 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEX: Human-in-the-loop Explainability via Deep Reinforcement Learning
Jun 02, 2022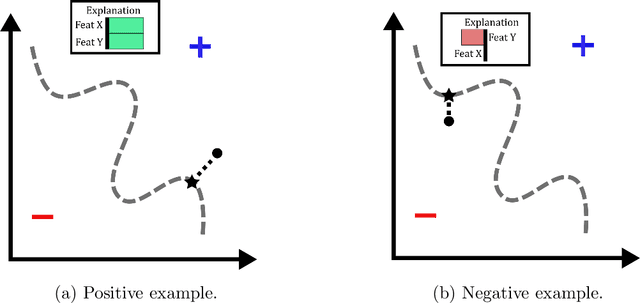
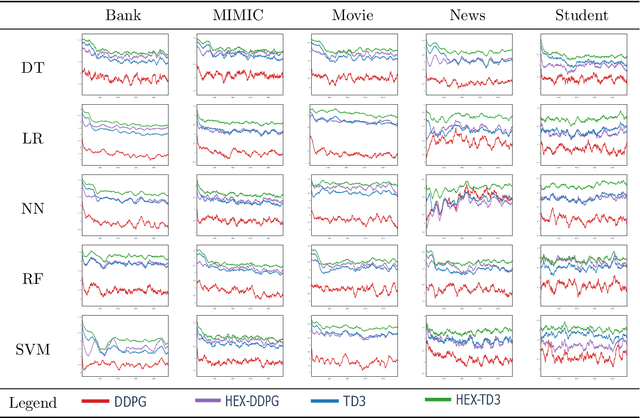
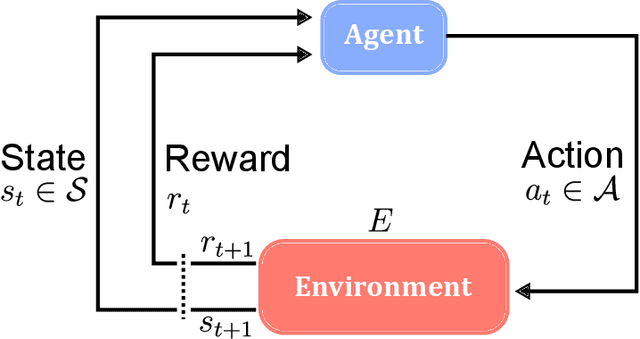
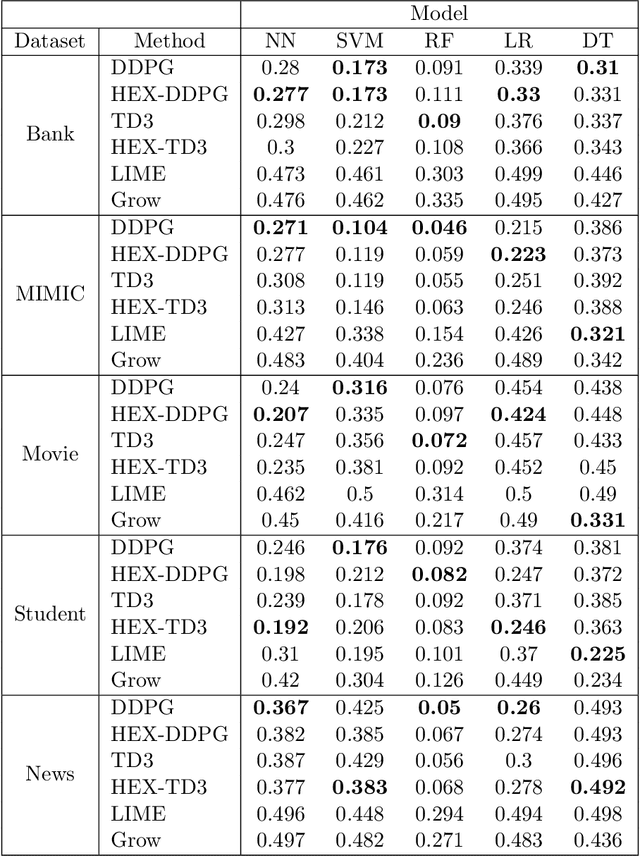
The use of machine learning (ML) models in decision-making contexts, particularly those used in high-stakes decision-making, are fraught with issue and peril since a person - not a machine - must ultimately be held accountable for the consequences of the decisions made using such systems. Machine learning explainability (MLX) promises to provide decision-makers with prediction-specific rationale, assuring them that the model-elicited predictions are made for the right reasons and are thus reliable. Few works explicitly consider this key human-in-the-loop (HITL) component, however. In this work we propose HEX, a human-in-the-loop deep reinforcement learning approach to MLX. HEX incorporates 0-distrust projection to synthesize decider specific explanation-providing policies from any arbitrary classification model. HEX is also constructed to operate in limited or reduced training data scenarios, such as those employing federated learning. Our formulation explicitly considers the decision boundary of the ML model in question, rather than the underlying training data, which is a shortcoming of many model-agnostic MLX methods. Our proposed methods thus synthesize HITL MLX policies that explicitly capture the decision boundary of the model in question for use in limited data scenarios.
