 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectly Optimizing IoU for Bounding Box Localization
Apr 14, 2023Object detection has seen remarkable progress in recent years with the introduction of Convolutional Neural Networks (CNN). Object detection is a multi-task learning problem where both the position of the objects in the images as well as their classes needs to be correctly identified. The idea here is to maximize the overlap between the ground-truth bounding boxes and the predictions i.e. the Intersection over Union (IoU). In the scope of work seen currently in this domain, IoU is approximated by using the Huber loss as a proxy but this indirect method does not leverage the IoU information and treats the bounding box as four independent, unrelated terms of regression. This is not true for a bounding box where the four coordinates are highly correlated and hold a semantic meaning when taken together. The direct optimization of the IoU is not possible due to its non-convex and non-differentiable nature. In this paper, we have formulated a novel loss namely, the Smooth IoU, which directly optimizes the IoUs for the bounding boxes. This loss has been evaluated on the Oxford IIIT Pets, Udacity self-driving car, PASCAL VOC, and VWFS Car Damage datasets and has shown performance gains over the standard Huber loss.
Phantom Embeddings: Using Embedding Space for Model Regularization in Deep Neural Networks
Apr 14, 2023The strength of machine learning models stems from their ability to learn complex function approximations from data; however, this strength also makes training deep neural networks challenging. Notably, the complex models tend to memorize the training data, which results in poor regularization performance on test data. The regularization techniques such as L1, L2, dropout, etc. are proposed to reduce the overfitting effect; however, they bring in additional hyperparameters tuning complexity. These methods also fall short when the inter-class similarity is high due to the underlying data distribution, leading to a less accurate model. In this paper, we present a novel approach to regularize the models by leveraging the information-rich latent embeddings and their high intra-class correlation. We create phantom embeddings from a subset of homogenous samples and use these phantom embeddings to decrease the inter-class similarity of instances in their latent embedding space. The resulting models generalize better as a combination of their embedding and regularize them without requiring an expensive hyperparameter search. We evaluate our method on two popular and challenging image classification datasets (CIFAR and FashionMNIST) and show how our approach outperforms the standard baselines while displaying better training behavior.
A.I. and Data-Driven Mobility at Volkswagen Financial Services AG
Feb 09, 2022Machine learning is being widely adapted in industrial applications owing to the capabilities of commercially available hardware and rapidly advancing research. Volkswagen Financial Services (VWFS), as a market leader in vehicle leasing services, aims to leverage existing proprietary data and the latest research to enhance existing and derive new business processes. The collaboration between Information Systems and Machine Learning Lab (ISMLL) and VWFS serves to realize this goal. In this paper, we propose methods in the fields of recommender systems, object detection, and forecasting that enable data-driven decisions for the vehicle life-cycle at VWFS.
Disturbing Target Values for Neural Network Regularization
Oct 11, 2021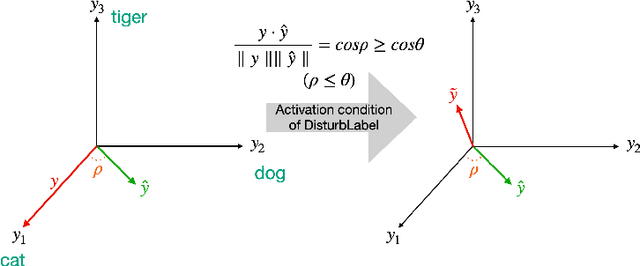
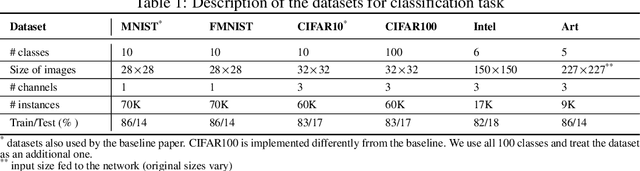
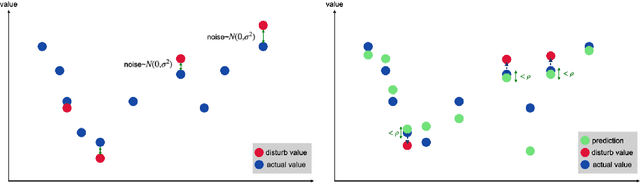
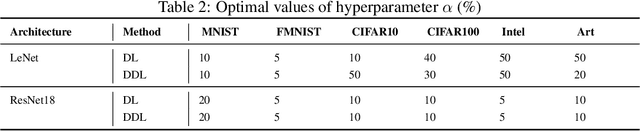
Diverse regularization techniques have been developed such as L2 regularization, Dropout, DisturbLabel (DL) to prevent overfitting. DL, a newcomer on the scene, regularizes the loss layer by flipping a small share of the target labels at random and training the neural network on this distorted data so as to not learn the training data. It is observed that high confidence labels during training cause the overfitting problem and DL selects disturb labels at random regardless of the confidence of labels. To solve this shortcoming of DL, we propose Directional DisturbLabel (DDL) a novel regularization technique that makes use of the class probabilities to infer the confident labels and using these labels to regularize the model. This active regularization makes use of the model behavior during training to regularize it in a more directed manner. To address regression problems, we also propose DisturbValue (DV), and DisturbError (DE). DE uses only predefined confident labels to disturb target values. DV injects noise into a portion of target values at random similar to DL. In this paper, 6 and 8 datasets are used to validate the robustness of our methods in classification and regression tasks respectively. Finally, we demonstrate that our methods are either comparable to or outperform DisturbLabel, L2 regularization, and Dropout. Also, we achieve the best performance in more than half the datasets by combining our methods with either L2 regularization or Dropout.