 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Detecting Amusing Games in Wordle
Jun 04, 2025We explore automatically predicting which Wordle games Reddit users find amusing. We scrape approximately 80k reactions by Reddit users to Wordle games from Reddit, classify the reactions as expressing amusement or not using OpenAI's GPT-3.5 using few-shot prompting, and verify that GPT-3.5's labels roughly correspond to human labels. We then extract features from Wordle games that can predict user amusement. We demonstrate that the features indeed provide a (weak) signal that predicts user amusement as predicted by GPT-3.5. Our results indicate that user amusement at Wordle games can be predicted computationally to some extent. We explore which features of the game contribute to user amusement. We find that user amusement is predictable, indicating a measurable aspect of creativity infused into Wordle games through humor.
Position Information Emerges in Causal Transformers Without Positional Encodings via Similarity of Nearby Embeddings
Dec 30, 2024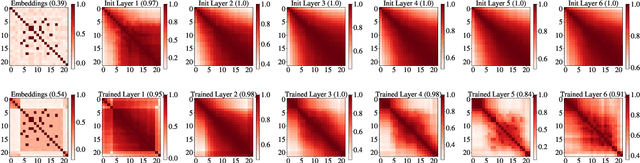
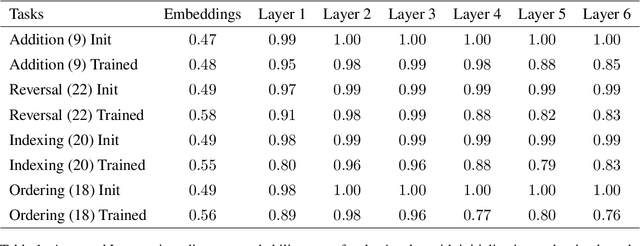

Transformers with causal attention can solve tasks that require positional information without using positional encodings. In this work, we propose and investigate a new hypothesis about how positional information can be stored without using explicit positional encoding. We observe that nearby embeddings are more similar to each other than faraway embeddings, allowing the transformer to potentially reconstruct the positions of tokens. We show that this pattern can occur in both the trained and the randomly initialized Transformer models with causal attention and no positional encodings over a common range of hyperparameters.
Barriers to Complexity-Theoretic Proofs that Achieving AGI Using Machine Learning is Intractable
Nov 10, 2024A recent paper (van Rooij et al. 2024) claims to have proved that achieving human-like intelligence using learning from data is intractable in a complexity-theoretic sense. We identify that the proof relies on an unjustified assumption about the distribution of (input, output) pairs to the system. We briefly discuss that assumption in the context of two fundamental barriers to repairing the proof: the need to precisely define ``human-like," and the need to account for the fact that a particular machine learning system will have particular inductive biases that are key to the analysis.
Occam's Razor and Bender and Koller's Octopus
Jul 28, 2024We discuss the teaching of the discussion surrounding Bender and Koller's prominent ACL 2020 paper, "Climbing toward NLU: on meaning form, and understanding in the age of data" \cite{bender2020climbing}. We present what we understand to be the main contentions of the paper, and then recommend that the students engage with the natural counter-arguments to the claims in the paper. We attach teaching materials that we use to facilitate teaching this topic to undergraduate students.
Predicting User Perception of Move Brilliance in Chess
Jun 14, 2024AI research in chess has been primarily focused on producing stronger agents that can maximize the probability of winning. However, there is another aspect to chess that has largely gone unexamined: its aesthetic appeal. Specifically, there exists a category of chess moves called ``brilliant" moves. These moves are appreciated and admired by players for their high intellectual aesthetics. We demonstrate the first system for classifying chess moves as brilliant. The system uses a neural network, using the output of a chess engine as well as features that describe the shape of the game tree. The system achieves an accuracy of 79% (with 50% base-rate), a PPV of 83%, and an NPV of 75%. We demonstrate that what humans perceive as ``brilliant" moves is not merely the best possible move. We show that a move is more likely to be predicted as brilliant, all things being equal, if a weaker engine considers it lower-quality (for the same rating by a stronger engine). Our system opens the avenues for computer chess engines to (appear to) display human-like brilliance, and, hence, creativity.
Toward Learning Latent-Variable Representations of Microstructures by Optimizing in Spatial Statistics Space
Feb 16, 2024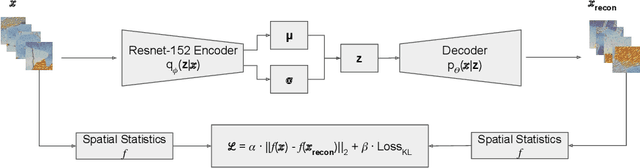


