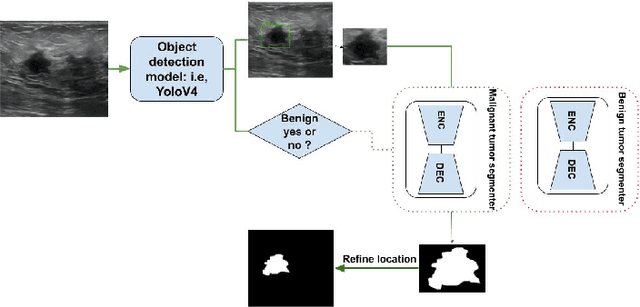
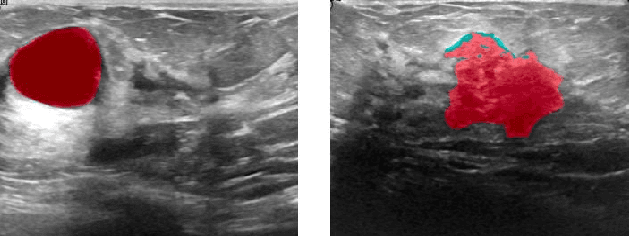


Breast cancer is one of the factors that cause the increase of mortality of women. The most widely used method for diagnosing this geological disease i.e. breast cancer is the ultrasound scan. Several key features such as the smoothness and the texture of the tumor captured through ultrasound scans encode the abnormality of the breast tumors (malignant from benign). However, ultrasound scans are often noisy and include irrelevant parts of the breast that may bias the segmentation of eventual tumors. In this paper, we are going to extract the region of interest ( i.e, bounding boxes of the tumors) and feed-forward them to one semantic segmentation encoder-decoder structure based on its classification (i.e, malignant or benign). the whole process aims to build an instance-based segmenter from a semantic segmenter and an object detector.
Damaged Fingerprint Recognition by Convolutional Long Short-Term Memory Networks for Forensic Purposes
Dec 30, 2020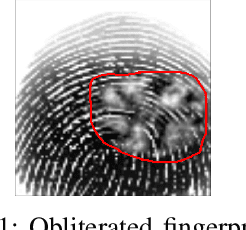
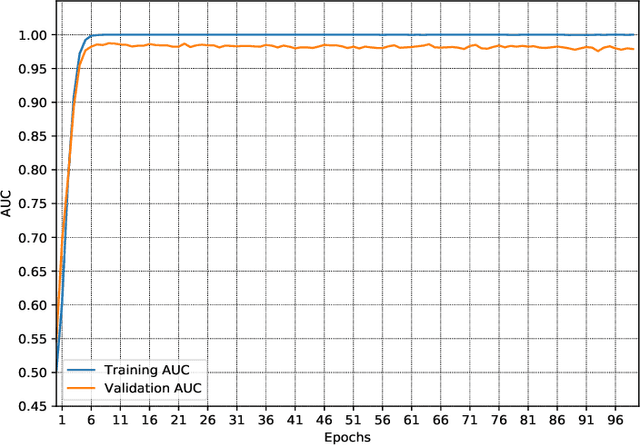

