 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlugin Networks for Inference under Partial Evidence
Jan 02, 2019
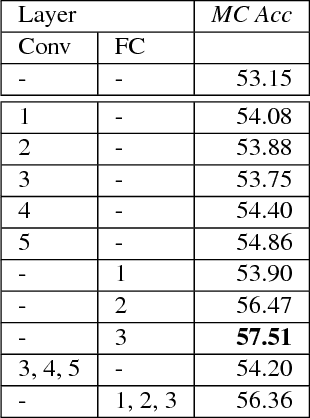

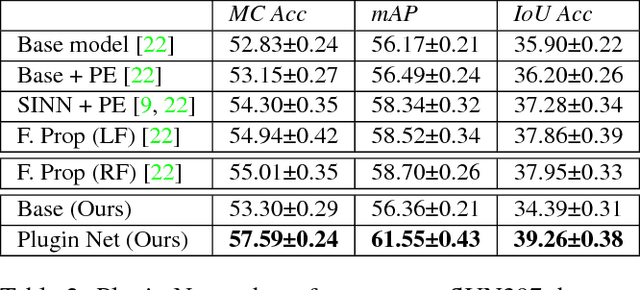
In this paper, we propose a novel method to incorporate partial evidence in the inference of deep convolutional neural networks. Contrary to the existing methods, which either iteratively modify the input of the network or exploit external label taxonomy to take partial evidence into account, we add separate network modules to the intermediate layers of a pre-trained convolutional network. The goal of those modules is to incorporate additional signal - information about known labels - into the inference procedure and adjust the predicted outputs accordingly. Since the attached "Plugin Networks", have a simple structure consisting of only fully connected layers, we drastically reduce the computational cost of training and inference. At the same time, the proposed architecture allows to propagate the information about known labels directly to the intermediate layers that are trained to intrinsically model correlations between the labels. Extensive evaluation of the proposed method confirms that our Plugin Networks outperform the state-of-the-art in a variety of tasks, including scene categorization and multi-label image annotation.
Deep-Temporal LSTM for Daily Living Action Recognition
Jun 15, 2018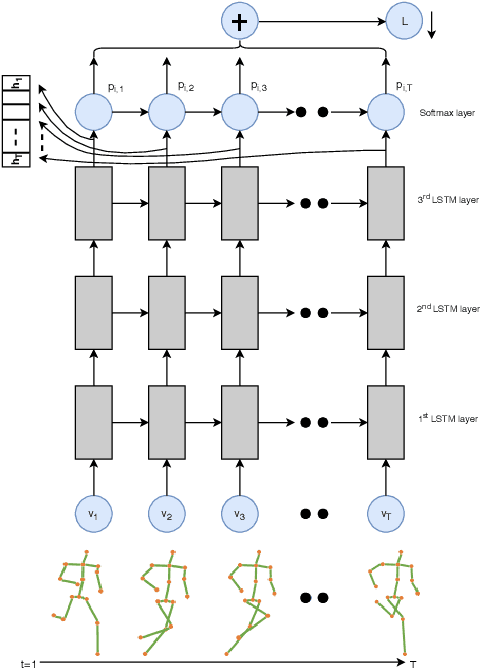
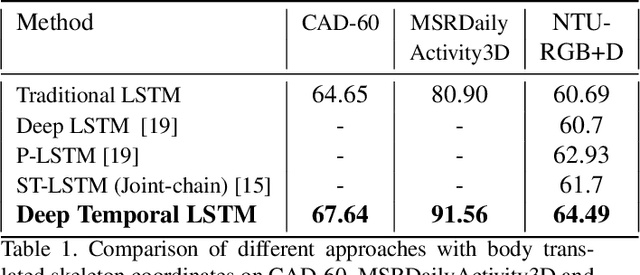
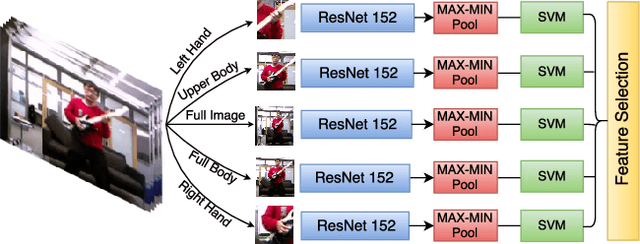
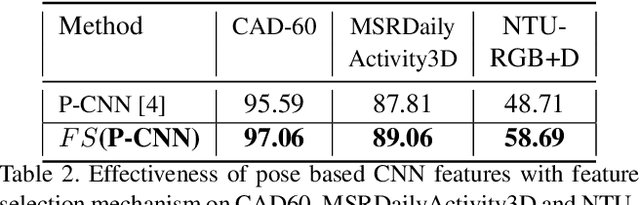
In this paper, we propose to improve the traditional use of RNNs by employing a many to many model for video classification. We analyze the importance of modeling spatial layout and temporal encoding for daily living action recognition. Many RGB methods focus only on short term temporal information obtained from optical flow. Skeleton based methods on the other hand show that modeling long term skeleton evolution improves action recognition accuracy. In this work, we propose a deep-temporal LSTM architecture which extends standard LSTM and allows better encoding of temporal information. In addition, we propose to fuse 3D skeleton geometry with deep static appearance. We validate our approach on public available CAD60, MSRDailyActivity3D and NTU-RGB+D, achieving competitive performance as compared to the state-of-the art.