 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-reducing attention cross fusion learning transformer for histological image classification of osteosarcoma
Apr 29, 2022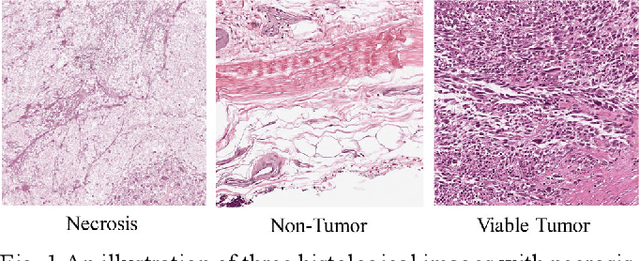
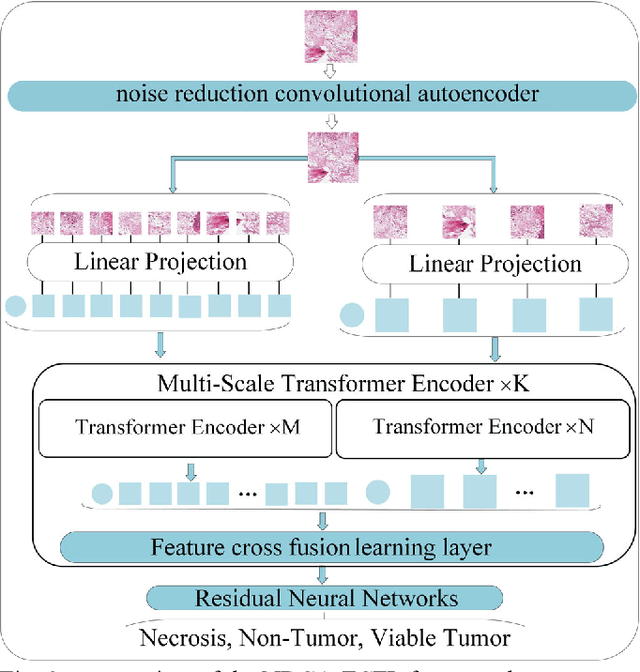
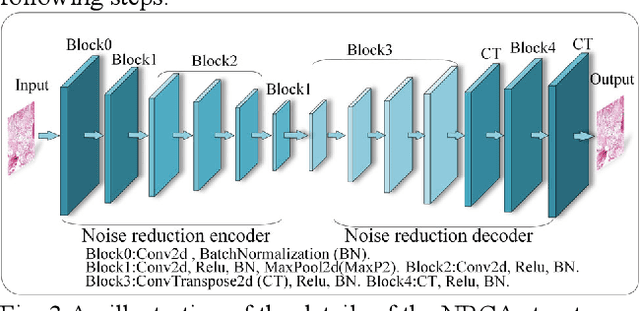
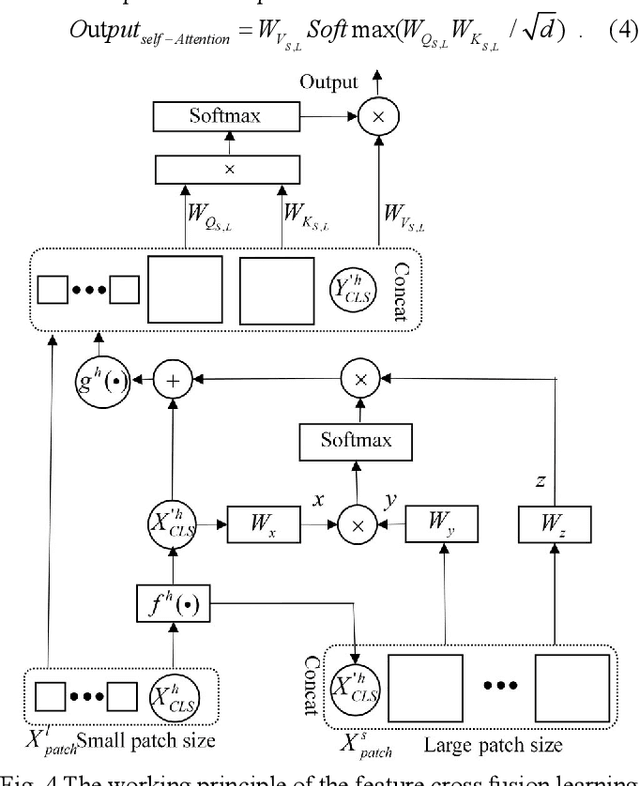
The degree of malignancy of osteosarcoma and its tendency to metastasize/spread mainly depend on the pathological grade (determined by observing the morphology of the tumor under a microscope). The purpose of this study is to use artificial intelligence to classify osteosarcoma histological images and to assess tumor survival and necrosis, which will help doctors reduce their workload, improve the accuracy of osteosarcoma cancer detection, and make a better prognosis for patients. The study proposes a typical transformer image classification framework by integrating noise reduction convolutional autoencoder and feature cross fusion learning (NRCA-FCFL) to classify osteosarcoma histological images. Noise reduction convolutional autoencoder could well denoise histological images of osteosarcoma, resulting in more pure images for osteosarcoma classification. Moreover, we introduce feature cross fusion learning, which integrates two scale image patches, to sufficiently explore their interactions by using additional classification tokens. As a result, a refined fusion