 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility-Optimized Synthesis of Differentially Private Location Traces
Sep 14, 2020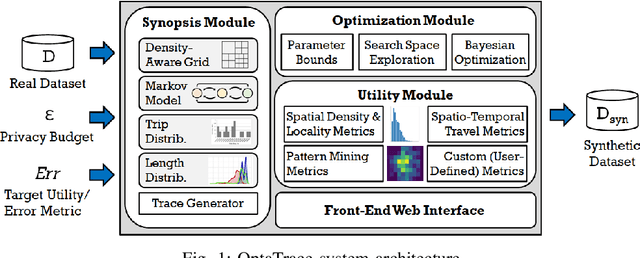
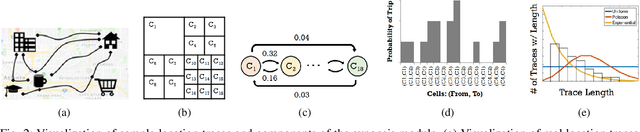
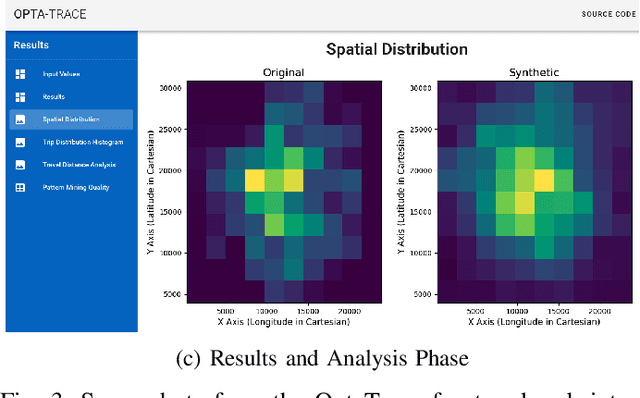
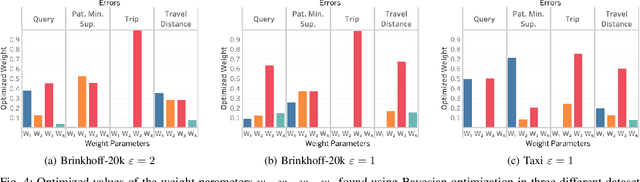
Differentially private location trace synthesis (DPLTS) has recently emerged as a solution to protect mobile users' privacy while enabling the analysis and sharing of their location traces. A key challenge in DPLTS is to best preserve the utility in location trace datasets, which is non-trivial considering the high dimensionality, complexity and heterogeneity of datasets, as well as the diverse types and notions of utility. In this paper, we present OptaTrace: a utility-optimized and targeted approach to DPLTS. Given a real trace dataset D, the differential privacy parameter epsilon controlling the strength of privacy protection, and the utility/error metric Err of interest; OptaTrace uses Bayesian optimization to optimize DPLTS such that the output error (measured in terms of given metric Err) is minimized while epsilon-differential privacy is satisfied. In addition, OptaTrace introduces a utility module that contains several built-in error metrics for utility benchmarking and for choosing Err, as well as a front-end web interface for accessible and interactive DPLTS service. Experiments show that OptaTrace's optimized output can yield substantial utility improvement and error reduction compared to previous work.