Personalized Cardiovascular Disease Risk Mitigation via Longitudinal Inverse Classification
Nov 16, 2020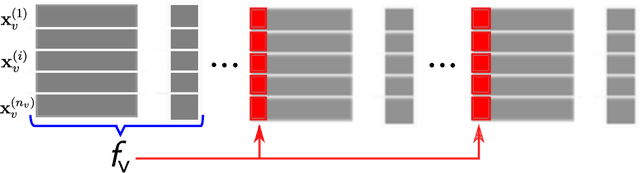
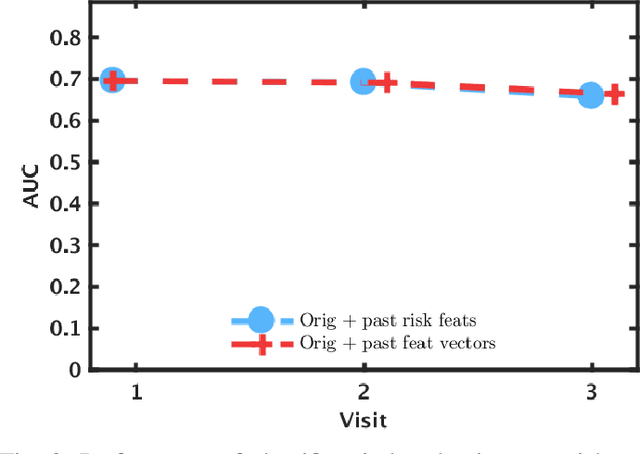
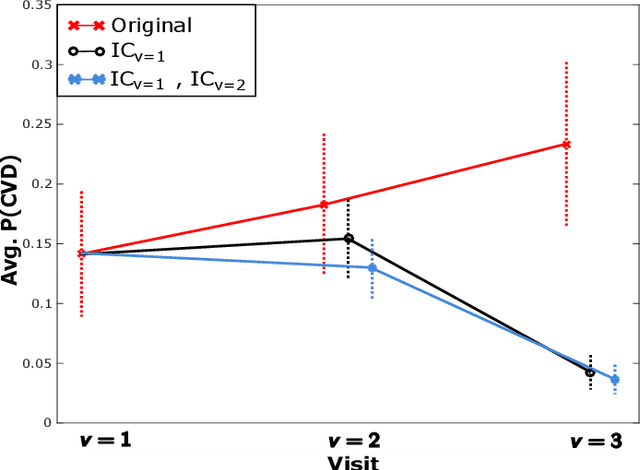
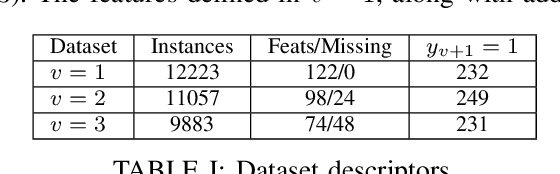
Cardiovascular disease (CVD) is a serious illness affecting millions world-wide and is the leading cause of death in the US. Recent years, however, have seen tremendous growth in the area of personalized medicine, a field of medicine that places the patient at the center of the medical decision-making and treatment process. Many CVD-focused personalized medicine innovations focus on genetic biomarkers, which provide person-specific CVD insights at the genetic level, but do not focus on the practical steps a patient could take to mitigate their risk of CVD development. In this work we propose longitudinal inverse classification, a recommendation framework that provides personalized lifestyle recommendations that minimize the predicted probability of CVD risk. Our framework takes into account historical CVD risk, as well as other patient characteristics, to provide recommendations. Our experiments show that earlier adoption of the recommendations elicited from our framework produce significant CVD risk reduction.
