 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Olives with Synthetic or Real Data? Olive the Above
Aug 16, 2023



Modern robotics has enabled the advancement in yield estimation for precision agriculture. However, when applied to the olive industry, the high variation of olive colors and their similarity to the background leaf canopy presents a challenge. Labeling several thousands of very dense olive grove images for segmentation is a labor-intensive task. This paper presents a novel approach to detecting olives without the need to manually label data. In this work, we present the world's first olive detection dataset comprised of synthetic and real olive tree images. This is accomplished by generating an auto-labeled photorealistic 3D model of an olive tree. Its geometry is then simplified for lightweight rendering purposes. In addition, experiments are conducted with a mix of synthetically generated and real images, yielding an improvement of up to 66% compared to when only using a small sample of real data. When access to real, human-labeled data is limited, a combination of mostly synthetic data and a small amount of real data can enhance olive detection.
Algorithms and Bounds for Rollout Sampling Approximate Policy Iteration
Jul 18, 2008Several approximate policy iteration schemes without value functions, which focus on policy representation using classifiers and address policy learning as a supervised learning problem, have been proposed recently. Finding good policies with such methods requires not only an appropriate classifier, but also reliable examples of best actions, covering the state space sufficiently. Up to this time, little work has been done on appropriate covering schemes and on methods for reducing the sample complexity of such methods, especially in continuous state spaces. This paper focuses on the simplest possible covering scheme (a discretized grid over the state space) and performs a sample-complexity comparison between the simplest (and previously commonly used) rollout sampling allocation strategy, which allocates samples equally at each state under consideration, and an almost as simple method, which allocates samples only as needed and requires significantly fewer samples.
Rollout Sampling Approximate Policy Iteration
Jul 06, 2008
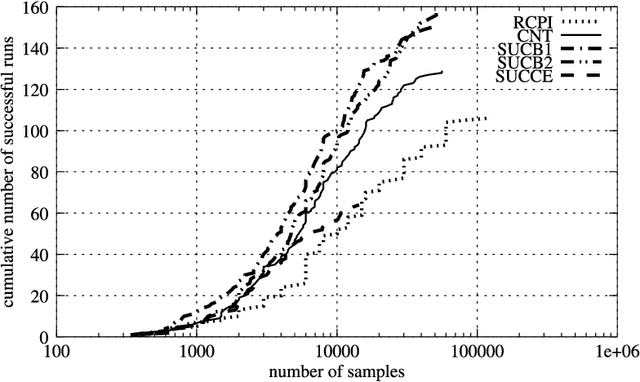
Several researchers have recently investigated the connection between reinforcement learning and classification. We are motivated by proposals of approximate policy iteration schemes without value functions which focus on policy representation using classifiers and address policy learning as a supervised learning problem. This paper proposes variants of an improved policy iteration scheme which addresses the core sampling problem in evaluating a policy through simulation as a multi-armed bandit machine. The resulting algorithm offers comparable performance to the previous algorithm achieved, however, with significantly less computational effort. An order of magnitude improvement is demonstrated experimentally in two standard reinforcement learning domains: inverted pendulum and mountain-car.