 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Instruction Fine-Tuning LLMs for Financial Text Classification
Nov 04, 2024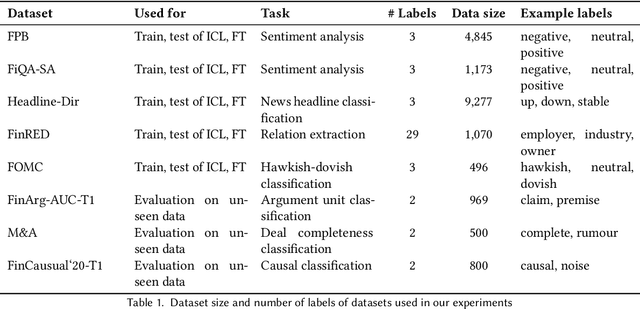
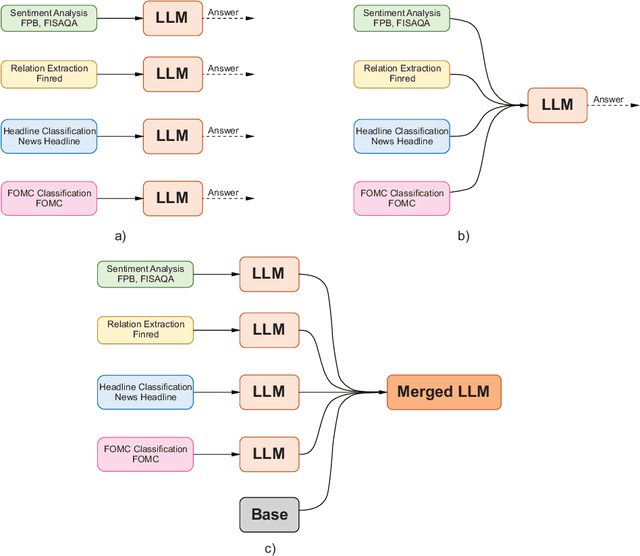
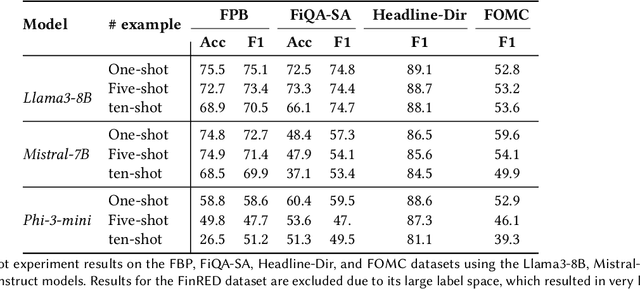
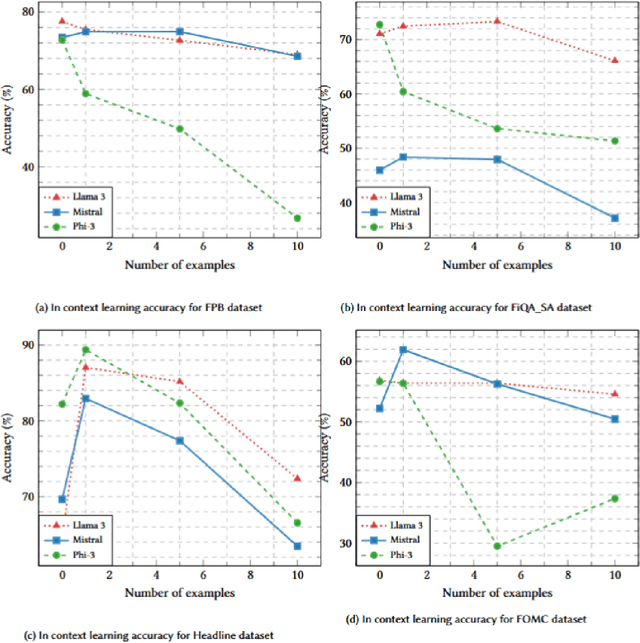
Large Language Models (LLMs) have demonstrated impressive capabilities across diverse Natural Language Processing (NLP) tasks, including language understanding, reasoning, and generation. However, general-domain LLMs often struggle with financial tasks due to the technical and specialized nature of financial texts. This study investigates the efficacy of instruction fine-tuning smaller-scale LLMs, including Mistral-7B, Llama3-8B, and Phi3-mini, to enhance their performance in financial text classification tasks. We fine-tuned both instruction-tuned and base models across four financial classification tasks, achieving significant improvements in task-specific performance. Furthermore, we evaluated the zero-shot capabilities of these fine-tuned models on three unseen complex financial tasks, including argument classification, deal completeness classification, and causal classification. Our results indicate while base model fine-tuning led to greater degradation, instruction-tuned models maintained more robust performance. To address this degradation, we employed model merging techniques, integrating single-task domain-specific fine-tuned models with the base model. Using this merging method resulted in significant enhancements in zero-shot performance, even exceeding the original model's accuracy on certain datasets. Our findings underscore the effectiveness of instruction fine-tuning and model merging for adapting LLMs to specialized financial text classification tasks.