feature is generated, which is fed to the residual neural network for label predictions. We conduct extensive experiments to evaluate the performance of the proposed approach. The experimental results demonstrate that our method outperforms the traditional and deep learning approaches on various evaluation metrics, with an accuracy of 99.17% to support osteosarcoma diagnosis.
FEDI: Few-shot learning based on Earth Mover's Distance algorithm combined with deep residual network to identify diabetic retinopathy
Aug 22, 2021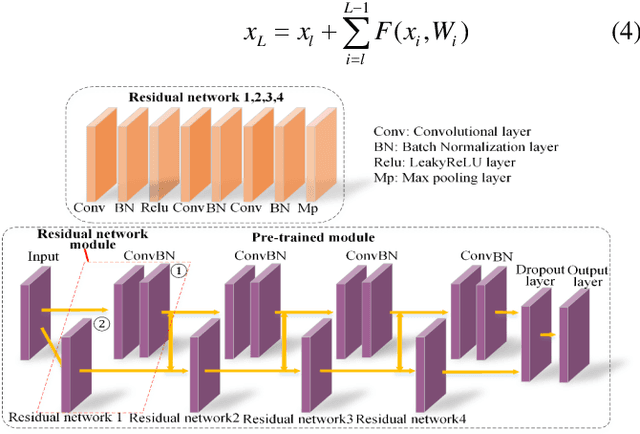

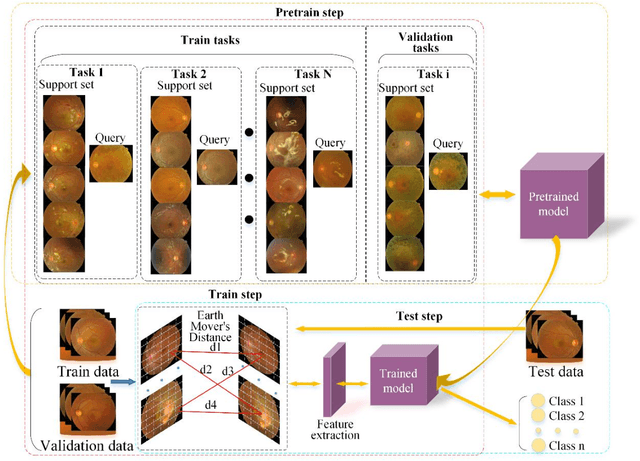
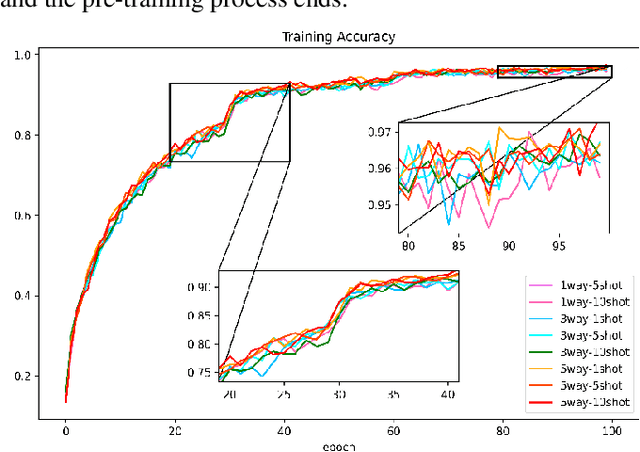
Diabetic retinopathy(DR) is the main cause of blindness in diabetic patients. However, DR can easily delay the occurrence of blindness through the diagnosis of the fundus. In view of the reality, it is difficult to collect a large amount of diabetic retina data in clinical practice. This paper proposes a few-shot learning model of a deep residual network based on Earth Mover's Distance algorithm to assist in diagnosing DR. We build training and validation classification tasks for few-shot learning based on 39 categories of 1000 sample data, train deep residual networks, and obtain experience maximization pre-training models. Based on the weights of the pre-trained model, the Earth Mover's Distance algorithm calculates the distance between the images, obtains