 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring evolution-based & -free protein language models as protein function predictors
Jun 14, 2022
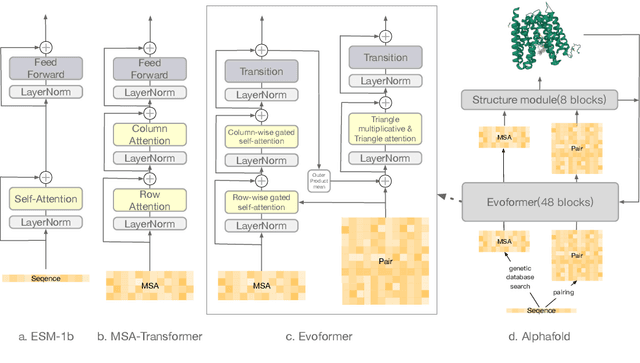

Large-scale Protein Language Models (PLMs) have improved performance in protein prediction tasks, ranging from 3D structure prediction to various function predictions. In particular, AlphaFold, a ground-breaking AI system, could potentially reshape structural biology. However, the utility of the PLM module in AlphaFold, Evoformer, has not been explored beyond structure prediction. In this paper, we investigate the representation ability of three popular PLMs: ESM-1b (single sequence), MSA-Transformer (multiple sequence alignment) and Evoformer (structural), with a special focus on Evoformer. Specifically, we aim to answer the following key questions: (i) Does the Evoformer trained as part of AlphaFold produce representations amenable to predicting protein function? (ii) If yes, can Evoformer replace ESM-1b and MSA-Transformer? (iii) How much do these PLMs rely on evolution-related protein data? In this regard, are they complementary to each other? We compare these models by empirical study along with new insights and conclusions. Finally, we release code and datasets for reproducibility.
Off-Policy Evaluation of Probabilistic Identity Data in Lookalike Modeling
Jan 04, 2019
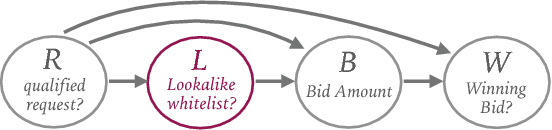
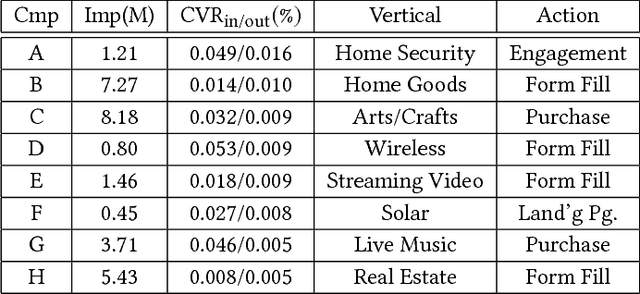
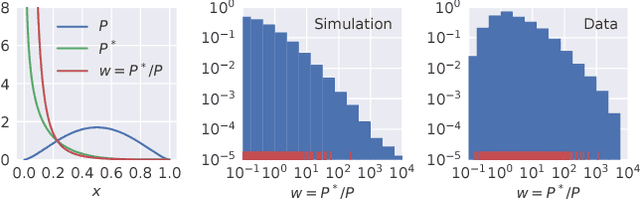
We evaluate the impact of probabilistically-constructed digital identity data collected from Sep. to Dec. 2017 (approx.), in the context of Lookalike-targeted campaigns. The backbone of this study is a large set of probabilistically-constructed "identities", represented as small bags of cookies and mobile ad identifiers with associated metadata, that are likely all owned by the same underlying user. The identity data allows to generate "identity-based", rather than "identifier-based", user models, giving a fuller picture of the interests of the users underlying the identifiers. We employ off-policy techniques to evaluate the potential of identity-powered lookalike models without incurring the risk of allowing untested models to direct large amounts of ad spend or the large cost of performing A/B tests. We add to historical work on off-policy evaluation by noting a significant type of "finite-sample bias" that occurs for studies combining modestly-sized datasets and evaluation metrics involving rare events (e.g., conversions). We illustrate this bias using a simulation study that later informs the handling of inverse propensity weights in our analyses on real data. We demonstrate significant lift in identity-powered lookalikes versus an identity-ignorant baseline: on average ~70% lift in conversion rate. This rises to factors of ~(4-32)x for identifiers having little data themselves, but that can be inferred to belong to users with substantial data to aggregate across identifiers. This implies that identity-powered user modeling is especially important in the context of identifiers having very short lifespans (i.e., frequently churned cookies). Our work motivates and informs the use of probabilistically-constructed identities in marketing. It also deepens the canon of examples in which off-policy learning has been employed to evaluate the complex systems of the internet economy.