 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Instruction Fine-Tuning LLMs for Financial Text Classification
Nov 04, 2024
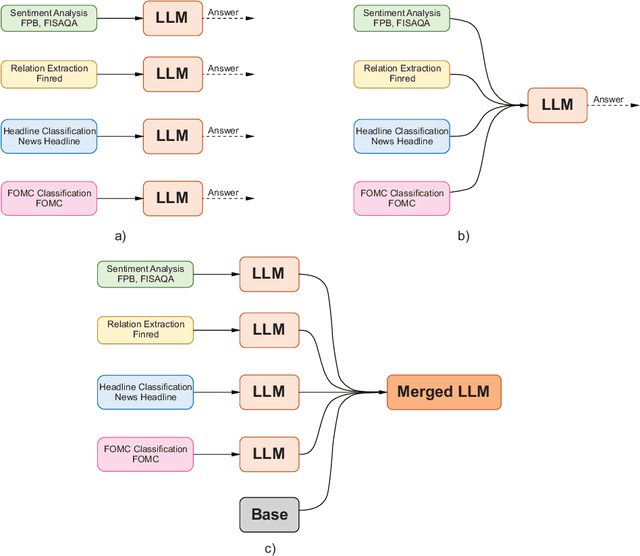
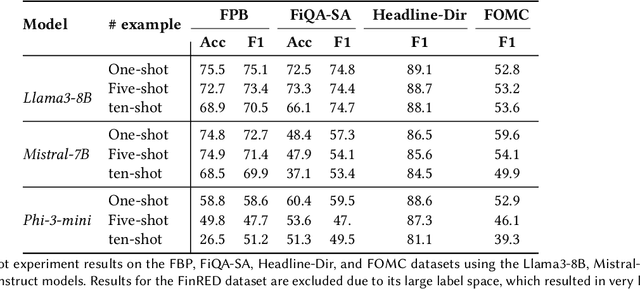
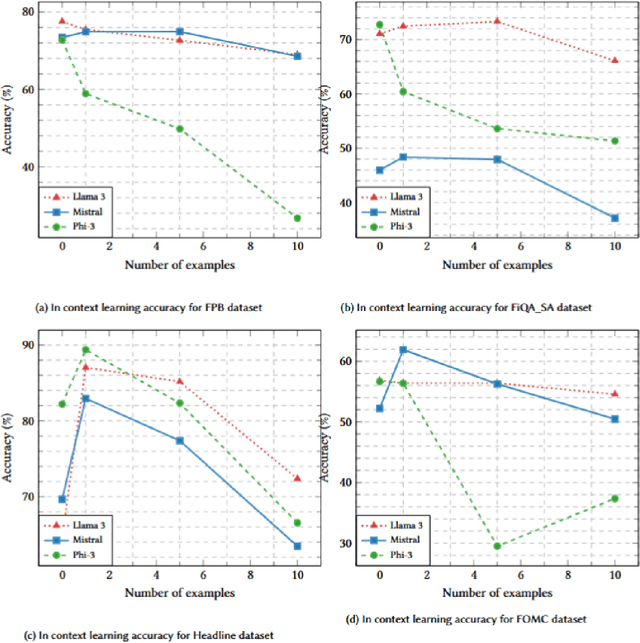
Large Language Models (LLMs) have demonstrated impressive capabilities across diverse Natural Language Processing (NLP) tasks, including language understanding, reasoning, and generation. However, general-domain LLMs often struggle with financial tasks due to the technical and specialized nature of financial texts. This study investigates the efficacy of instruction fine-tuning smaller-scale LLMs, including Mistral-7B, Llama3-8B, and Phi3-mini, to enhance their performance in financial text classification tasks. We fine-tuned both instruction-tuned and base models across four financial classification tasks, achieving significant improvements in task-specific performance. Furthermore, we evaluated the zero-shot capabilities of these fine-tuned models on three unseen complex financial tasks, including argument classification, deal completeness classification, and causal classification. Our results indicate while base model fine-tuning led to greater degradation, instruction-tuned models maintained more robust performance. To address this degradation, we employed model merging techniques, integrating single-task domain-specific fine-tuned models with the base model. Using this merging method resulted in significant enhancements in zero-shot performance, even exceeding the original model's accuracy on certain datasets. Our findings underscore the effectiveness of instruction fine-tuning and model merging for adapting LLMs to specialized financial text classification tasks.
Enhancing Financial Question Answering with a Multi-Agent Reflection Framework
Oct 29, 2024



While Large Language Models (LLMs) have shown impressive capabilities in numerous Natural Language Processing (NLP) tasks, they still struggle with financial question answering (QA), particularly when numerical reasoning is required. Recently, LLM-based multi-agent frameworks have demonstrated remarkable effectiveness in multi-step reasoning, which is crucial for financial QA tasks as it involves extracting relevant information from tables and text and then performing numerical reasoning on the extracted data to infer answers. In this study, we propose a multi-agent framework incorporating a critic agent that reflects on the reasoning steps and final answers for each question. Additionally, we enhance our system by adding multiple critic agents, each focusing on a specific aspect of the answer. Our results indicate that this framework significantly improves performance compared to single-agent reasoning, with an average performance increase of 15% for the LLaMA3-8B model and 5% for the LLaMA3-70B model. Furthermore, our framework performs on par with, and in some cases surpasses, larger single-agent LLMs such as LLaMA3.1-405B and GPT-4o-mini, though it falls slightly short compared to Claude-3.5 Sonnet. Overall, our framework presents an effective solution to enhance open-source LLMs for financial QA tasks, offering a cost-effective alternative to larger models like Claude-3.5 Sonnet.
A Comparative Analysis of Fine-Tuned LLMs and Few-Shot Learning of LLMs for Financial Sentiment Analysis
Dec 14, 2023



Financial sentiment analysis plays a crucial role in uncovering latent patterns and detecting emerging trends, enabling individuals to make well-informed decisions that may yield substantial advantages within the constantly changing realm of finance. Recently, Large Language Models (LLMs) have demonstrated their effectiveness in diverse domains, showcasing remarkable capabilities even in zero-shot and few-shot in-context learning for various Natural Language Processing (NLP) tasks. Nevertheless, their potential and applicability in the context of financial sentiment analysis have not been thoroughly explored yet. To bridge this gap, we employ two approaches: in-context learning (with a focus on gpt-3.5-turbo model) and fine-tuning LLMs on a finance-domain dataset. Given the computational costs associated with fine-tuning LLMs with large parameter sizes, our focus lies on smaller LLMs, spanning from 250M to 3B parameters for fine-tuning. We then compare the performances with state-of-the-art results to evaluate their effectiveness in the finance-domain. Our results demonstrate that fine-tuned smaller LLMs can achieve comparable performance to state-of-the-art fine-tuned LLMs, even with models having fewer parameters and a smaller training dataset. Additionally, the zero-shot and one-shot performance of LLMs produces comparable results with fine-tuned smaller LLMs and state-of-the-art outcomes. Furthermore, our analysis demonstrates that there is no observed enhancement in performance for finance-domain sentiment analysis when the number of shots for in-context learning is increased.