the similarity between the images, and changes the model's parameters to improve the accuracy of the training model. Finally, the experimental construction of the small sample classification task of the test set to optimize the model further, and finally, an accuracy of 93.5667% on the 3way10shot task of the diabetic retina test set. For the experimental code and results, please refer to: https://github.com/panliangrui/few-shot-learning-funds.
A review of artificial intelligence methods combined with Raman spectroscopy to identify the composition of substances
Apr 05, 2021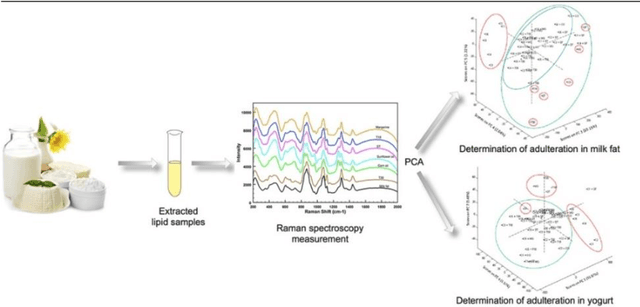
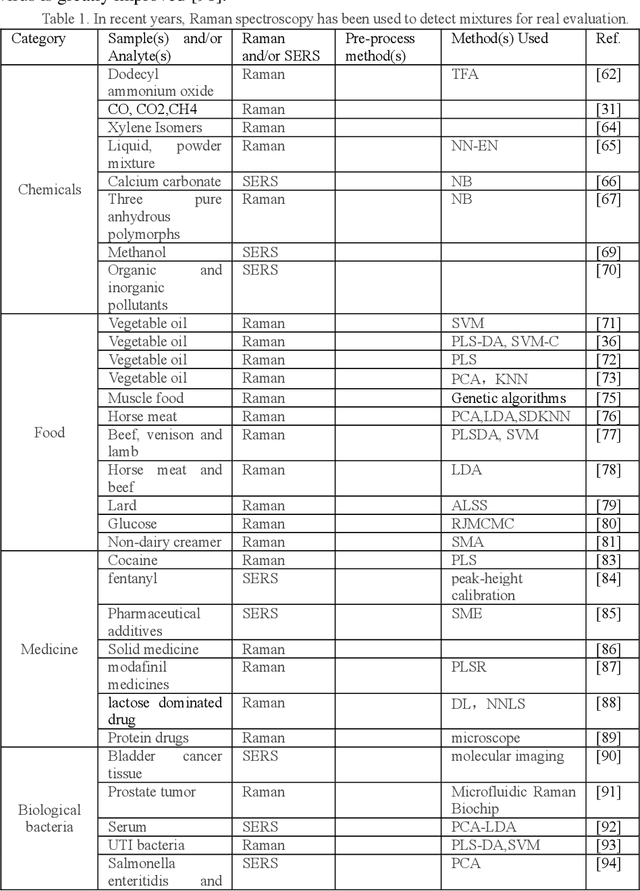
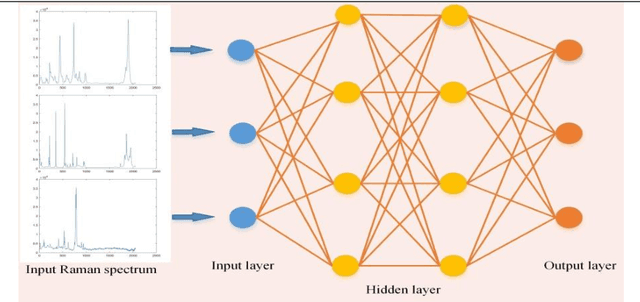
In general, most of the substances in nature exist in mixtures, and the noninvasive identification of mixture composition with high speed and accuracy remains a difficult task. However, the development of Raman spectroscopy, machine learning, and deep learning techniques have paved the way for achieving efficient analytical tools capable of identifying mixture components, making an apparent breakthrough in the identification of mixtures beyond the traditional chemical analysis methods. This article summarizes the work of Raman spectroscopy in identifying the composition of substances as well as provides detailed reviews on the preprocessing process of Raman spectroscopy, the analysis methods and