 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Temporal LSTM for Daily Living Action Recognition
Paper and Code
Jun 15, 2018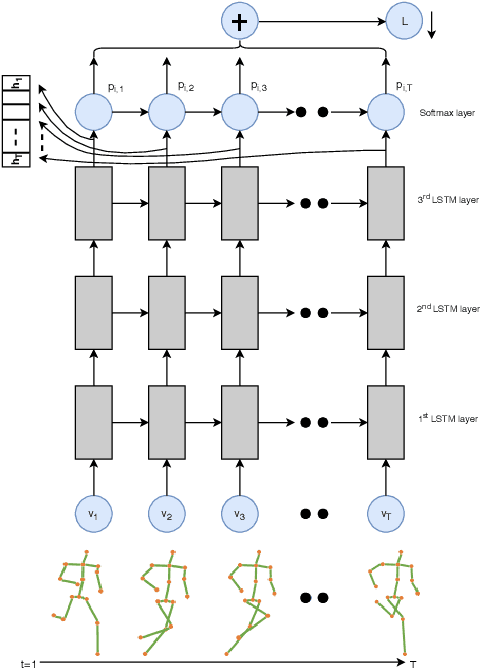
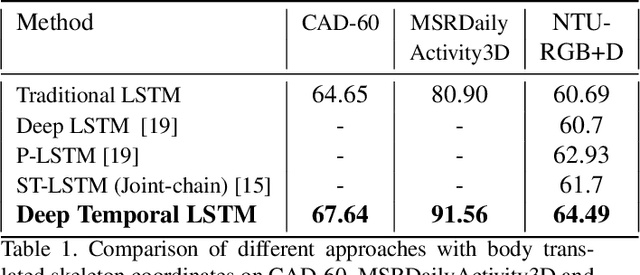
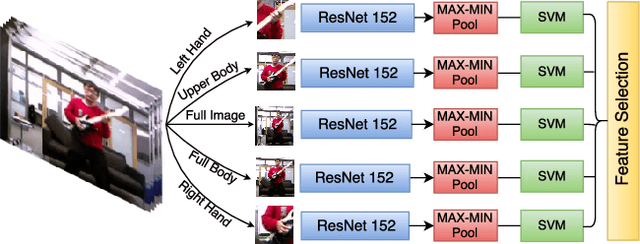
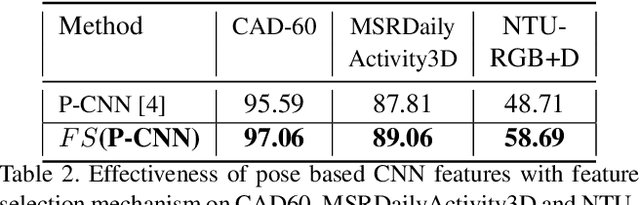
In this paper, we propose to improve the traditional use of RNNs by employing a many to many model for video classification. We analyze the importance of modeling spatial layout and temporal encoding for daily living action recognition. Many RGB methods focus only on short term temporal information obtained from optical flow. Skeleton based methods on the other hand show that modeling long term skeleton evolution improves action recognition accuracy. In this work, we propose a deep-temporal LSTM architecture which extends standard LSTM and allows better encoding of temporal information. In addition, we propose to fuse 3D skeleton geometry with deep static appearance. We validate our approach on public available CAD60, MSRDailyActivity3D and NTU-RGB+D, achieving competitive performance as compared to the state-of-the art.