Enhancing Financial Question Answering with a Multi-Agent Reflection Framework
Oct 29, 2024



While Large Language Models (LLMs) have shown impressive capabilities in numerous Natural Language Processing (NLP) tasks, they still struggle with financial question answering (QA), particularly when numerical reasoning is required. Recently, LLM-based multi-agent frameworks have demonstrated remarkable effectiveness in multi-step reasoning, which is crucial for financial QA tasks as it involves extracting relevant information from tables and text and then performing numerical reasoning on the extracted data to infer answers. In this study, we propose a multi-agent framework incorporating a critic agent that reflects on the reasoning steps and final answers for each question. Additionally, we enhance our system by adding multiple critic agents, each focusing on a specific aspect of the answer. Our results indicate that this framework significantly improves performance compared to single-agent reasoning, with an average performance increase of 15% for the LLaMA3-8B model and 5% for the LLaMA3-70B model. Furthermore, our framework performs on par with, and in some cases surpasses, larger single-agent LLMs such as LLaMA3.1-405B and GPT-4o-mini, though it falls slightly short compared to Claude-3.5 Sonnet. Overall, our framework presents an effective solution to enhance open-source LLMs for financial QA tasks, offering a cost-effective alternative to larger models like Claude-3.5 Sonnet.
Simulating Field Experiments with Large Language Models
Aug 19, 2024Prevailing large language models (LLMs) are capable of human responses simulation through its unprecedented content generation and reasoning abilities. However, it is not clear whether and how to leverage LLMs to simulate field experiments. In this paper, we propose and evaluate two prompting strategies: the observer mode that allows a direct prediction on main conclusions and the participant mode that simulates distributions of responses from participants. Using this approach, we examine fifteen well cited field experimental papers published in INFORMS and MISQ, finding encouraging alignments between simulated experimental results and the actual results in certain scenarios. We further identify topics of which LLMs underperform, including gender difference and social norms related research. Additionally, the automatic and standardized workflow proposed in this paper enables the possibility of a large-scale screening of more papers with field experiments. This paper pioneers the utilization of large language models (LLMs) for simulating field experiments, presenting a significant extension to previous work which focused solely on lab environments. By introducing two novel prompting strategies, observer and participant modes, we demonstrate the ability of LLMs to both predict outcomes and replicate participant responses within complex field settings. Our findings indicate a promising alignment with actual experimental results in certain scenarios, achieving a stimulation accuracy of 66% in observer mode. This study expands the scope of potential applications for LLMs and illustrates their utility in assisting researchers prior to engaging in expensive field experiments. Moreover, it sheds light on the boundaries of LLMs when used in simulating field experiments, serving as a cautionary note for researchers considering the integration of LLMs into their experimental toolkit.