Fingerprint recognition is often a game-changing step in establishing evidence against criminals. However, we are increasingly finding that criminals deliberately alter their fingerprints in a variety of ways to make it difficult for technicians and automatic sensors to recognize their fingerprints, making it tedious for investigators to establish strong evidence against them in a forensic procedure. In this sense, deep learning comes out as a prime candidate to assist in the recognition of damaged fingerprints. In particular, convolution algorithms. In this paper, we focus on the recognition of damaged fingerprints by Convolutional Long Short-Term Memory networks. We present the architecture of our model and demonstrate its performance which exceeds 95% accuracy, 99% precision, and approaches 95% recall and 99% AUC.
RandomForestMLP: An Ensemble-Based Multi-Layer Perceptron Against Curse of Dimensionality
Nov 02, 2020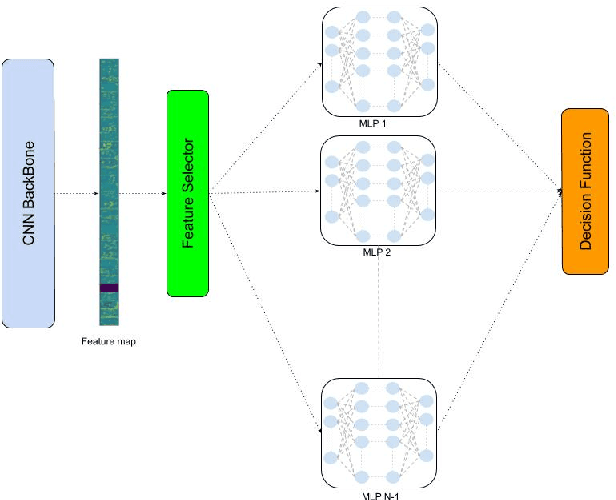
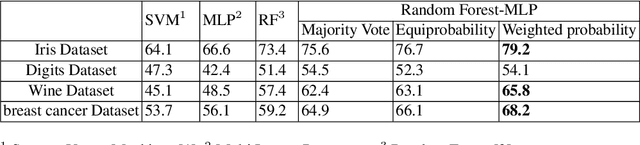
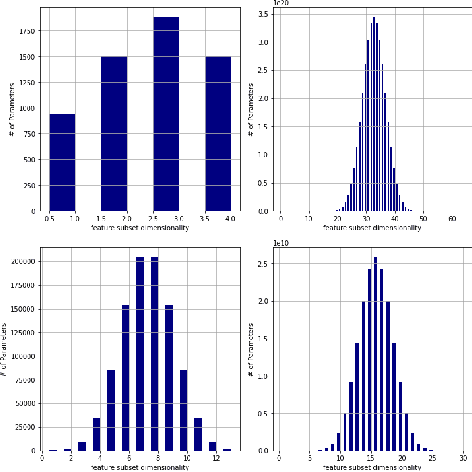
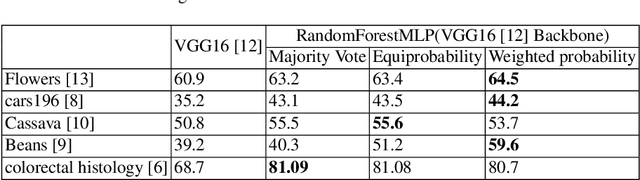
We present a novel and practical deep learning pipeline termed RandomForestMLP. This core trainable classification engine consists of a convolutional neural network backbone followed by an ensemble-based multi-layer perceptrons core for the classification task. It is designed in the context of self and semi-supervised learning tasks to avoid overfitting while training on very small datasets. The paper details the architecture of the RandomForestMLP and present different strategies for neural network decision aggregation. Then, it assesses its robustness to overfitting when trained on realistic image datasets and compares its classification performance with existing regular classifiers.
A Survey On 3D Inner Structure Prediction from its Outer Shape
Feb 11, 2020
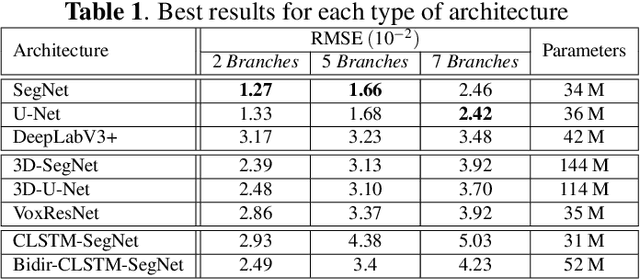
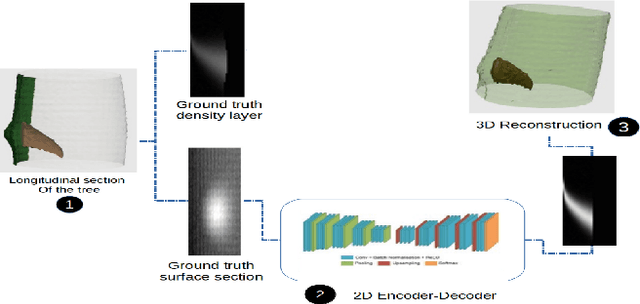

The analysis of the internal structure of trees is highly important for both forest experts, biological scientists, and the wood industry. Traditionally, CT-scanners are considered as the most efficient way to get an accurate inner representation of the tree. However, this method requires an important investment and reduces the cost-effectiveness of this operation. Our goal is to design neural-network-based methods to predict the internal density of the tree from its external bark shape. This paper compares different image-to-image(2D), volume-to-volume(3D) and Convolutional Long Short Term Memory based neural network architectures in the context of the prediction of the defect distribution inside trees from their external bark shape. Those models are trained on a synthetic dataset of 1800 CT-scanned look-like volumetric structures of the internal density of the trees and their corresponding external surface.