Optimal Sepsis Patient Treatment using Human-in-the-loop Artificial Intelligence
Sep 16, 2020
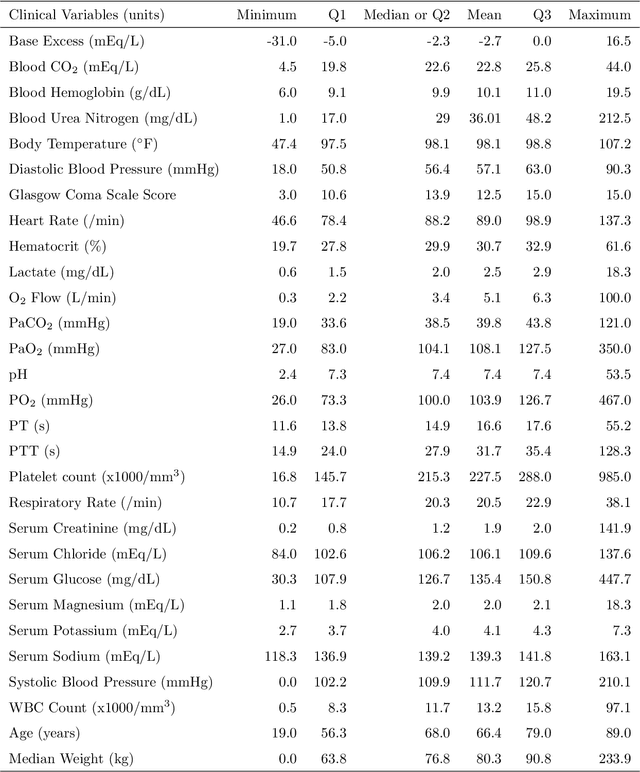
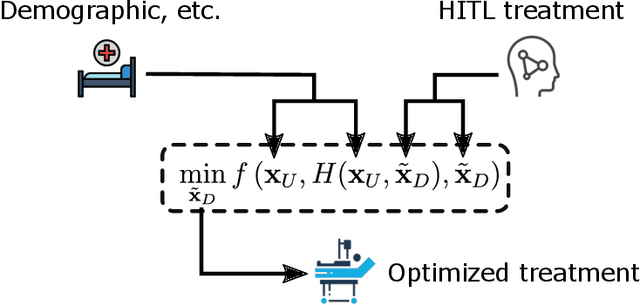
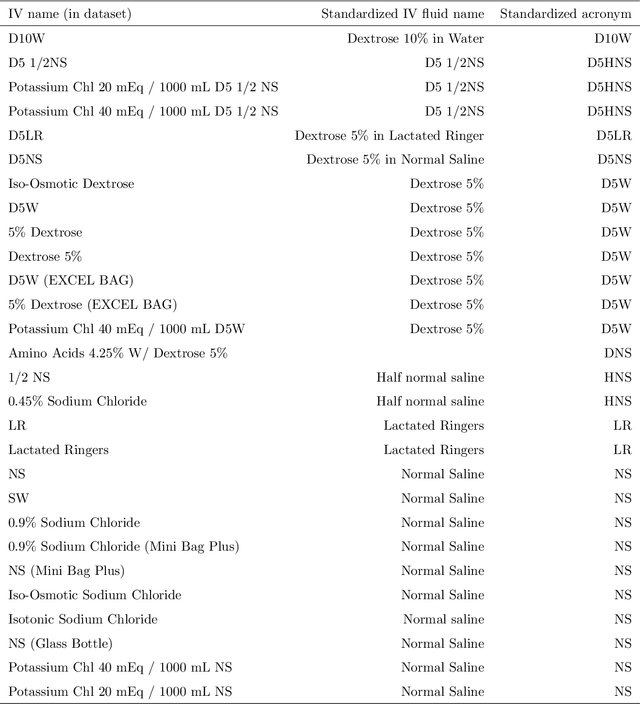
Sepsis is one of the leading causes of death in Intensive Care Units (ICU). The strategy for treating sepsis involves the infusion of intravenous (IV) fluids and administration of antibiotics. Determining the optimal quantity of IV fluids is a challenging problem due to the complexity of a patient's physiology. In this study, we develop a data-driven optimization solution that derives the optimal quantity of IV fluids for individual patients. The proposed method minimizes the probability of severe outcomes by controlling the prescribed quantity of IV fluids and utilizes human-in-the-loop artificial intelligence. We demonstrate the performance of our model on 1122 ICU patients with sepsis diagnosis extracted from the MIMIC-III dataset. The results show that, on average, our model can reduce mortality by 22%. This study has the potential to help physicians synthesize optimal, patient-specific treatment strategies.