A Comparative Analysis of Fine-Tuned LLMs and Few-Shot Learning of LLMs for Financial Sentiment Analysis
Dec 14, 2023



Financial sentiment analysis plays a crucial role in uncovering latent patterns and detecting emerging trends, enabling individuals to make well-informed decisions that may yield substantial advantages within the constantly changing realm of finance. Recently, Large Language Models (LLMs) have demonstrated their effectiveness in diverse domains, showcasing remarkable capabilities even in zero-shot and few-shot in-context learning for various Natural Language Processing (NLP) tasks. Nevertheless, their potential and applicability in the context of financial sentiment analysis have not been thoroughly explored yet. To bridge this gap, we employ two approaches: in-context learning (with a focus on gpt-3.5-turbo model) and fine-tuning LLMs on a finance-domain dataset. Given the computational costs associated with fine-tuning LLMs with large parameter sizes, our focus lies on smaller LLMs, spanning from 250M to 3B parameters for fine-tuning. We then compare the performances with state-of-the-art results to evaluate their effectiveness in the finance-domain. Our results demonstrate that fine-tuned smaller LLMs can achieve comparable performance to state-of-the-art fine-tuned LLMs, even with models having fewer parameters and a smaller training dataset. Additionally, the zero-shot and one-shot performance of LLMs produces comparable results with fine-tuned smaller LLMs and state-of-the-art outcomes. Furthermore, our analysis demonstrates that there is no observed enhancement in performance for finance-domain sentiment analysis when the number of shots for in-context learning is increased.
ET-LDA: Joint Topic Modeling for Aligning Events and their Twitter Feedback
Dec 21, 2012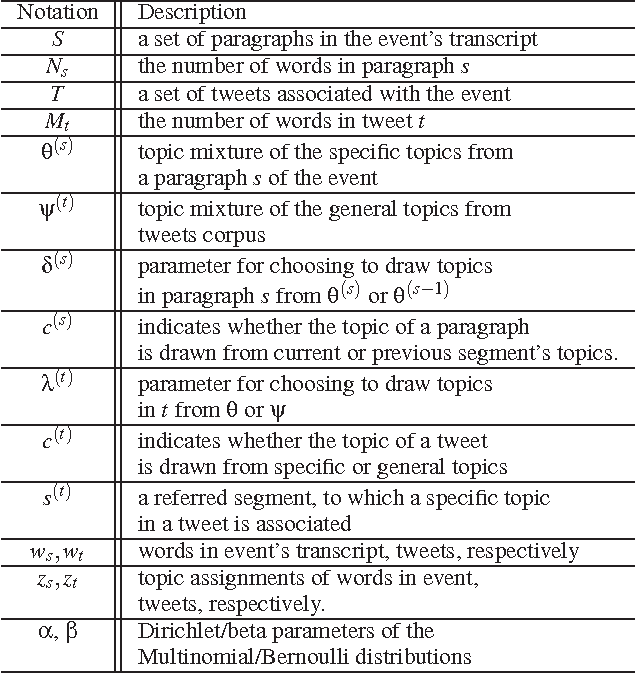
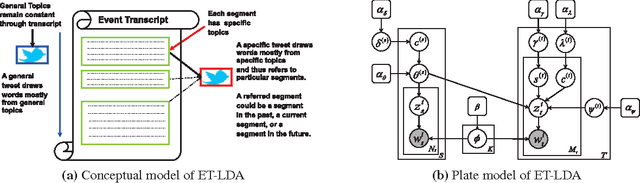
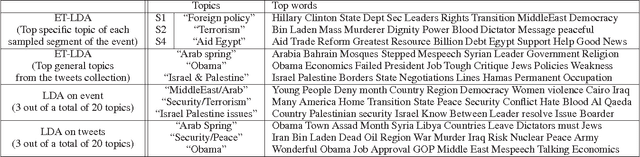

During broadcast events such as the Superbowl, the U.S. Presidential and Primary debates, etc., Twitter has become the de facto platform for crowds to share perspectives and commentaries about them. Given an event and an associated large-scale collection of tweets, there are two fundamental research problems that have been receiving increasing attention in recent years. One is to extract the topics covered by the event and the tweets; the other is to segment the event. So far these problems have been viewed separately and studied in isolation. In this work, we argue that these problems are in fact inter-dependent and should be addressed together. We develop a joint Bayesian model that performs topic modeling and event segmentation in one unified framework. We evaluate the proposed model both quantitatively and qualitatively on two large-scale tweet datasets associated with two events from different domains to show that it improves significantly over baseline models.
