 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Traffic Conditions At Metropolitan Scale Using Traffic Flow Theory
Oct 29, 2018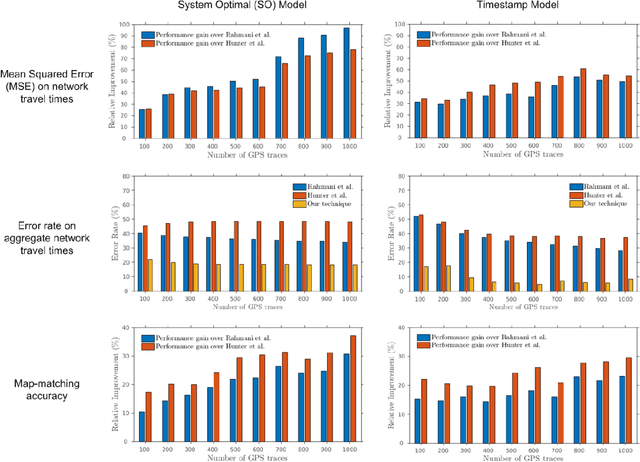
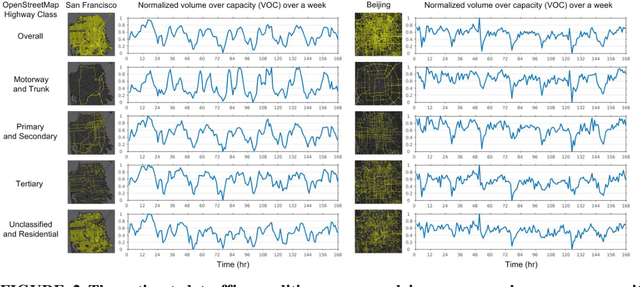

The rapid urbanization and increasing traffic have serious social, economic, and environmental impact on metropolitan areas worldwide. It is of a great importance to understand the complex interplay of road networks and traffic conditions. The authors propose a novel framework to estimate traffic conditions at the metropolitan scale using GPS traces. Their approach begins with an initial estimation of network travel times by solving a convex optimization program based on traffic flow theory. Then, they iteratively refine the estimated network travel times and vehicle traversed paths. Last, the authors perform a bilevel optimization process to estimate traffic conditions on road segments that are not covered by GPS data. The evaluation and comparison of the authors' approach over two state-of-the-art methods show up to 96.57% relative improvements. The authors have further conducted field tests by coupling road networks of San Francisco and Beijing with real-world GIS data, which involve 128,701 nodes, 148,899 road segments, and over 26 million GPS traces.
Angle-Based Joint and Individual Variation Explained
Mar 18, 2018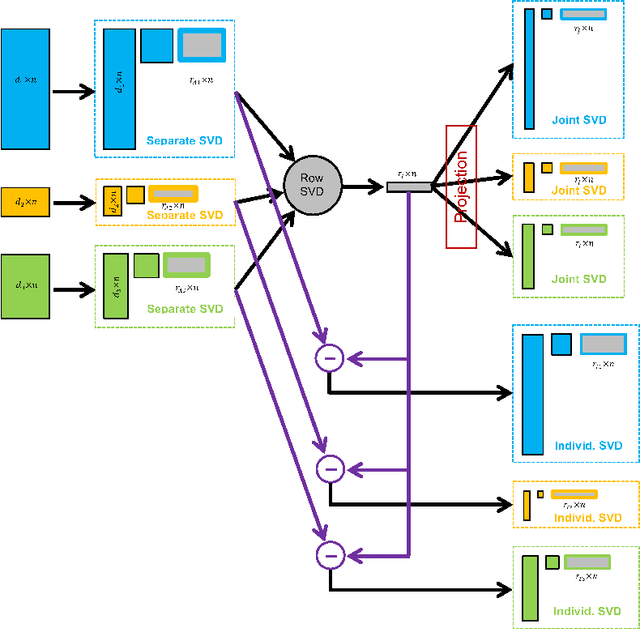
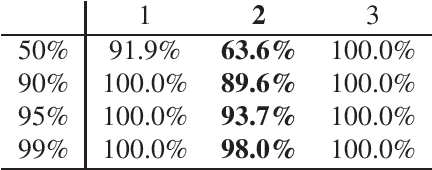
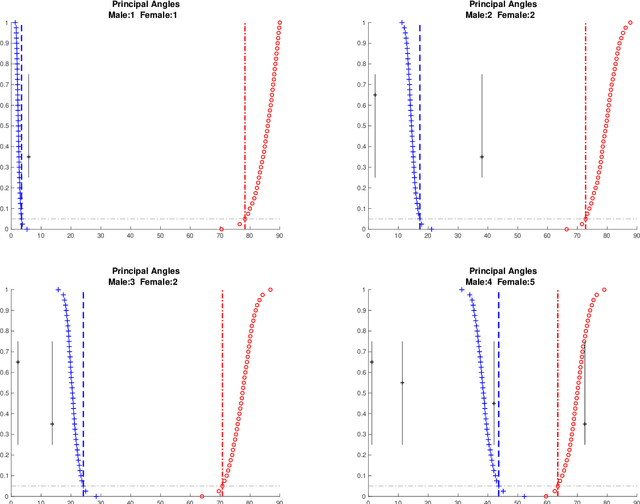
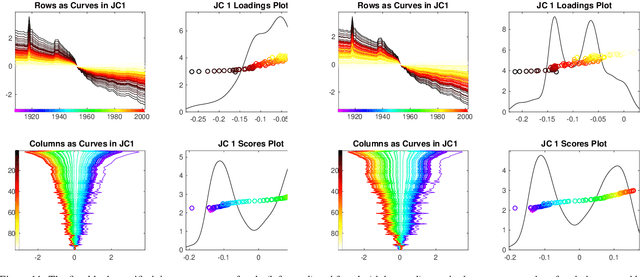
Integrative analysis of disparate data blocks measured on a common set of experimental subjects is a major challenge in modern data analysis. This data structure naturally motivates the simultaneous exploration of the joint and individual variation within each data block resulting in new insights. For instance, there is a strong desire to integrate the multiple genomic data sets in The Cancer Genome Atlas to characterize the common and also the unique aspects of cancer genetics and cell biology for each source. In this paper we introduce Angle-Based Joint and Individual Variation Explained capturing both joint and individual variation within each data block. This is a major improvement over earlier approaches to this challenge in terms of a new conceptual understanding, much better adaption to data heterogeneity and a fast linear algebra computation. Important mathematical contributions are the use of score subspaces as the principal descriptors of variation structure and the use of perturbation theory as the guide for variation segmentation. This leads to an exploratory data analysis method which is insensitive to the heterogeneity among data blocks and does not require separate normalization. An application to cancer data reveals different behaviors of each type of signal in characterizing tumor subtypes. An application to a mortality data set reveals interesting historical lessons. Software and data are available at GitHub <https://github.com/MeileiJiang/AJIVE_Project>.