In Materials Science, material development involves evaluating and optimizing the internal structures of the material, generically referred to as microstructures. Microstructures structure is stochastic, analogously to image textures. A particular microstructure can be well characterized by its spatial statistics, analogously to image texture being characterized by the response to a Fourier-like filter bank. Material design would benefit from low-dimensional representation of microstructures Paulson et al. (2017). In this work, we train a Variational Autoencoders (VAE) to produce reconstructions of textures that preserve the spatial statistics of the original texture, while not necessarily reconstructing the same image in data space. We accomplish this by adding a differentiable term to the cost function in order to minimize the distance between the original and the reconstruction in spatial statistics space. Our experiments indicate that it is possible to train a VAE that minimizes the distance in spatial statistics space between the original and the reconstruction of synthetic images. In future work, we will apply the same techniques to microstructures, with the goal of obtaining low-dimensional representations of material microstructures.
Breaking Symmetry When Training Transformers
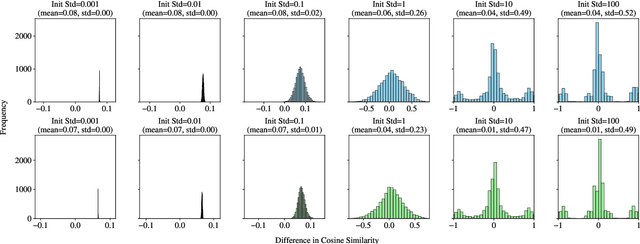
Feb 06, 2024



As we show in this paper, the prediction for output token $n+1$ of Transformer architectures without one of the mechanisms of positional encodings and causal attention is invariant to permutations of input tokens $1, 2, ..., n-1$. Usually, both mechanisms are employed and the symmetry with respect to the input tokens is broken. Recently, it has been shown that one can train Transformers without positional encodings. This must be enabled by the causal attention mechanism. In this paper, we elaborate on the argument that the causal connection mechanism must be responsible for the fact that Transformers are able to model input sequences where the order is important. Vertical "slices" of Transformers are all encouraged to represent the same location $k$ in the input sequence. We hypothesize that residual connections contribute to this phenomenon, and demonstrate evidence for this.
Toward A Reinforcement-Learning-Based System for Adjusting Medication to Minimize Speech Disfluency
Dec 12, 2023We propose a Reinforcement-Learning-based system that would automatically prescribe a hypothetical patient medications that may help the patient with their mental-health-related speech disfluency, and adjust the medication and the dosages in response to data from the patient. We demonstrate the components of the system: a module that detects and evaluates speech disfluency on a large dataset we built, and a Reinforcement Learning algorithm that automatically finds good combinations of medications. To support the two modules, we collect data on the effect of psychiatric medications for speech disfluency from the literature, and build a plausible patient simulation system. We demonstrate that the Reinforcement Learning system is, under some circumstances, able to converge to a good medication regime. We collect and label a dataset of people with possible speech disfluency and demonstrate our methods using that dataset. Our work is a proof of concept: we show that there is promise in the idea of using automatic data collection to address disfluency.
How Do ConvNets Understand Image Intensity?
Jun 01, 2023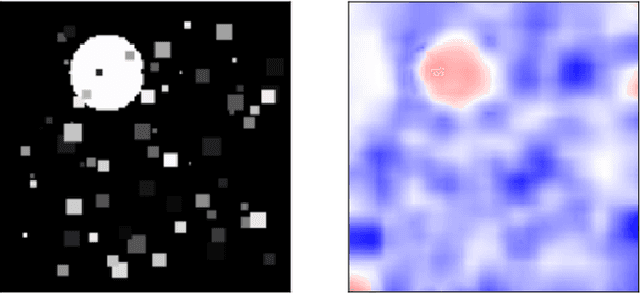



Convolutional Neural Networks (ConvNets) usually rely on edge/shape information to classify images. Visualization methods developed over the last decade confirm that ConvNets rely on edge information. We investigate situations where the ConvNet needs to rely on image intensity in addition to shape. We show that the ConvNet relies on image intensity information using visualization.
Automatic Photo Orientation Detection with Convolutional Neural Networks
May 17, 2023We apply convolutional neural networks (CNN) to the problem of image orientation detection in the context of determining the correct orientation (from 0, 90, 180, and 270 degrees) of a consumer photo. The problem is especially important for digitazing analog photographs. We substantially improve on the published state of the art in terms of the performance on one of the standard datasets, and test our system on a more difficult large dataset of consumer photos. We use Guided Backpropagation to obtain insights into how our CNN detects photo orientation, and to explain its mistakes.