ET-LDA: Joint Topic Modeling For Aligning, Analyzing and Sensemaking of Public Events and Their Twitter Feeds
Dec 21, 2012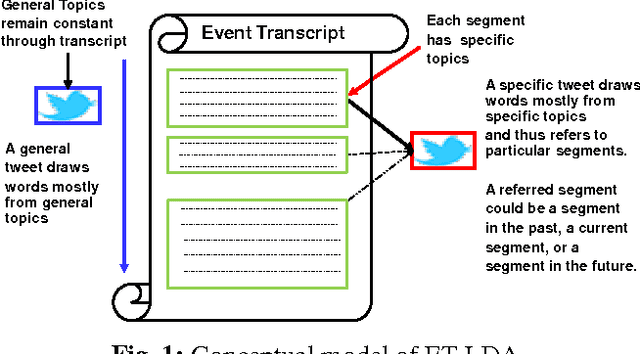
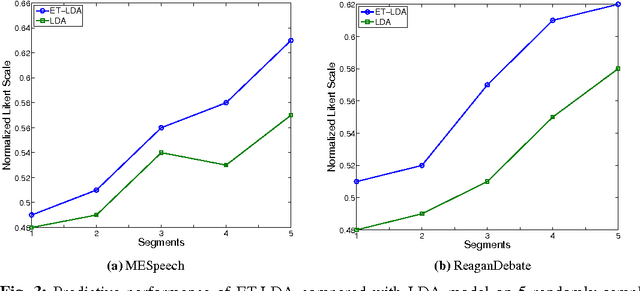
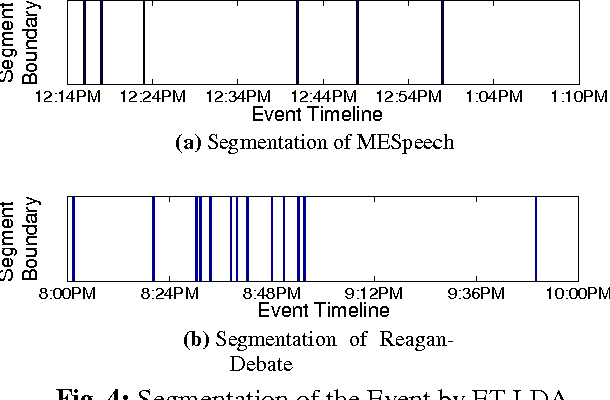
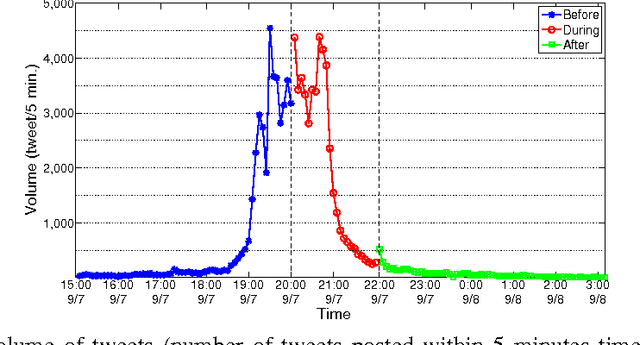
Social media channels such as Twitter have emerged as popular platforms for crowds to respond to public events such as speeches, sports and debates. While this promises tremendous opportunities to understand and make sense of the reception of an event from the social media, the promises come entwined with significant technical challenges. In particular, given an event and an associated large scale collection of tweets, we need approaches to effectively align tweets and the parts of the event they refer to. This in turn raises questions about how to segment the event into smaller yet meaningful parts, and how to figure out whether a tweet is a general one about the entire event or specific one aimed at a particular segment of the event. In this work, we present ET-LDA, an effective method for aligning an event and its tweets through joint statistical modeling of topical influences from the events and their associated tweets. The model enables the automatic segmentation of the events and the characterization of tweets into two categories: (1) episodic tweets that respond specifically to the content in the segments of the events, and (2) steady tweets that respond generally about the events. We present an efficient inference method for this model, and a comprehensive evaluation of its effectiveness over existing methods. In particular, through a user study, we demonstrate that users find the topics, the segments, the alignment, and the episodic tweets discovered by ET-LDA to be of higher quality and more interesting as compared to the state-of-the-art, with improvements in the range of 18-41%.