Deriving Enhanced Geographical Representations via Similarity-based Spectral Analysis: Predicting Colorectal Cancer Survival Curves in Iowa
Sep 06, 2018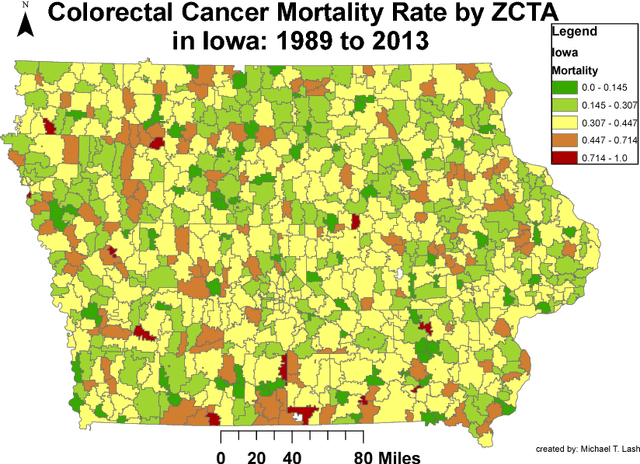

Neural networks are capable of learning rich, nonlinear feature representations shown to be beneficial in many predictive tasks. In this work, we use such models to explore different geographical feature representations in the context of predicting colorectal cancer survival curves for patients in the state of Iowa, spanning the years 1989 to 2013. Specifically, we compare model performance using "area between the curves" (ABC) to assess (a) whether survival curves can be reasonably predicted for colorectal cancer patients in the state of Iowa, (b) whether geographical features improve predictive performance, (c) whether a simple binary representation, or a richer, spectral analysis-elicited representation perform better, and (d) whether spectral analysis-based representations can be improved upon by leveraging geographically-descriptive features. In exploring (d), we devise a similarity-based spectral analysis procedure, which allows for the combination of geographically relational and geographically descriptive features. Our findings suggest that survival curves can be reasonably estimated on average, with predictive performance deviating at the five-year survival mark among all models. We also find that geographical features improve predictive performance, and that better performance is obtained using richer, spectral analysis-elicited features. Furthermore, we find that similarity-based spectral analysis-elicited representations improve upon the original spectral analysis results by approximately 40%.
Prophit: Causal inverse classification for multiple continuously valued treatment policies
Feb 14, 2018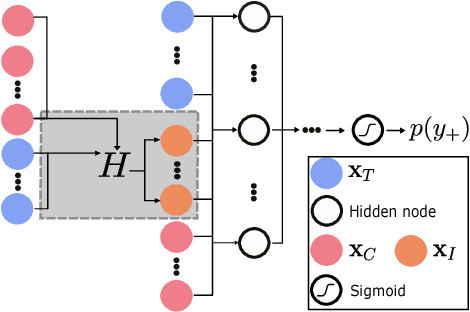
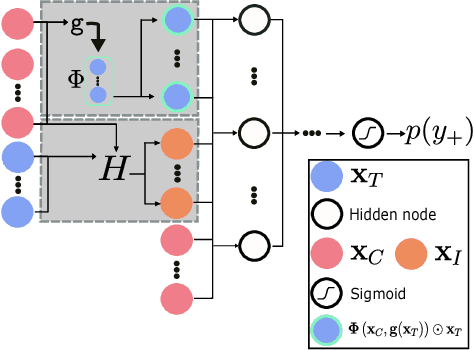
Inverse classification uses an induced classifier as a queryable oracle to guide test instances towards a preferred posterior class label. The result produced from the process is a set of instance-specific feature perturbations, or recommendations, that optimally improve the probability of the class label. In this work, we adopt a causal approach to inverse classification, eliciting treatment policies (i.e., feature perturbations) for models induced with causal properties. In so doing, we solve a long-standing problem of eliciting multiple, continuously valued treatment policies, using an updated framework and corresponding set of assumptions, which we term the inverse classification potential outcomes framework (ICPOF), along with a new measure, referred to as the individual future estimated effects ($i$FEE). We also develop the approximate propensity score (APS), based on Gaussian processes, to weight treatments, much like the inverse propensity score weighting used in past works. We demonstrate the viability of our methods on student performance.