applications of artificial intelligence. This review summarizes the work of Raman spectroscopy in identifying the composition of substances and reviews the preprocessing process of Raman spectroscopy, the analysis methods and applications of artificial intelligence. Finally, the advantages and disadvantages and development prospects of Raman spectroscopy are discussed in detail.
Identification of complex mixtures for Raman spectroscopy using a novel scheme based on a new multi-label deep neural network
Oct 29, 2020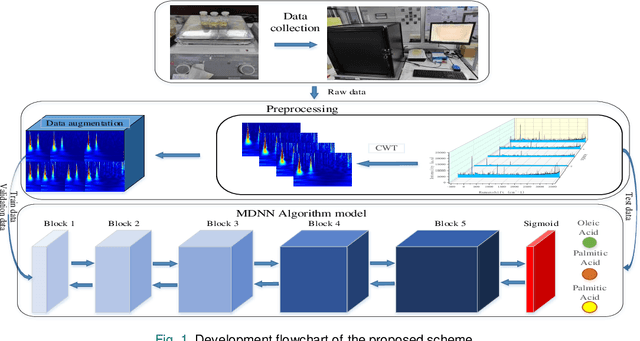
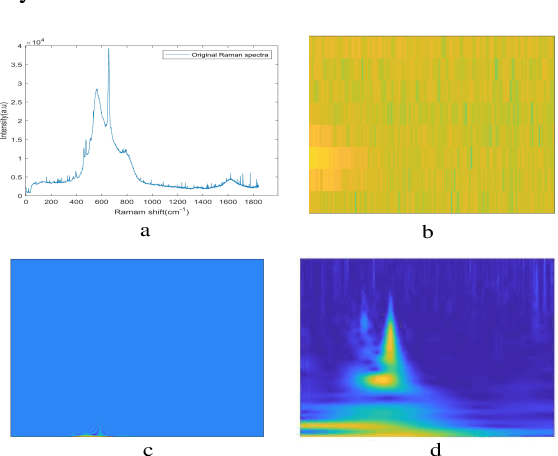
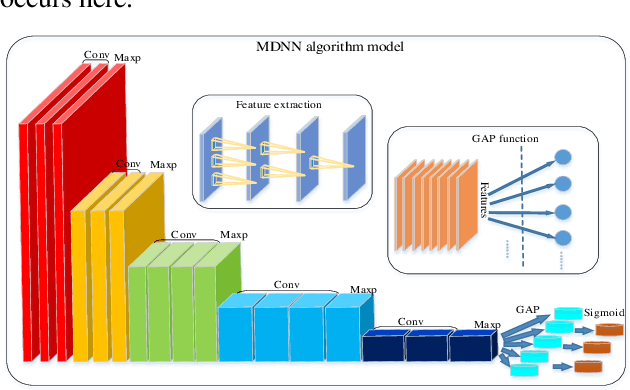
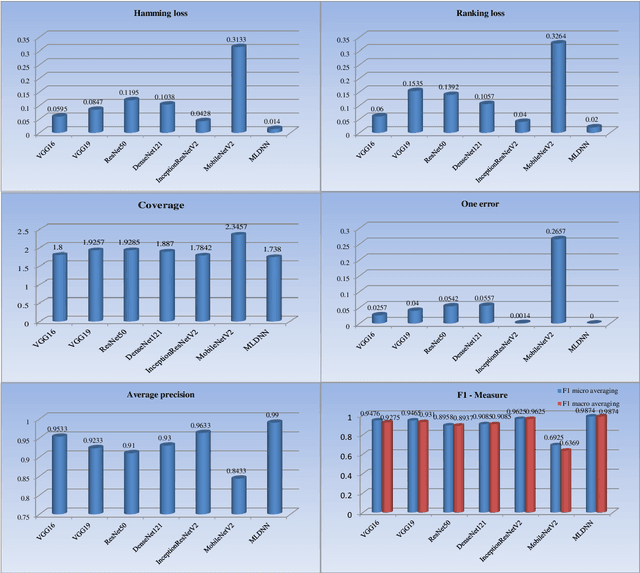
With noisy environment caused by fluoresence and additive white noise as well as complicated spectrum fingerprints, the identification of complex mixture materials remains a major challenge in Raman spectroscopy application. In this paper, we propose a new scheme based on a constant wavelet transform (CWT) and a deep network for classifying complex mixture. The scheme first transforms the noisy Raman spectrum to a two-dimensional scale map using CWT. A multi-label deep neural network model (MDNN) is then applied for classifying material. The proposed model accelerates the feature extraction and expands the feature graph using the global averaging pooling layer. The Sigmoid function is implemented in the last layer of the model. The