 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRollout Sampling Approximate Policy Iteration
Paper and Code
Jul 06, 2008
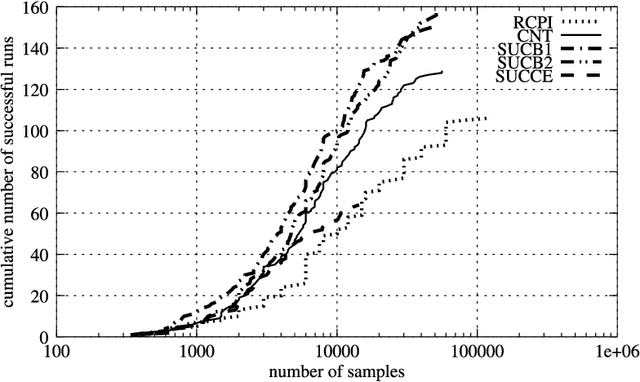
Several researchers have recently investigated the connection between reinforcement learning and classification. We are motivated by proposals of approximate policy iteration schemes without value functions which focus on policy representation using classifiers and address policy learning as a supervised learning problem. This paper proposes variants of an improved policy iteration scheme which addresses the core sampling problem in evaluating a policy through simulation as a multi-armed bandit machine. The resulting algorithm offers comparable performance to the previous algorithm achieved, however, with significantly less computational effort. An order of magnitude improvement is demonstrated experimentally in two standard reinforcement learning domains: inverted pendulum and mountain-car.