21 Million Opportunities: A 19 Facility Investigation of Factors Affecting Hand Hygiene Compliance via Linear Predictive Models
Jan 26, 2018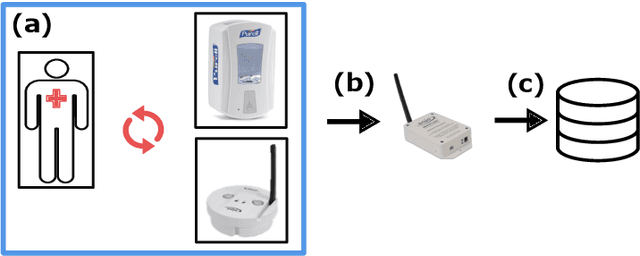
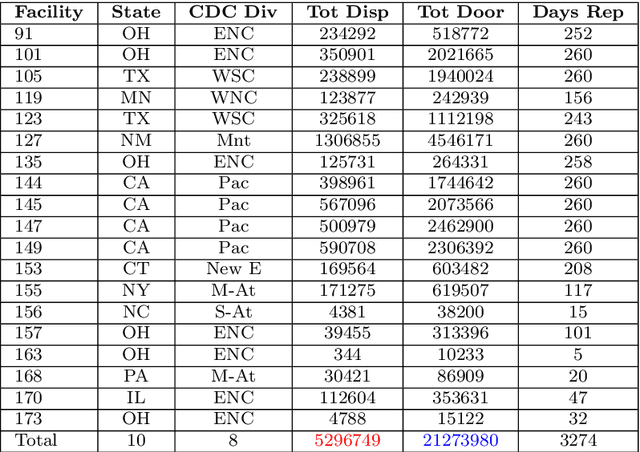

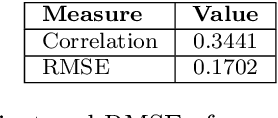
This large-scale study, consisting of 21.3 million hand hygiene opportunities from 19 distinct facilities in 10 different states, uses linear predictive models to expose factors that may affect hand hygiene compliance. We examine the use of features such as temperature, relative humidity, influenza severity, day/night shift, federal holidays and the presence of new medical residents in predicting daily hand hygiene compliance; the investigation is undertaken using both a "global" model to glean general trends, and facility-specific models to elicit facility-specific insights. The results suggest that colder temperatures and federal holidays have an adverse effect on hand hygiene compliance rates, and that individual cultures and attitudes regarding hand hygiene exist among facilities.
Learning Rich Geographical Representations: Predicting Colorectal Cancer Survival in the State of Iowa
Aug 15, 2017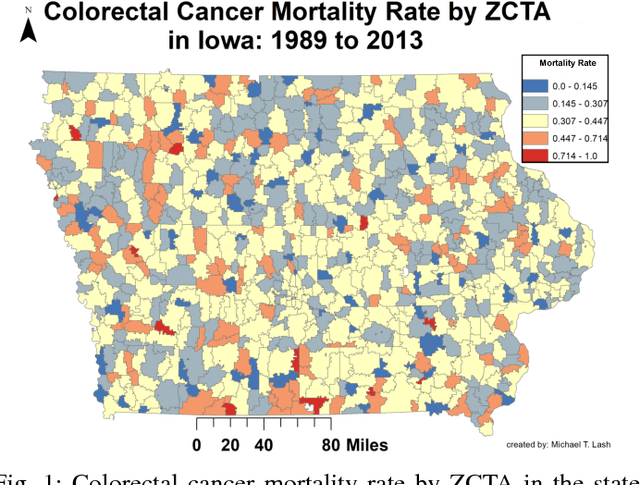
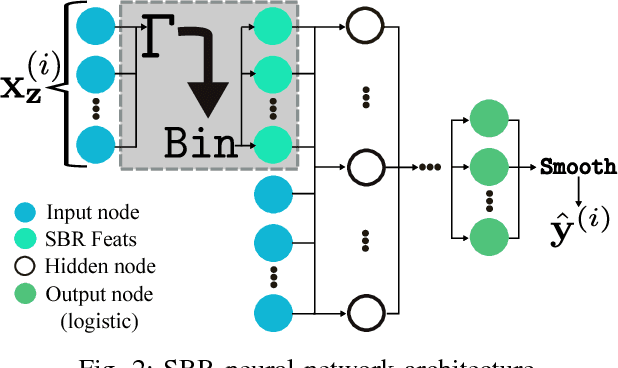
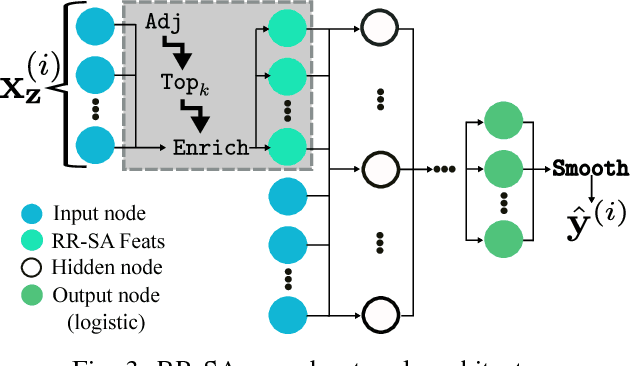
Neural networks are capable of learning rich, nonlinear feature representations shown to be beneficial in many predictive tasks. In this work, we use these models to explore the use of geographical features in predicting colorectal cancer survival curves for patients in the state of Iowa, spanning the years 1989 to 2012. Specifically, we compare model performance using a newly defined metric -- area between the curves (ABC) -- to assess (a) whether survival curves can be reasonably predicted for colorectal cancer patients in the state of Iowa, (b) whether geographical features improve predictive performance, and (c) whether a simple binary representation or richer, spectral clustering-based representation perform better. Our findings suggest that survival curves can be reasonably estimated on average, with predictive performance deviating at the five-year survival mark. We also find that geographical features improve predictive performance, and that the best performance is obtained using richer, spectral analysis-elicited features.