Data Poisoning Attacks Against Federated Learning Systems
Aug 11, 2020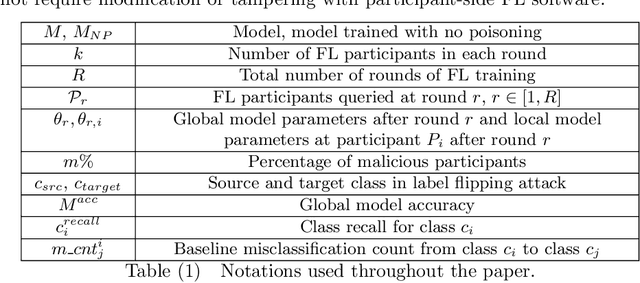

Federated learning (FL) is an emerging paradigm for distributed training of large-scale deep neural networks in which participants' data remains on their own devices with only model updates being shared with a central server. However, the distributed nature of FL gives rise to new threats caused by potentially malicious participants. In this paper, we study targeted data poisoning attacks against FL systems in which a malicious subset of the participants aim to poison the global model by sending model updates derived from mislabeled data. We first demonstrate that such data poisoning attacks can cause substantial drops in classification accuracy and recall, even with a small percentage of malicious participants. We additionally show that the attacks can be targeted, i.e., they have a large negative impact only on classes that are under attack. We also study attack longevity in early/late round training, the impact of malicious participant availability, and the relationships between the two. Finally, we propose a defense strategy that can help identify malicious participants in FL to circumvent poisoning attacks, and demonstrate its effectiveness.
Understanding Object Detection Through An Adversarial Lens
Jul 11, 2020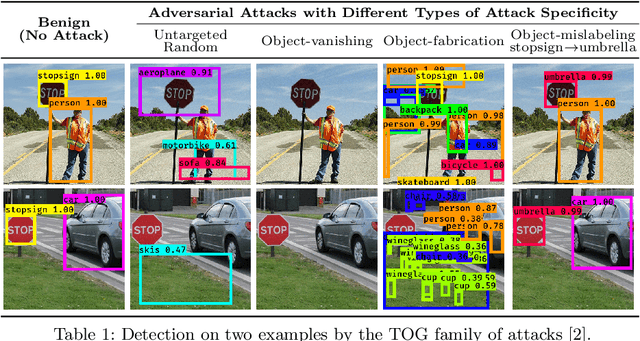
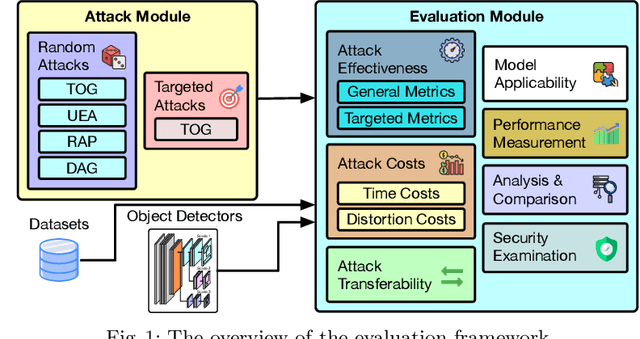

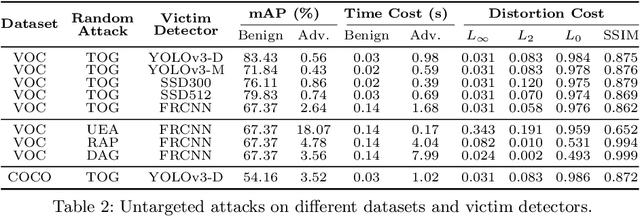
Deep neural networks based object detection models have revolutionized computer vision and fueled the development of a wide range of visual recognition applications. However, recent studies have revealed that deep object detectors can be compromised under adversarial attacks, causing a victim detector to detect no object, fake objects, or mislabeled objects. With object detection being used pervasively in many security-critical applications, such as autonomous vehicles and smart cities, we argue that a holistic approach for an in-depth understanding of adversarial attacks and vulnerabilities of deep object detection systems is of utmost importance for the research community to develop robust defense mechanisms. This paper presents a framework for analyzing and evaluating vulnerabilities of the state-of-the-art object detectors under an adversarial lens, aiming to analyze and demystify the attack strategies, adverse effects, and costs, as well as the cross-model and cross-resolution transferability of attacks. Using a set of quantitative metrics, extensive experiments are performed on six representative deep object detectors from three popular families (YOLOv3, SSD, and Faster R-CNN) with two benchmark datasets (PASCAL VOC and MS COCO). We demonstrate that the proposed framework can serve as a methodical benchmark for analyzing adversarial behaviors and risks in real-time object detection systems. We conjecture that this framework can also serve as a tool to assess the security risks and the adversarial robustness of deep object detectors to be deployed in real-world applications.
