 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Planning Feedback for Open-Ended Programming Exercises with LLMs
Apr 11, 2025To complete an open-ended programming exercise, students need to both plan a high-level solution and implement it using the appropriate syntax. However, these problems are often autograded on the correctness of the final submission through test cases, and students cannot get feedback on their planning process. Large language models (LLM) may be able to generate this feedback by detecting the overall code structure even for submissions with syntax errors. To this end, we propose an approach that detects which high-level goals and patterns (i.e. programming plans) exist in a student program with LLMs. We show that both the full GPT-4o model and a small variant (GPT-4o-mini) can detect these plans with remarkable accuracy, outperforming baselines inspired by conventional approaches to code analysis. We further show that the smaller, cost-effective variant (GPT-4o-mini) achieves results on par with state-of-the-art (GPT-4o) after fine-tuning, creating promising implications for smaller models for real-time grading. These smaller models can be incorporated into autograders for open-ended code-writing exercises to provide feedback for students' implicit planning skills, even when their program is syntactically incorrect. Furthermore, LLMs may be useful in providing feedback for problems in other domains where students start with a set of high-level solution steps and iteratively compute the output, such as math and physics problems.
Semantic Parsing of Interpage Relations
May 26, 2022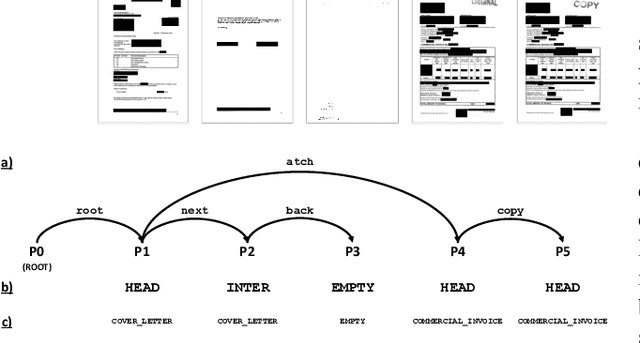

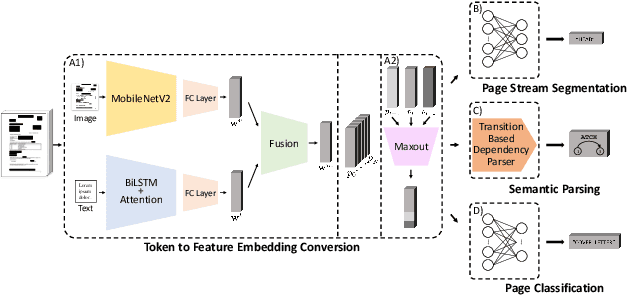
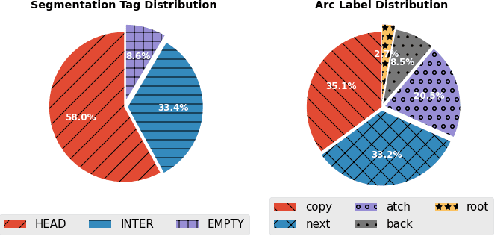
Page-level analysis of documents has been a topic of interest in digitization efforts, and multimodal approaches have been applied to both classification and page stream segmentation. In this work, we focus on capturing finer semantic relations between pages of a multi-page document. To this end, we formalize the task as semantic parsing of interpage relations and we propose an end-to-end approach for interpage dependency extraction, inspired by the dependency parsing literature. We further design a multi-task training approach to jointly optimize for page embeddings to be used in segmentation, classification, and parsing of the page dependencies using textual and visual features extracted from the pages. Moreover, we also combine the features from two modalities to obtain multimodal page embeddings. To the best of our knowledge, this is the first study to extract rich semantic interpage relations from multi-page documents. Our experimental results show that the proposed method increased LAS by 41 percentage points for semantic parsing, increased accuracy by 33 percentage points for page stream segmentation, and 45 percentage points for page classification over a naive baseline.
