 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Field Experiments with Large Language Models
Aug 19, 2024Prevailing large language models (LLMs) are capable of human responses simulation through its unprecedented content generation and reasoning abilities. However, it is not clear whether and how to leverage LLMs to simulate field experiments. In this paper, we propose and evaluate two prompting strategies: the observer mode that allows a direct prediction on main conclusions and the participant mode that simulates distributions of responses from participants. Using this approach, we examine fifteen well cited field experimental papers published in INFORMS and MISQ, finding encouraging alignments between simulated experimental results and the actual results in certain scenarios. We further identify topics of which LLMs underperform, including gender difference and social norms related research. Additionally, the automatic and standardized workflow proposed in this paper enables the possibility of a large-scale screening of more papers with field experiments. This paper pioneers the utilization of large language models (LLMs) for simulating field experiments, presenting a significant extension to previous work which focused solely on lab environments. By introducing two novel prompting strategies, observer and participant modes, we demonstrate the ability of LLMs to both predict outcomes and replicate participant responses within complex field settings. Our findings indicate a promising alignment with actual experimental results in certain scenarios, achieving a stimulation accuracy of 66% in observer mode. This study expands the scope of potential applications for LLMs and illustrates their utility in assisting researchers prior to engaging in expensive field experiments. Moreover, it sheds light on the boundaries of LLMs when used in simulating field experiments, serving as a cautionary note for researchers considering the integration of LLMs into their experimental toolkit.
Estimating Traffic Conditions At Metropolitan Scale Using Traffic Flow Theory
Oct 29, 2018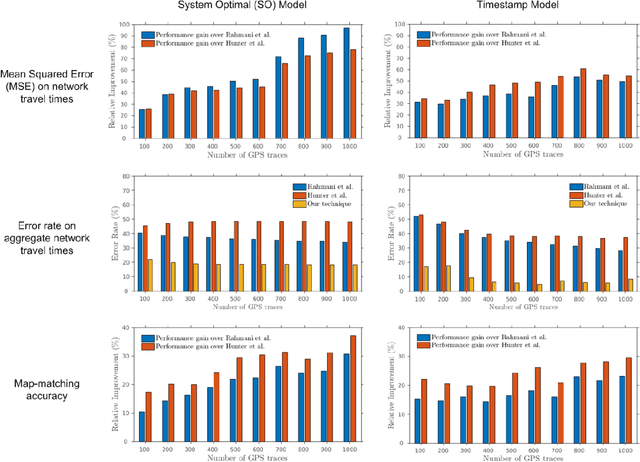
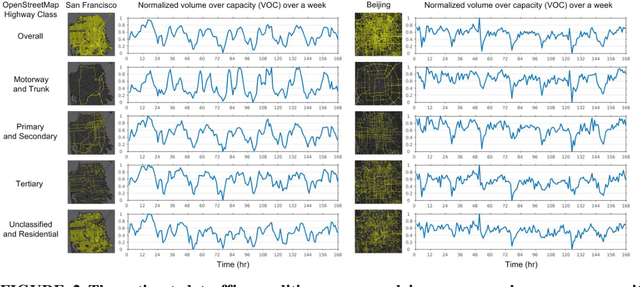

The rapid urbanization and increasing traffic have serious social, economic, and environmental impact on metropolitan areas worldwide. It is of a great importance to understand the complex interplay of road networks and traffic conditions. The authors propose a novel framework to estimate traffic conditions at the metropolitan scale using GPS traces. Their approach begins with an initial estimation of network travel times by solving a convex optimization program based on traffic flow theory. Then, they iteratively refine the estimated network travel times and vehicle traversed paths. Last, the authors perform a bilevel optimization process to estimate traffic conditions on road segments that are not covered by GPS data. The evaluation and comparison of the authors' approach over two state-of-the-art methods show up to 96.57% relative improvements. The authors have further conducted field tests by coupling road networks of San Francisco and Beijing with real-world GIS data, which involve 128,701 nodes, 148,899 road segments, and over 26 million GPS traces.