LDP-Fed: Federated Learning with Local Differential Privacy
Jun 05, 2020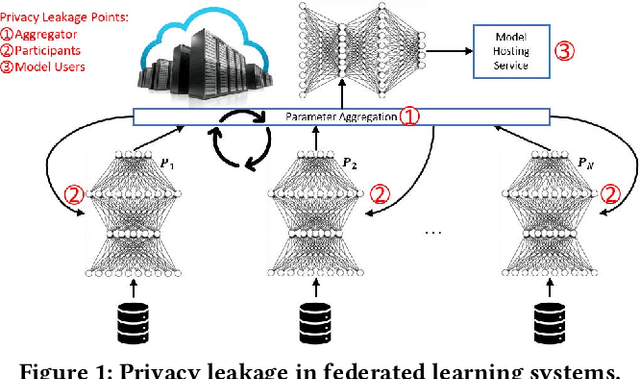
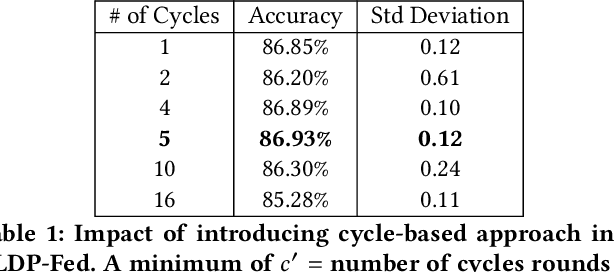
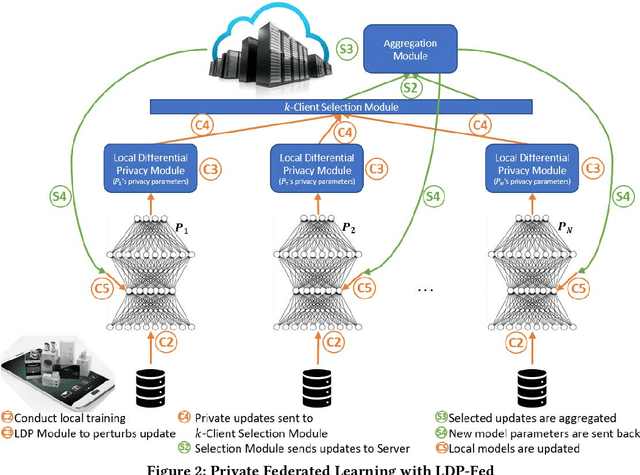

This paper presents LDP-Fed, a novel federated learning system with a formal privacy guarantee using local differential privacy (LDP). Existing LDP protocols are developed primarily to ensure data privacy in the collection of single numerical or categorical values, such as click count in Web access logs. However, in federated learning model parameter updates are collected iteratively from each participant and consist of high dimensional, continuous values with high precision (10s of digits after the decimal point), making existing LDP protocols inapplicable. To address this challenge in LDP-Fed, we design and develop two novel approaches. First, LDP-Fed's LDP Module provides a formal differential privacy guarantee for the repeated collection of model training parameters in the federated training of large-scale neural networks over multiple individual participants' private datasets. Second, LDP-Fed implements a suite of selection and filtering techniques for perturbing and sharing select parameter updates with the parameter server. We validate our system deployed with a condensed LDP protocol in training deep neural networks on public data. We compare this version of LDP-Fed, coined CLDP-Fed, with other state-of-the-art approaches with respect to model accuracy, privacy preservation, and system capabilities.