MDNN model was trained, validated and tested with data collected from the samples prepared from substances in palm oil. During training and validating process, data augmentation is applied to overcome the imbalance of data and enrich the diversity of Raman spectra. From the test results, it is found that the MDNN model outperforms previously proposed deep neural network models in terms of Hamming loss, one error, coverage, ranking loss, average precision, F1 macro averaging and F1 micro averaging, respectively. The average detection time obtained from our model is 5.31 s, which is much faster than the detection time of the previously proposed models.
Method for classifying a noisy Raman spectrum based on a wavelet transform and a deep neural network
Sep 09, 2020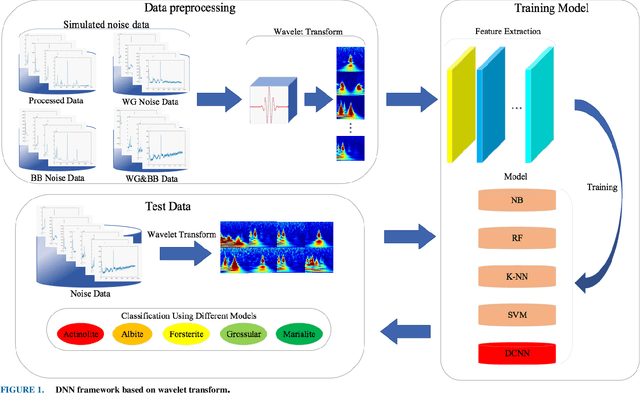
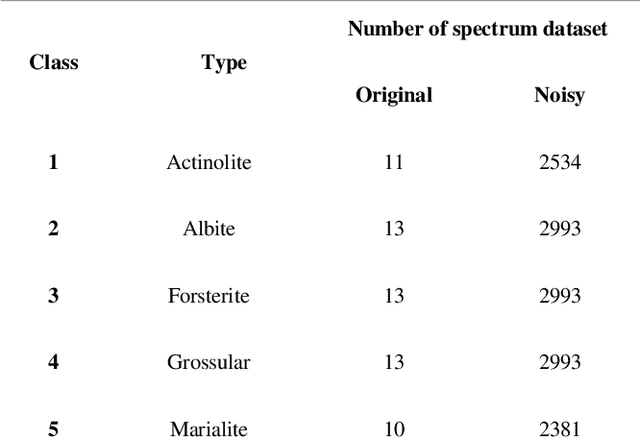
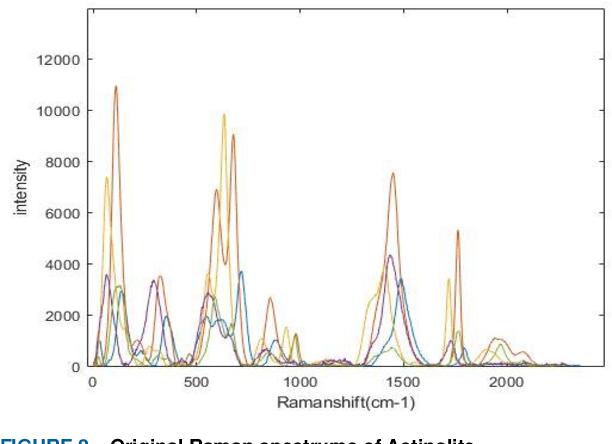
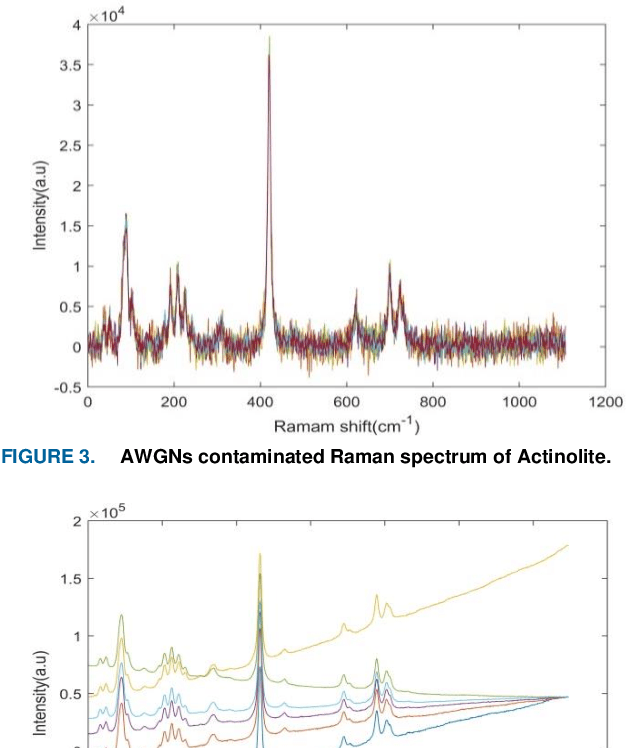
This paper proposes a new framework based on a wavelet transform and deep neural network for identifying noisy Raman spectrum since, in practice, it is relatively difficult to classify the spectrum under baseline noise and additive white Gaussian noise environments. The framework consists of two main engines. Wavelet transform is proposed as the framework front-end for transforming 1-D noise Raman spectrum to two-dimensional data. This two-dimensional data will be fed to