A Large-Scale Exploration of Factors Affecting Hand Hygiene Compliance Using Linear Predictive Models
Jul 07, 2017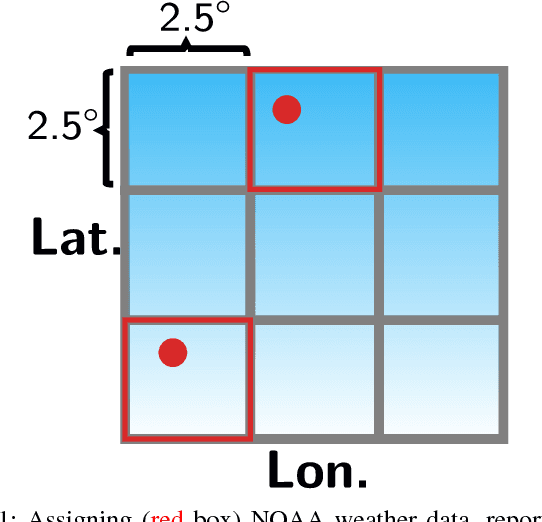
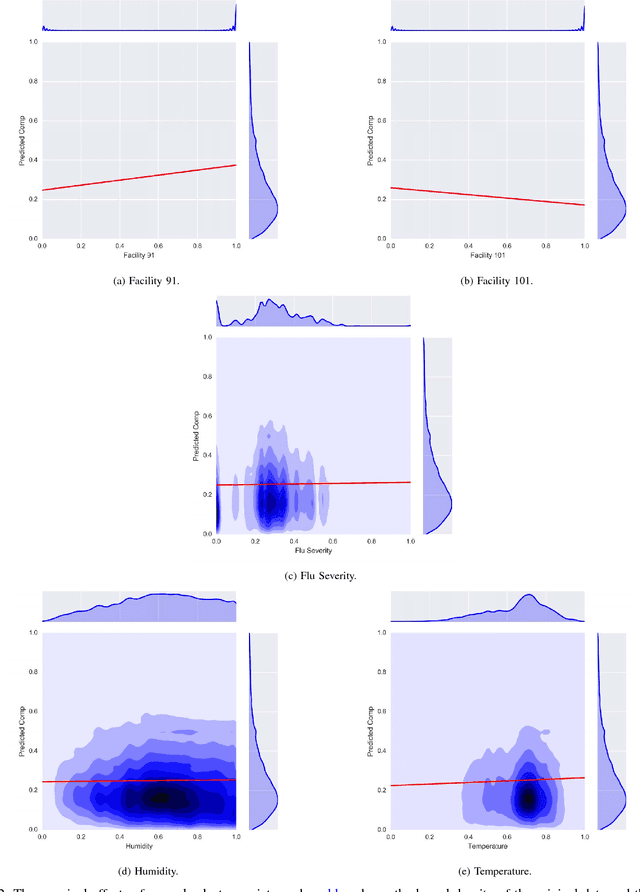
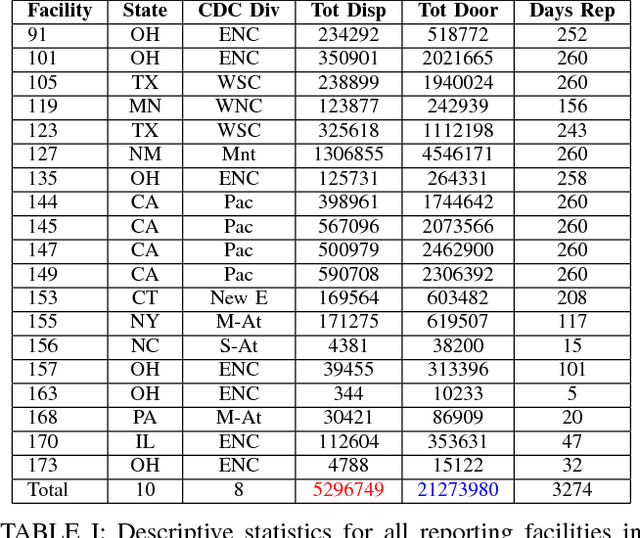

This large-scale study, consisting of 24.5 million hand hygiene opportunities spanning 19 distinct facilities in 10 different states, uses linear predictive models to expose factors that may affect hand hygiene compliance. We examine the use of features such as temperature, relative humidity, influenza severity, day/night shift, federal holidays and the presence of new residents in predicting daily hand hygiene compliance. The results suggest that colder temperatures and federal holidays have an adverse effect on hand hygiene compliance rates, and that individual cultures and attitudes regarding hand hygiene seem to exist among facilities.