A Framework for Evaluating Gradient Leakage Attacks in Federated Learning
Apr 23, 2020
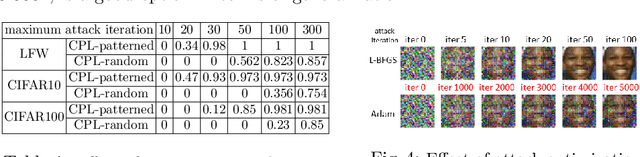

Federated learning (FL) is an emerging distributed machine learning framework for collaborative model training with a network of clients (edge devices). FL offers default client privacy by allowing clients to keep their sensitive data on local devices and to only share local training parameter updates with the federated server. However, recent studies have shown that even sharing local parameter updates from a client to the federated server may be susceptible to gradient leakage attacks and intrude the client privacy regarding its training data. In this paper, we present a principled framework for evaluating and comparing different forms of client privacy leakage attacks. We first provide formal and experimental analysis to show how adversaries can reconstruct the private local training data by simply analyzing the shared parameter update from local training (e.g., local gradient or weight update vector). We then analyze how different hyperparameter configurations in federated learning and different settings of the attack algorithm may impact on both attack effectiveness and attack cost. Our framework also measures, evaluates, and analyzes the effectiveness of client privacy leakage attacks under different gradient compression ratios when using communication efficient FL protocols. Our experiments also include some preliminary mitigation strategies to highlight the importance of providing a systematic attack evaluation framework towards an in-depth understanding of the various forms of client privacy leakage threats in federated learning and developing theoretical foundations for attack mitigation.
TOG: Targeted Adversarial Objectness Gradient Attacks on Real-time Object Detection Systems
Apr 09, 2020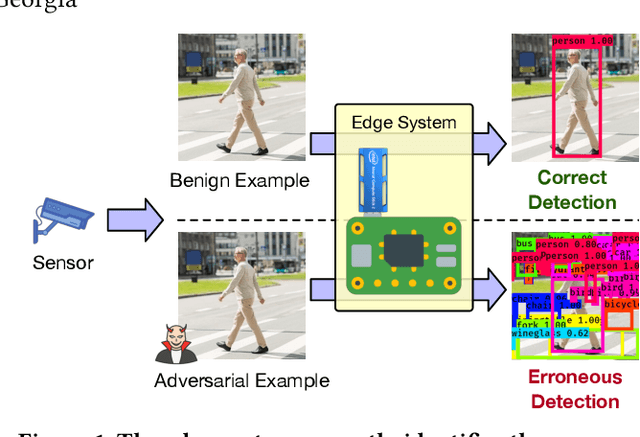
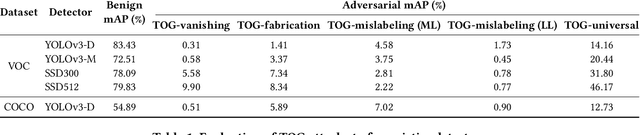
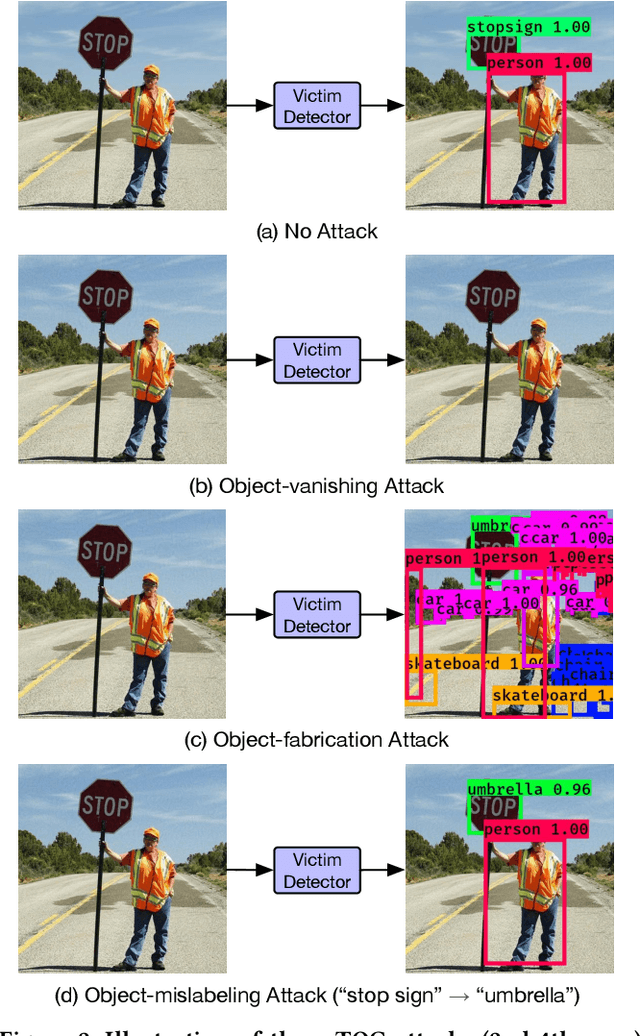