the framework back-end which is a classifier. The optimum classifier is chosen by implementing several traditional machine learning (ML) and deep learning (DL) algorithms, and then we investigated their classification accuracy and robustness performances. The four MLs we choose included a Naive Bayes (NB), a Support Vector Machine (SVM), a Random Forest (RF) and a K-Nearest Neighbor (KNN) where a deep convolution neural network (DCNN) was chosen for a DL classifier. Noise-free, Gaussian noise, baseline noise, and mixed-noise Raman spectrums were applied to train and validate the ML and DCNN models. The optimum back-end classifier was obtained by testing the ML and DCNN models with several noisy Raman spectrums (10-30 dB noise power). Based on the simulation, the accuracy of the DCNN classifier is 9% higher than the NB classifier, 3.5% higher than the RF classifier, 1% higher than the KNN classifier, and 0.5% higher than the SVM classifier. In terms of robustness to the mixed noise scenarios, the framework with DCNN back-end showed superior performance than the other ML back-ends. The DCNN back-end achieved 90% accuracy at 3 dB SNR while NB, SVM, RF, and K-NN back-ends required 27 dB, 22 dB, 27 dB, and 23 dB SNR, respectively. In addition, in the low-noise test data set, the F-measure score of the DCNN back-end exceeded 99.1% while the F-measure scores of the other ML engines were below 98.7%.