 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Parsing of Interpage Relations
May 26, 2022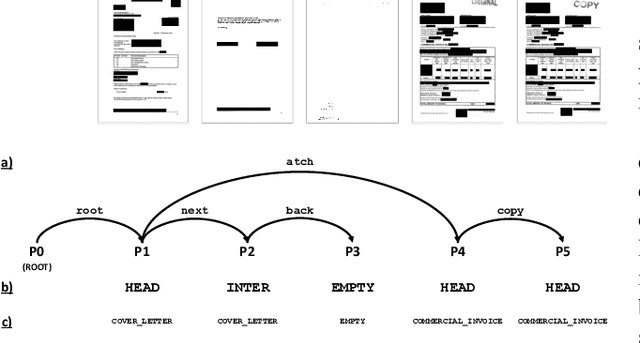

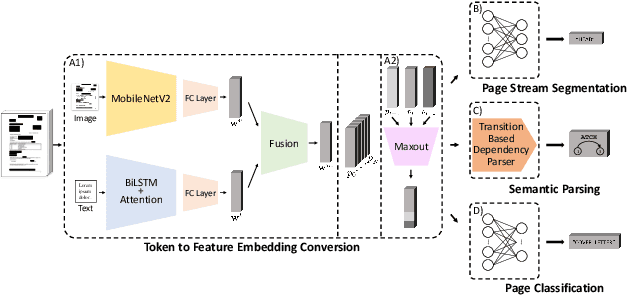
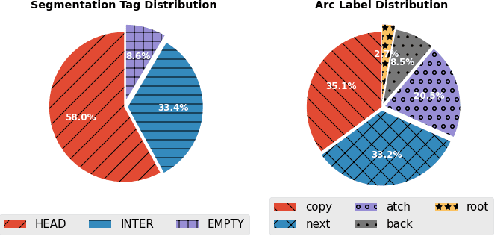
Page-level analysis of documents has been a topic of interest in digitization efforts, and multimodal approaches have been applied to both classification and page stream segmentation. In this work, we focus on capturing finer semantic relations between pages of a multi-page document. To this end, we formalize the task as semantic parsing of interpage relations and we propose an end-to-end approach for interpage dependency extraction, inspired by the dependency parsing literature. We further design a multi-task training approach to jointly optimize for page embeddings to be used in segmentation, classification, and parsing of the page dependencies using textual and visual features extracted from the pages. Moreover, we also combine the features from two modalities to obtain multimodal page embeddings. To the best of our knowledge, this is the first study to extract rich semantic interpage relations from multi-page documents. Our experimental results show that the proposed method increased LAS by 41 percentage points for semantic parsing, increased accuracy by 33 percentage points for page stream segmentation, and 45 percentage points for page classification over a naive baseline.