The rapid growth of real-time huge data capturing has pushed the deep learning and data analytic computing to the edge systems. Real-time object recognition on the edge is one of the representative deep neural network (DNN) powered edge systems for real-world mission-critical applications, such as autonomous driving and augmented reality. While DNN powered object detection edge systems celebrate many life-enriching opportunities, they also open doors for misuse and abuse. This paper presents three Targeted adversarial Objectness Gradient attacks, coined as TOG, which can cause the state-of-the-art deep object detection networks to suffer from object-vanishing, object-fabrication, and object-mislabeling attacks. We also present a universal objectness gradient attack to use adversarial transferability for black-box attacks, which is effective on any inputs with negligible attack time cost, low human perceptibility, and particularly detrimental to object detection edge systems. We report our experimental measurements using two benchmark datasets (PASCAL VOC and MS COCO) on two state-of-the-art detection algorithms (YOLO and SSD). The results demonstrate serious adversarial vulnerabilities and the compelling need for developing robust object detection systems.
Effects of Differential Privacy and Data Skewness on Membership Inference Vulnerability
Nov 21, 2019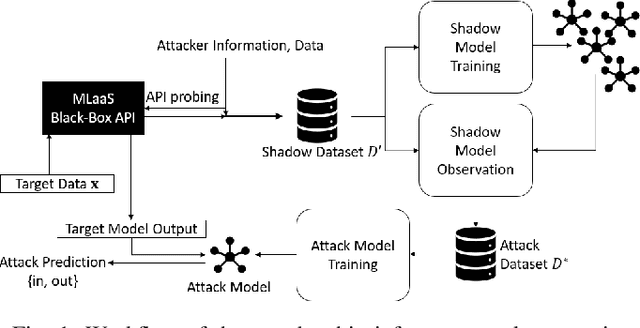
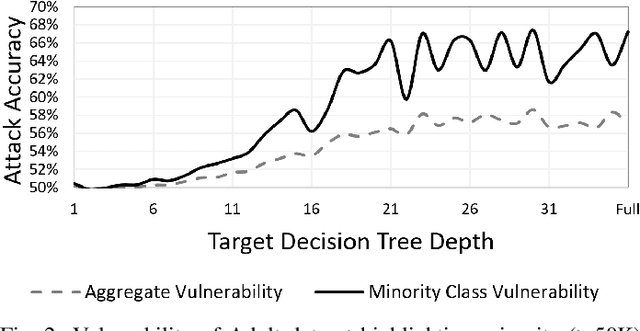
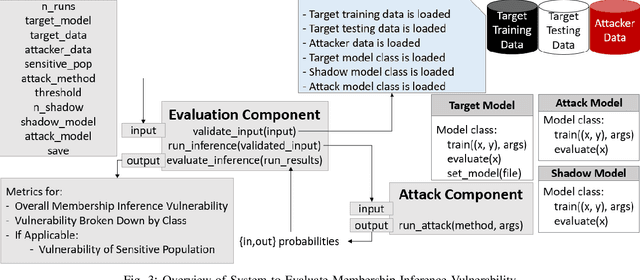
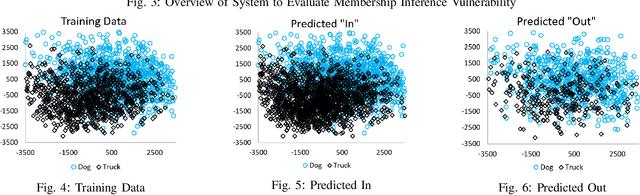
Membership inference attacks seek to infer the membership of individual training instances of a privately trained model. This paper presents a membership privacy analysis and evaluation system, called MPLens, with three unique contributions. First, through MPLens, we demonstrate how membership inference attack methods can be leveraged in adversarial machine learning. Second, through MPLens, we highlight how the vulnerability of pre-trained models under membership inference attack is not uniform across all classes, particularly when the