 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESOLVE: Relational Reasoning with Symbolic and Object-Level Features Using Vector Symbolic Processing
Nov 13, 2024Modern transformer-based encoder-decoder architectures struggle with reasoning tasks due to their inability to effectively extract relational information between input objects (data/tokens). Recent work introduced the Abstractor module, embedded between transformer layers, to address this gap. However, the Abstractor layer while excelling at capturing relational information (pure relational reasoning), faces challenges in tasks that require both object and relational-level reasoning (partial relational reasoning). To address this, we propose RESOLVE, a neuro-vector symbolic architecture that combines object-level features with relational representations in high-dimensional spaces, using fast and efficient operations such as bundling (summation) and binding (Hadamard product) allowing both object-level features and relational representations to coexist within the same structure without interfering with one another. RESOLVE is driven by a novel attention mechanism that operates in a bipolar high dimensional space, allowing fast attention score computation compared to the state-of-the-art. By leveraging this design, the model achieves both low compute latency and memory efficiency. RESOLVE also offers better generalizability while achieving higher accuracy in purely relational reasoning tasks such as sorting as well as partial relational reasoning tasks such as math problem-solving compared to state-of-the-art methods.
LARS-VSA: A Vector Symbolic Architecture For Learning with Abstract Rules
May 23, 2024



Human cognition excels at symbolic reasoning, deducing abstract rules from limited samples. This has been explained using symbolic and connectionist approaches, inspiring the development of a neuro-symbolic architecture that combines both paradigms. In parallel, recent studies have proposed the use of a "relational bottleneck" that separates object-level features from abstract rules, allowing learning from limited amounts of data . While powerful, it is vulnerable to the curse of compositionality meaning that object representations with similar features tend to interfere with each other. In this paper, we leverage hyperdimensional computing, which is inherently robust to such interference to build a compositional architecture. We adapt the "relational bottleneck" strategy to a high-dimensional space, incorporating explicit vector binding operations between symbols and relational representations. Additionally, we design a novel high-dimensional attention mechanism that leverages this relational representation. Our system benefits from the low overhead of operations in hyperdimensional space, making it significantly more efficient than the state of the art when evaluated on a variety of test datasets, while maintaining higher or equal accuracy.
A Novel Hyperdimensional Computing Framework for Online Time Series Forecasting on the Edge
Feb 03, 2024In recent years, both online and offline deep learning models have been developed for time series forecasting. However, offline deep forecasting models fail to adapt effectively to changes in time-series data, while online deep forecasting models are often expensive and have complex training procedures. In this paper, we reframe the online nonlinear time-series forecasting problem as one of linear hyperdimensional time-series forecasting. Nonlinear low-dimensional time-series data is mapped to high-dimensional (hyperdimensional) spaces for linear hyperdimensional prediction, allowing fast, efficient and lightweight online time-series forecasting. Our framework, TSF-HD, adapts to time-series distribution shifts using a novel co-training framework for its hyperdimensional mapping and its linear hyperdimensional predictor. TSF-HD is shown to outperform the state of the art, while having reduced inference latency, for both short-term and long-term time series forecasting. Our code is publicly available at http://github.com/tsfhd2024/tsf-hd.git
TESDA: Transform Enabled Statistical Detection of Attacks in Deep Neural Networks
Oct 16, 2021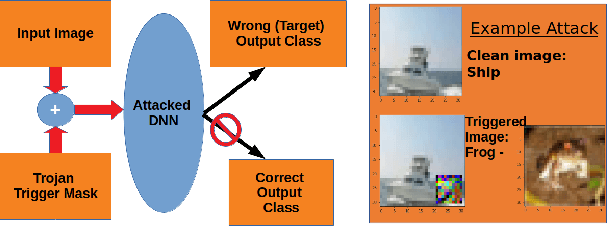
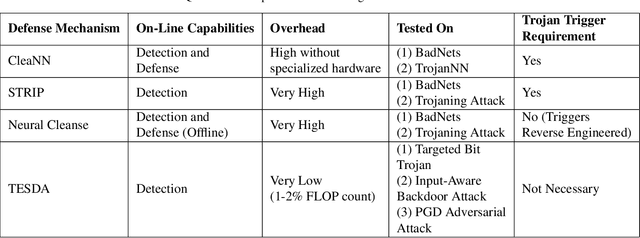
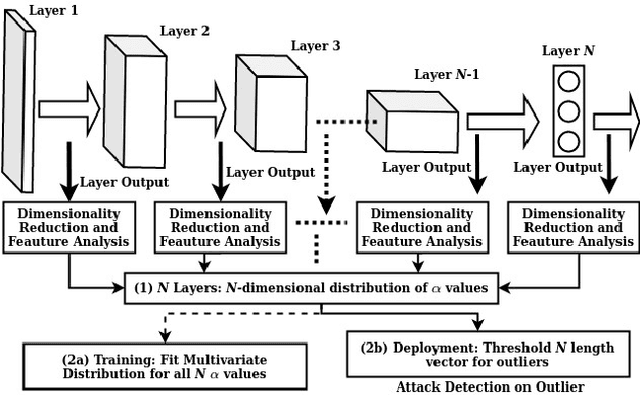
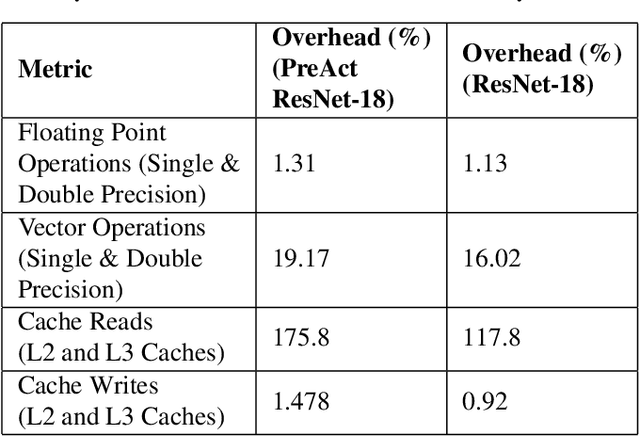
Deep neural networks (DNNs) are now the de facto choice for computer vision tasks such as image classification. However, their complexity and "black box" nature often renders the systems they're deployed in vulnerable to a range of security threats. Successfully identifying such threats, especially in safety-critical real-world applications is thus of utmost importance, but still very much an open problem. We present TESDA, a low-overhead, flexible, and statistically grounded method for {online detection} of attacks by exploiting the discrepancies they cause in the distributions of intermediate layer features of DNNs. Unlike most prior work, we require neither dedicated hardware to run in real-time, nor the presence of a Trojan trigger to detect discrepancies in behavior. We empirically establish our method's usefulness and practicality across multiple architectures, datasets and diverse attacks, consistently achieving detection coverages of above 95% with operation count overheads as low as 1-2%.