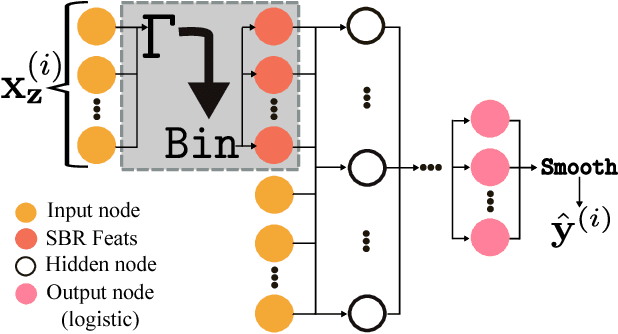
A budget-constrained inverse classification framework for smooth classifiers
Jun 08, 2017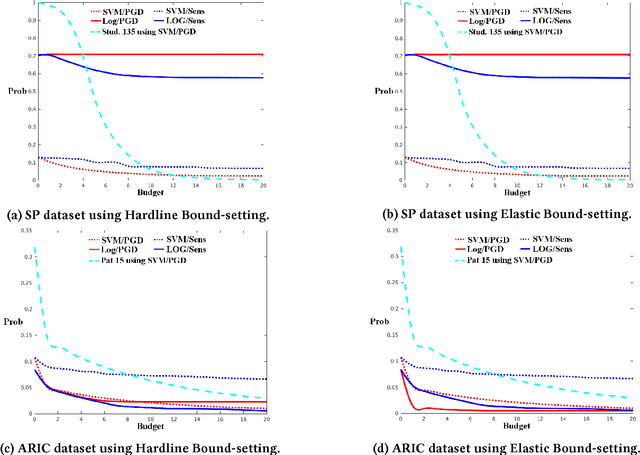

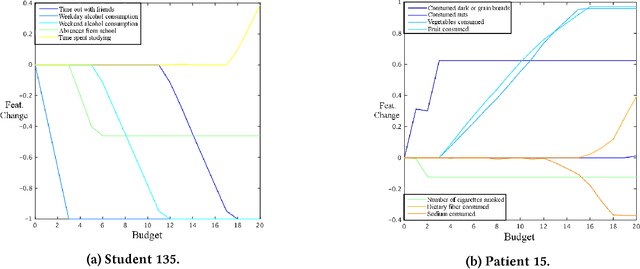
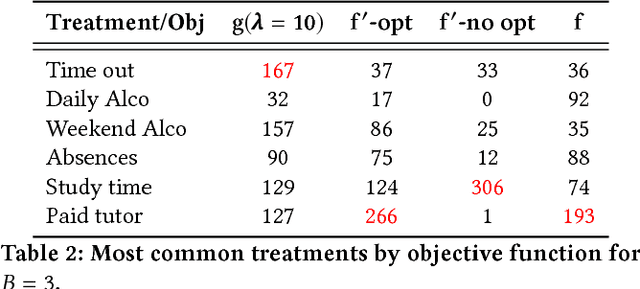
Inverse classification is the process of manipulating an instance such that it is more likely to conform to a specific class. Past methods that address such a problem have shortcomings. Greedy methods make changes that are overly radical, often relying on data that is strictly discrete. Other methods rely on certain data points, the presence of which cannot be guaranteed. In this paper we propose a general framework and method that overcomes these and other limitations. The formulation of our method can use any differentiable classification function. We demonstrate the method by using logistic regression and Gaussian kernel SVMs. We constrain the inverse classification to occur on features that can actually be changed, each of which incurs an individual cost. We further subject such changes to fall within a certain level of cumulative change (budget). Our framework can also accommodate the estimation of (indirectly changeable) features whose values change as a consequence of actions taken. Furthermore, we propose two methods for specifying feature-value ranges that result in different algorithmic behavior. We apply our method, and a proposed sensitivity analysis-based benchmark method, to two freely available datasets: Student Performance from the UCI Machine Learning Repository and a real world cardiovascular disease dataset. The results obtained demonstrate the validity and benefits of our framework and method.