training data itself is skewed. We show that risk from membership inference attacks is routinely increased when models use skewed training data. Finally, we investigate the effectiveness of differential privacy as a mitigation technique against membership inference attacks. We discuss the trade-offs of implementing such a mitigation strategy with respect to the model complexity, the learning task complexity, the dataset complexity and the privacy parameter settings. Our empirical results reveal that (1) minority groups within skewed datasets display increased risk for membership inference and (2) differential privacy presents many challenging trade-offs as a mitigation technique to membership inference risk.
Differentially Private Model Publishing for Deep Learning
May 05, 2019

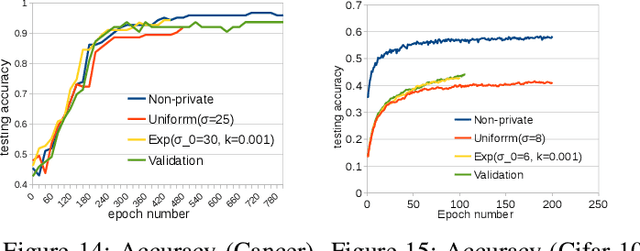
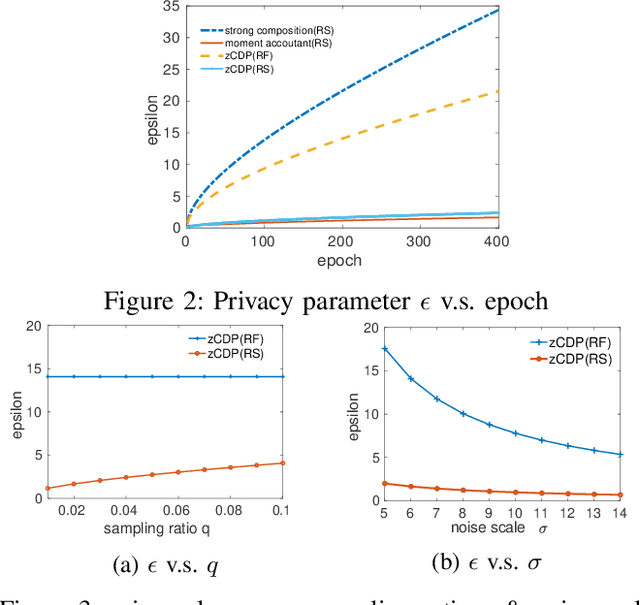
Deep learning techniques based on neural networks have shown significant success in a wide range of AI tasks. Large-scale training datasets are one of the critical factors for their success. However, when the training datasets are crowdsourced from individuals and contain sensitive information, the model parameters may encode private information and bear the risks of privacy leakage. The recent growing trend of the sharing and publishing of pre-trained models further aggravates such privacy risks. To tackle this problem, we propose a differentially private approach for training neural networks. Our approach includes several new techniques for optimizing both privacy loss and model accuracy. We employ a generalization of differential privacy called concentrated differential privacy(CDP), with both a formal and refined privacy loss analysis on two different data batching methods. We implement a dynamic privacy budget allocator over the course of training to improve model accuracy. Extensive experiments demonstrate that our approach effectively improves privacy loss accounting, training efficiency and model quality under a given privacy budget.
