 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Knowledge-Intensive Text-to-SQL Semantic Parsing with Formulaic Knowledge
Jan 03, 2023



In this paper, we study the problem of knowledge-intensive text-to-SQL, in which domain knowledge is necessary to parse expert questions into SQL queries over domain-specific tables. We formalize this scenario by building a new Chinese benchmark KnowSQL consisting of domain-specific questions covering various domains. We then address this problem by presenting formulaic knowledge, rather than by annotating additional data examples. More concretely, we construct a formulaic knowledge bank as a domain knowledge base and propose a framework (ReGrouP) to leverage this formulaic knowledge during parsing. Experiments using ReGrouP demonstrate a significant 28.2% improvement overall on KnowSQL.
MultiSpider: Towards Benchmarking Multilingual Text-to-SQL Semantic Parsing
Dec 27, 2022Text-to-SQL semantic parsing is an important NLP task, which greatly facilitates the interaction between users and the database and becomes the key component in many human-computer interaction systems. Much recent progress in text-to-SQL has been driven by large-scale datasets, but most of them are centered on English. In this work, we present MultiSpider, the largest multilingual text-to-SQL dataset which covers seven languages (English, German, French, Spanish, Japanese, Chinese, and Vietnamese). Upon MultiSpider, we further identify the lexical and structural challenges of text-to-SQL (caused by specific language properties and dialect sayings) and their intensity across different languages. Experimental results under three typical settings (zero-shot, monolingual and multilingual) reveal a 6.1% absolute drop in accuracy in non-English languages. Qualitative and quantitative analyses are conducted to understand the reason for the performance drop of each language. Besides the dataset, we also propose a simple schema augmentation framework SAVe (Schema-Augmentation-with-Verification), which significantly boosts the overall performance by about 1.8% and closes the 29.5% performance gap across languages.
UniSAr: A Unified Structure-Aware Autoregressive Language Model for Text-to-SQL
Apr 13, 2022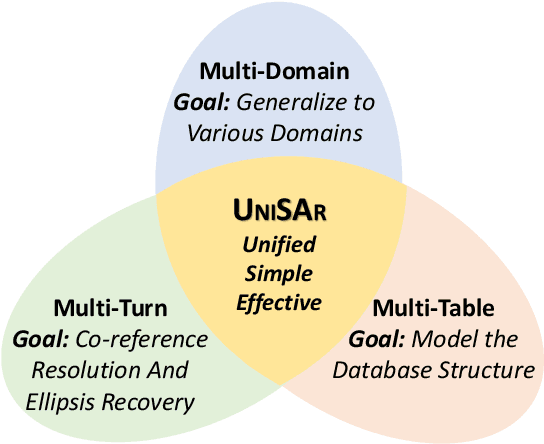
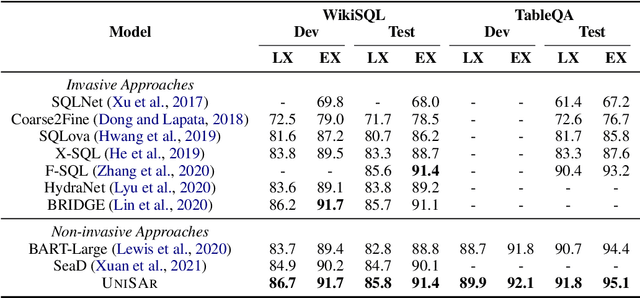
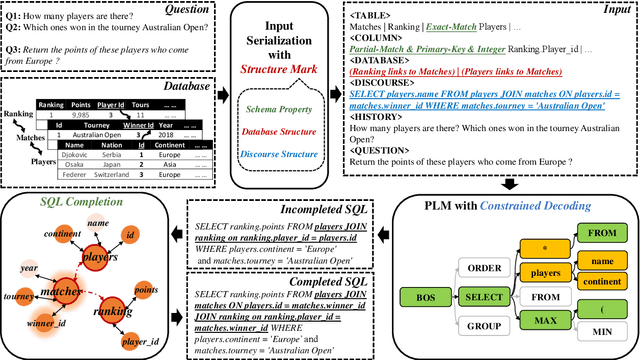
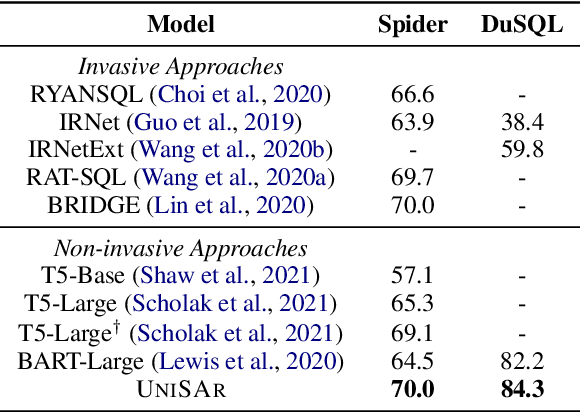
Existing text-to-SQL semantic parsers are typically designed for particular settings such as handling queries that span multiple tables, domains or turns which makes them ineffective when applied to different settings. We present UniSAr (Unified Structure-Aware Autoregressive Language Model), which benefits from directly using an off-the-shelf language model architecture and demonstrates consistently high performance under different settings. Specifically, UniSAr extends existing autoregressive language models to incorporate three non-invasive extensions to make them structure-aware: (1) adding structure mark to encode database schema, conversation context, and their relationships; (2) constrained decoding to decode well structured SQL for a given database schema; and (3) SQL completion to complete potential missing JOIN relationships in SQL based on database schema. On seven well-known text-to-SQL datasets covering multi-domain, multi-table and multi-turn, UniSAr demonstrates highly comparable or better performance to the most advanced specifically-designed text-to-SQL models. Importantly, our UniSAr is non-invasive, such that other core model advances in text-to-SQL can also adopt our extensions to further enhance performance.