Predicting cognitive scores with graph neural networks through sample selection learning
Jun 17, 2021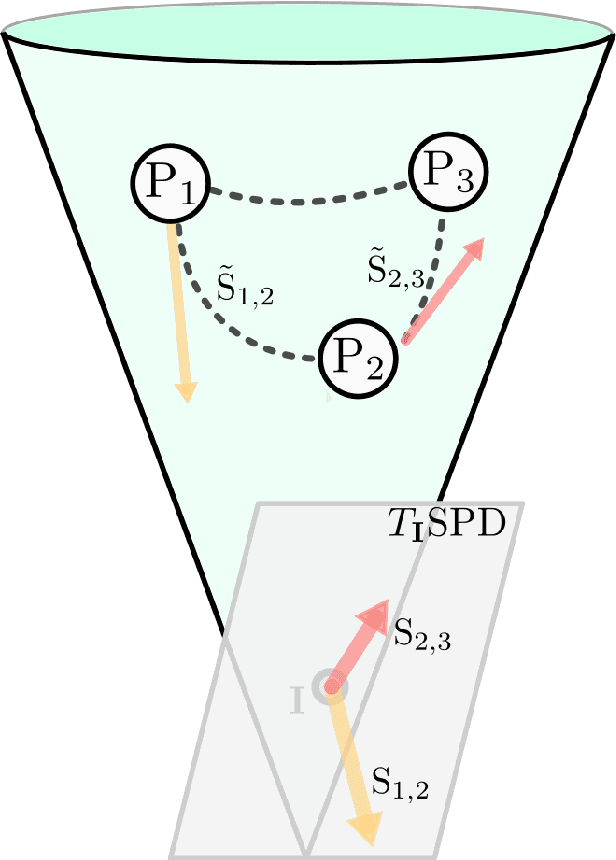
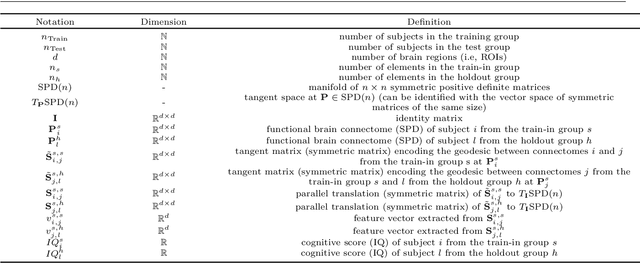
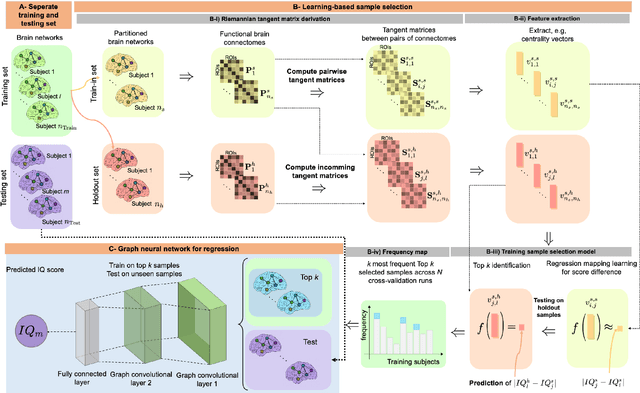
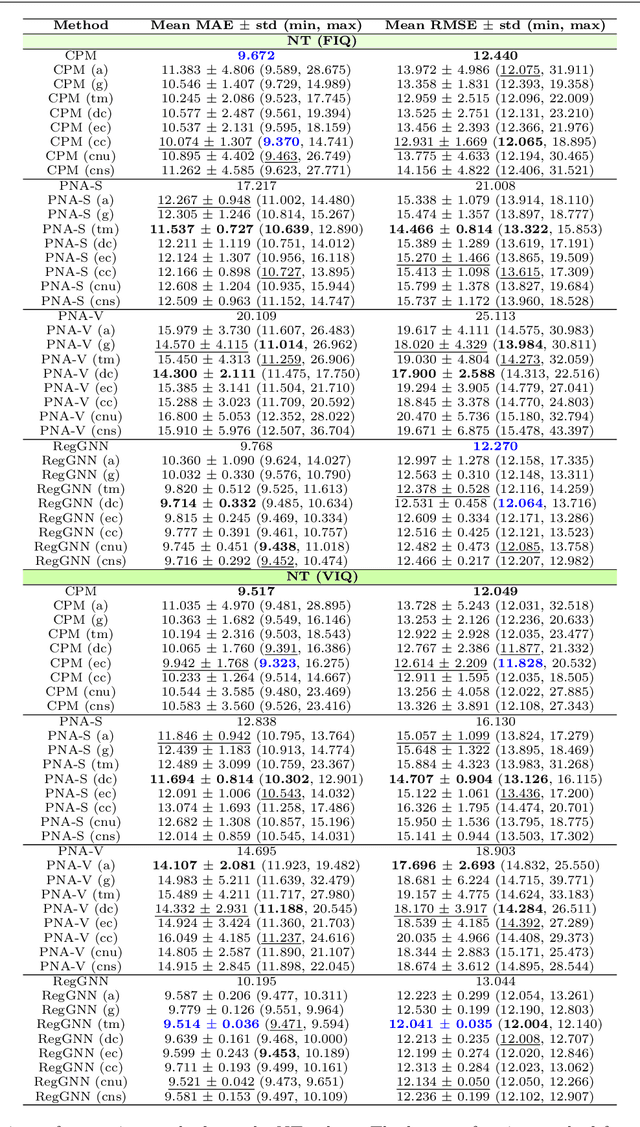
Analyzing the relation between intelligence and neural activity is of the utmost importance in understanding the working principles of the human brain in health and disease. In existing literature, functional brain connectomes have been used successfully to predict cognitive measures such as intelligence quotient (IQ) scores in both healthy and disordered cohorts using machine learning models. However, existing methods resort to flattening the brain connectome (i.e., graph) through vectorization which overlooks its topological properties. To address this limitation and inspired from the emerging graph neural networks (GNNs), we design a novel regression GNN model (namely RegGNN) for predicting IQ scores from brain connectivity. On top of that, we introduce a novel, fully modular sample selection method to select the best samples to learn from for our target prediction task. However, since such deep learning architectures are computationally expensive to train, we further propose a \emph{learning-based sample selection} method that learns how to choose the training samples with the highest expected predictive power on unseen samples. For this, we capitalize on the fact that connectomes (i.e., their adjacency matrices) lie in the symmetric positive definite (SPD) matrix cone. Our results on full-scale and verbal IQ prediction outperforms comparison methods in autism spectrum disorder cohorts and achieves a competitive performance for neurotypical subjects using 3-fold cross-validation. Furthermore, we show that our sample selection approach generalizes to other learning-based methods, which shows its usefulness beyond our GNN architecture.