Adversarial Examples in Deep Learning: Characterization and Divergence
Oct 29, 2018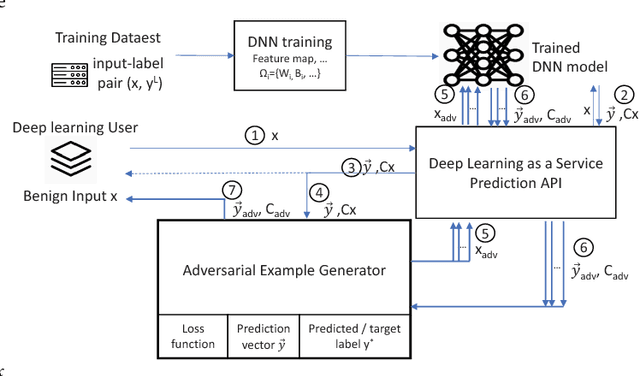

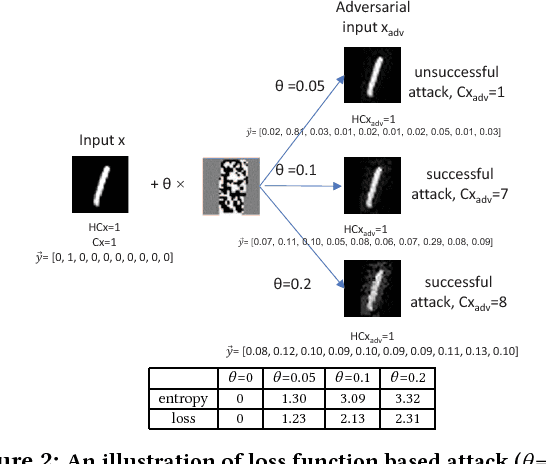
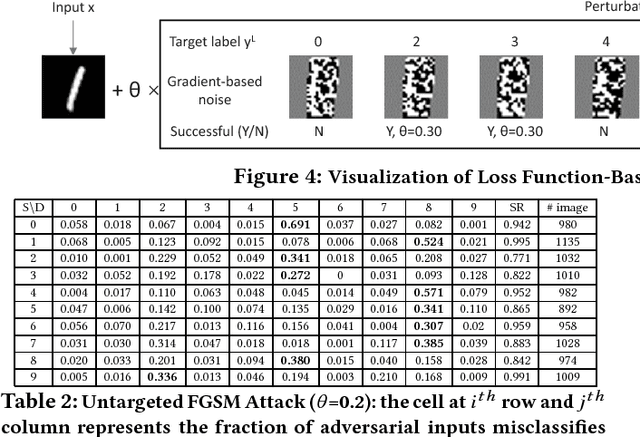
The burgeoning success of deep learning has raised the security and privacy concerns as more and more tasks are accompanied with sensitive data. Adversarial attacks in deep learning have emerged as one of the dominating security threat to a range of mission-critical deep learning systems and applications. This paper takes a holistic and principled approach to perform statistical characterization of adversarial examples in deep learning. We provide a general formulation of adversarial examples and elaborate on the basic principle for adversarial attack algorithm design. We introduce easy and hard categorization of adversarial attacks to analyze the effectiveness of adversarial examples in terms of attack success rate, degree of change in adversarial perturbation, average entropy of prediction qualities, and fraction of adversarial examples that lead to successful attacks. We conduct extensive experimental study on adversarial behavior in easy and hard attacks under deep learning models with different hyperparameters and different deep learning frameworks. We show that the same adversarial attack behaves differently under different hyperparameters and across different frameworks due to the different features learned under different deep learning model training process. Our statistical characterization with strong empirical evidence provides a transformative enlightenment on mitigation strategies towards effective countermeasures against present and future adversarial attacks.