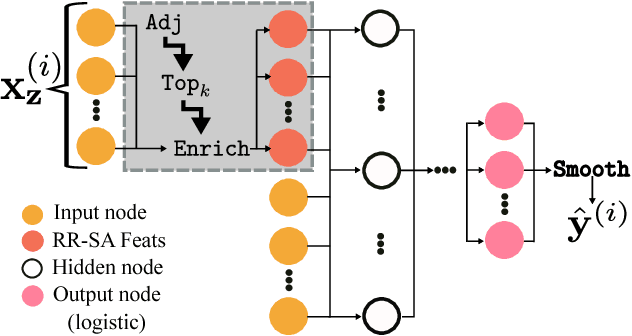
Generalized Inverse Classification
Jan 12, 2017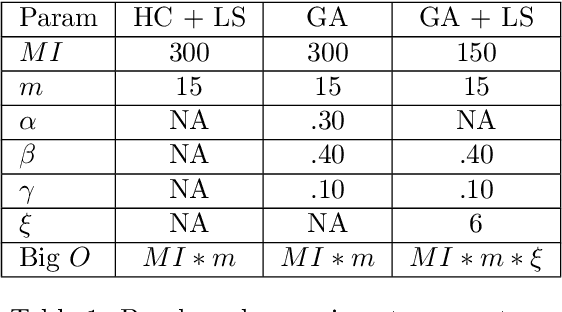
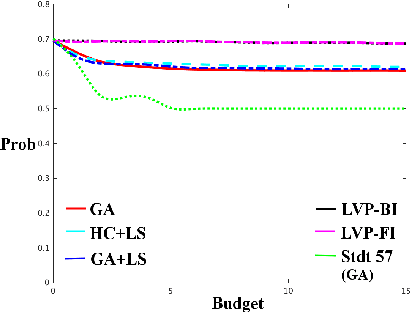
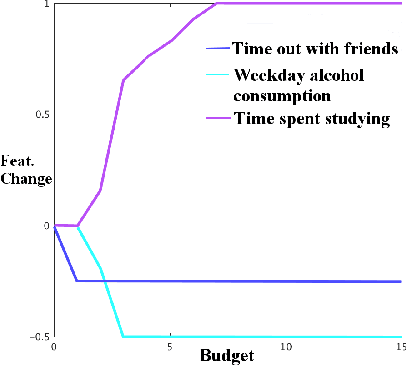
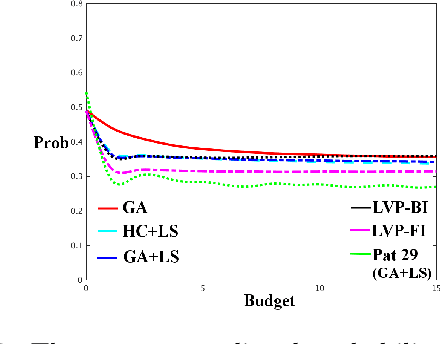
Inverse classification is the process of perturbing an instance in a meaningful way such that it is more likely to conform to a specific class. Historical methods that address such a problem are often framed to leverage only a single classifier, or specific set of classifiers. These works are often accompanied by naive assumptions. In this work we propose generalized inverse classification (GIC), which avoids restricting the classification model that can be used. We incorporate this formulation into a refined framework in which GIC takes place. Under this framework, GIC operates on features that are immediately actionable. Each change incurs an individual cost, either linear or non-linear. Such changes are subjected to occur within a specified level of cumulative change (budget). Furthermore, our framework incorporates the estimation of features that change as a consequence of direct actions taken (indirectly changeable features). To solve such a problem, we propose three real-valued heuristic-based methods and two sensitivity analysis-based comparison methods, each of which is evaluated on two freely available real-world datasets. Our results demonstrate the validity and benefits of our formulation, framework, and methods.